





Airbnb公布的房源推荐算法解读
论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》是Airbnb公布的房源推荐算法
摘要:
召回策略:Airbnb的业务有很强的地域性,搜索区域字段被直接用于召回。
排序策略:采用了基于embedding的排序方法。作者比对了两种不同的构建Embedding的方法。一种是基于用户短期的两周的点击历史来构建的。另一种是基于用户长期的Booking历史来建构的,因为长期的Booking数据的稀疏性等等实际情况,作者首先做了聚合,然后再Embedding和排序。
原文摘要:搜索排名和建议是主要互联网公司(包括网络搜索引擎、内容发布网站和市场)切身利益的根本问题。但是,尽管共享一些共同特征,但此空间中不存在一刀切的解决方案。鉴于需要排名、个性化和推荐的内容存在巨大差异,每个市场都有一些独特的挑战。相应地,在Airbnb,一个短期租赁市场,搜索和推荐问题是相当独特的,是一个双面市场,其中一个人需要优化主机和客人的偏好,在一个用户很少使用同一项目两次,一个列表只能接受一个客人的一组日期。在本文中,我们描述了我们为搜索排名和类似列表建议的实时个性化目的开发和部署的列表和用户嵌入技术,这两个渠道推动了 99%的转化。嵌入模型是专门为Airbnb市场量身定制的,能够捕捉客人的短期和长期利益,提供有效的家居建议。我们对嵌入模型进行了严格的离线测试,然后进行了成功的在线测试,然后将其完全部署到生产中。
To be able to calculate similarities between listings that guest interacted with and candidate listings that need to be ranked we propose to use listing embeddings, low-dimensional vector representations learned from search sessions. We leverage these similarities to create personalization features for our Search Ranking Model and to power our Similar Listing Recommendations, the two platforms that drive 99% of bookings at Airbnb.
1. 基于用户长期的Booking历史来建构的embedding
具体场景
一个用户正在搜索洛杉矶的房源,他曾经订过纽约和伦敦的房源,给他推荐和他以前订过的房源相似的房源是有帮助的。
这种方法所面临着一些现实挑战
- 相比于点击行为,用户的历史消费行为很少。
- 有一些用户曾经只消费过一次,只有一个item的list没办法训练embedding。
- 通常5-10个item的list才能够训练出较好的embedding,但是多数用户并没有5-10次消费记录。
- 用户的历史消费记录可能有较长的时间跨度,用户的喜好会发生转变。
具体的embedding模型
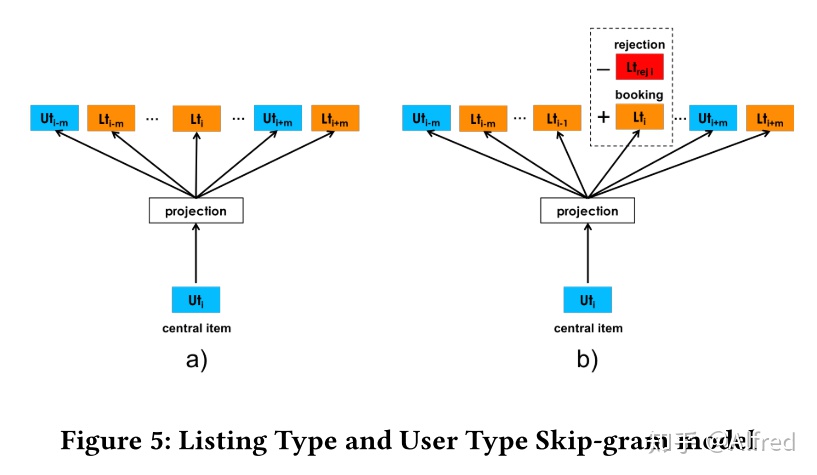
为解决上述问题,作者提出通过训练user_type和listing_type的embedding来取代user_id和listing_id的embedding。type是通过一系列人工规则来将不同的id映射到不同的type。
如下两张表所示,以用户为例,首先根据一些基本信息或历史消费信息,根据每一维度不同取值划分成不同的桶,不同用户就会落入到不同的桶中,再综合考虑所有维度,就得到了每个用户的类别,特别的,随着时间的拉近,不同时段的用户的类别可能不同,不同Listing的类别也可能不同。另外,一些只有基本信息可以利用的用户分到的类别还可以起到冷启动的作用。
文章通过规则映射的方式将用户和Listing划分成不同的类别,如下两张表所示,以用户为例,首先根据一些基本信息或历史消费信息,根据每一维度不同取值划分成不同的桶,不同用户就会落入到不同的桶中,再综合考虑所有维度,就得到了每个用户的类别,特别的,随着时间的拉近,不同时段的用户的类别可能不同,不同Listing的类别也可能不同。另外,一些只有基本信息可以利用的用户分到的类别还可以起到冷启动的作用。
排序示例


训练方法


2. 基于用户短期的两周的点击历史来构建的embedding
应用原始Skip-gram算法在Airbnb场景
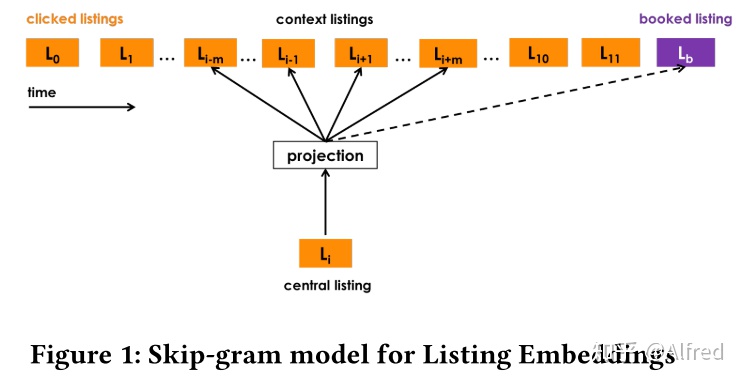
- 点击会话 (Session) ,每个会话s=(L1,…,Ln)∈S定义为一个由用户点击的 n 个房源 id 组成的的不间断序列。
- 只要用户连续两次点击之间的时间间隔超过30分钟,第二次点击会被认为是一个新的会话的开始。
- 目标是学习一个 32 维的实值表示方式 ,使相似房源在Embedding空间中处于临近的位置。
- 在每一步中,将中央房源的向量更新并将其推向正向相关房源的向量(用户在点击中心房源前后点击的其他房源,滑动窗口长度为m=5),并通过随机抽样房源的方式将它从负向相关房源推开(因为这些房源很大几率与中央房源没有关系)。
具体的embedding模型

训练方法
梯度下降的计算使用了 负采样的方法 Negative sampling approach

加入额外的Booking信息
最初的版本是上图中橙色的部分,用户的点击序列可以分为两类,以预定为结尾的和只有点击没有预定,为了让embedding的构造不仅体现出相邻上下文的相似关系,也能体现出最后的预定信息,可以对以预定为结尾的序列,将预定的Listing作为全局的上下文,每次窗口滑动时都作为正例参与训练,即每次训练都加上图中紫色的Listing,有点类似于doc2vec中的设置,目标函数的最后一项体现了这一点。
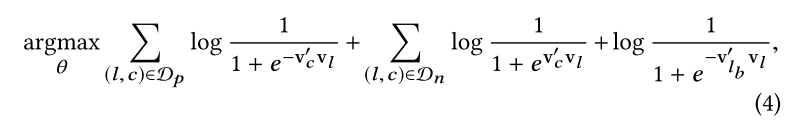
加入额外的搜索区域的负例
订房的搜索结果通常限制在某一个市场区域中,就容易导致正例集合Dp中包含的Listing都来自同一个市场区域,而反例由于随机采样包含各个市场区域,这样就导致同一个市场的Listing的embedding训练不充分,所以文章又增加了一些搜索区域的负例,用集合Dmn表示,在目标函数上的体现如下:
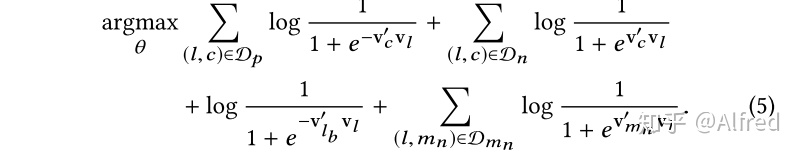
示例
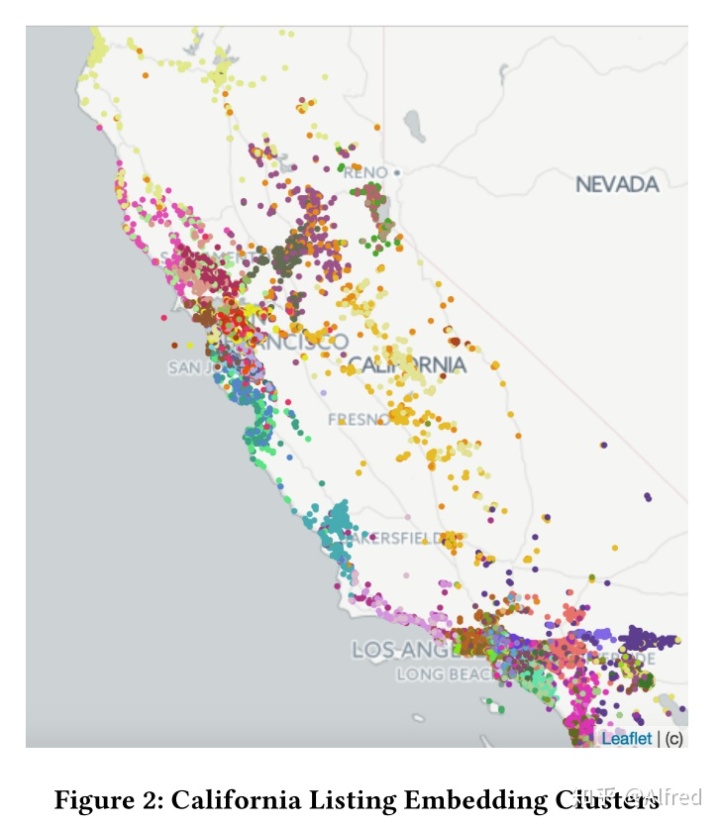
在已学的嵌入上执行 k 均值聚类,我们评估地理相似性是否被有效的学习了。图 2 显示了加利福尼亚州的 100 个群集,它确认来自类似位置的列表聚集在一起。
结论
作者在两种embedding的方案上都做了大量优化,最终embedding的聚类效果明显有效。
Airbnb实际上线的效果来看,基于用户长期的Booking历史来建构的embedding的排序的效果好于基于用户短期的两周的点击历史来构建embedding的排序。

Reference
https://astro.temple.edu/~tua95067/kdd2018.pdf
https://www.airbnb.com
https://medium.com/syncedreview/kdd-2018-announces-best-paper-other-awards-4835ab8475a4















 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









