





---- 数据仓库和数据湖的初探 ----
数据湖概念图如下:
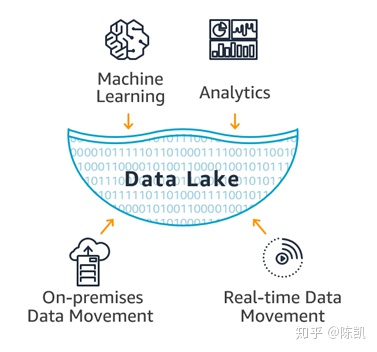
Pentaho的CTO James Dixon 在2011年提出了“Data Lake”的概念。在面对大数据挑战时,他声称:不要想着数据的“仓库”概念,想想数据 的“湖”概念。数据“仓库”概念和数据湖概念的重大区别是:数据仓库中数据在进入仓库之前需要是事先归类,以便于未来的分析。这在OLAP时代很常见,但是对于离线分析却没有任何意义,不如把大量的原始数据线保存下来,而现在廉价的存储提供了这个可能。
Nearly unlimited potential for operational insight and data discovery. As data volumes, data variety, and metadata richness grow, so does the benefit.
对比如下

存储那些缺陷:
- 无法支持ACID
- 无法完美解决多partition分区导致小文件问题
- 并发读写问题
- 有限的更新支“Update操作”
- 海量元数据(例如分区)导致Hive metastore不堪重负
- 表Schema动态拓展
其实 上述的每一个问题都能对应目前我们实际应用场景中,譬如有限的更新支持,无论是存储在hive还是spark本身,都是无法满足update操作,即便hive有"hive.compactor.initiator.on"支持部分更新也是非常局限和消耗资源的过程
很多时候我们会想着曲线救国的办法来解决我们的遇到的问题,例如通过中间表来读取旧数据和加入新数据在代码中进行合并操作之后覆盖原来的数据。此种不足不一一列举。
Delta Lake在存储层,解决了上面缺陷。
Delta Lake架构示示意图镇楼。
Delta Lake 官网delta.io
官网提供的Key Features

我们看到上述的特性中几个我们关心的点:
- ACID:俗称事务型交互
- Scalable Metadata Handling:可拓展的元数据管理
- Updates and Deletes:删除更新支持
- Schema Evolution:Schema自动管理
看到这里Delta Lake,带来的变革意义还是挺大的,解决的实际场景非常务实。其实上面很多操作我们还是看到很多传统数据库的影子的,俗话说存在即是合理的,传统数据库经历30多年积淀,一定有它存在和借鉴的意义的,譬如“事务”。
Delta Lake是什么?
先看看官网部署方式:GIT上maven/sbt部署教程。


从这里不是可以看出来其实Delta Lake只是一个Lib库。并不是一个Service。所以目前只支持Spark计算引擎部署,并不能单独部署。那么从常规存储结构看来,Delta Lake就是Spark的一个新特性,一种新的存储格式。可以将json、parquet、txt、delta等放在一个维度去横向比较。
看下Delta Lake底层实现:
Parquet文件 + Meta 文件 + 一组操作的API = Delta Lake.
那么是不是很好理解上面那句话,Delta Lake就是Spark一个存储格式,操作也完全兼容Spark DataSource,存储时候指定为txt、parquet、delta。其中上面官网的新特性比如支持ACID,更新,元数据之类都是一组操作的API中实现的。
Spark组合使用其他框架兼容考虑:
delta是否支持兼容Hive?
delta是否支持压缩存储?
关于第一个问题百度搜索很多都说没有,于是有点心可惜没支持hive。但是我在官网最新的版本中查看了下Delte Lake 0.5.0 Released:
Apache Hive to Delta Lake Integrationdocs.delta.io虽然只是支持查 Delta Lake 的数据,不支持 metastore。但是期待新版本不断迭代进来兼容metastore。
同时这个版本支持多种查询引擎查询 Delta Lake 的数据,例如presto。
关于第二个问题:delta Lake 中的所有数据都是使用 Apache Parquet 格式存储,使 Delta Lake 能够利用 Parquet 原生的高效压缩和编码方案。














 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









