





目录
内存映射
进程如何访问内存?
进程的用户态和内核态
什么是内存映射?
什么是缺页异常
MMU 如何管理内存
多级页表和大页
虚拟内存空间分布
内存分配与回收
如何查看内存使用情况
问题:如何统计所有进程的物理内存使用量?
内存管理也是操作系统最核心的功能之一。内存主要用来存储系统和应用程序的指令、数据、缓存等
内存映射
我们通常所说的内存容量指的是物理内存。物理内存也称为主存,大多数计算机用的主存都是动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。
进程如何访问内存?
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。进程访问内存其实访问的虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间
不同字长(也就是单个CPU指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和 64 位系统
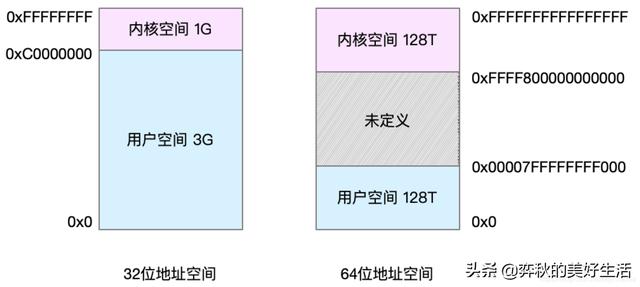
- 32位系统的内核空间占用 1G,位于最高处,剩下的3G是用户空间。
- 64位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的
进程的用户态和内核态
进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存
虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
什么是内存映射?
其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。
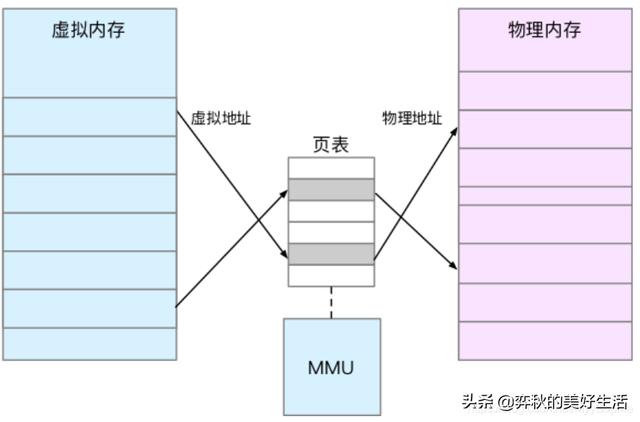
页表实际上存储在 CPU 的内存管理单元 MMU中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
什么是缺页异常
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
TLB(Translation Lookaside Buffer,转译后备缓冲器)会影响 CPU 的内存访问性能,TLB 其实就是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少TLB的刷新次数,就可以提高TLB 缓存的使用率,进而提高CPU的内存访问性能。
CPU首先得到的是虚拟地址,必须将虚拟地址转换为物理地址才能进行数据访问。这个过程先查TLB,若TLB命中,则得到了物理地址,进行步骤2;否则,继续查找主存中的页表。若仍不命中,则引发缺页中断进行调页。调页过程又可能引发驻留集页替换和页回写过程。 2.得到物理地址之后,首先访问cache,若命中,CPU直接从cache中读取相应物理地址中的内容;若不命中,则访问主存读取数据,并且更新cache,此过程又可能引发cache的行替换和回写过程。MMU全称就是内存管理单元,管理地址映射关系(也就是页表)。但MMU的性能跟CPU比还是不够快,所以又有了TLB。TLB实际上是MMU的一部分,把页表缓存起来以提升性能。
MMU 如何管理内存
MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
多级页表和大页
页的大小只有4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)
- 多级页表
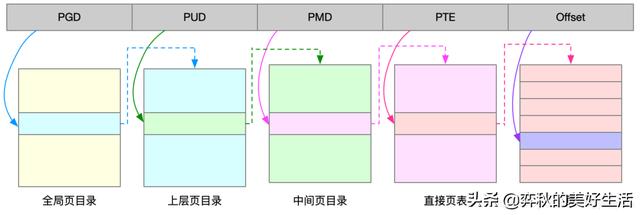
把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。
Linux 用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为5个部分,前4个表项用于选择页,而最后一个索引表示页内偏移。
- 大页
比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等。GP是否可以也使用大页呢?
虚拟内存空间分布
在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。那么具体到一个Linux 进程中,这些内存又是怎么使用的呢?
3.1 虚拟内存空间的分布情况
以32位系统为例
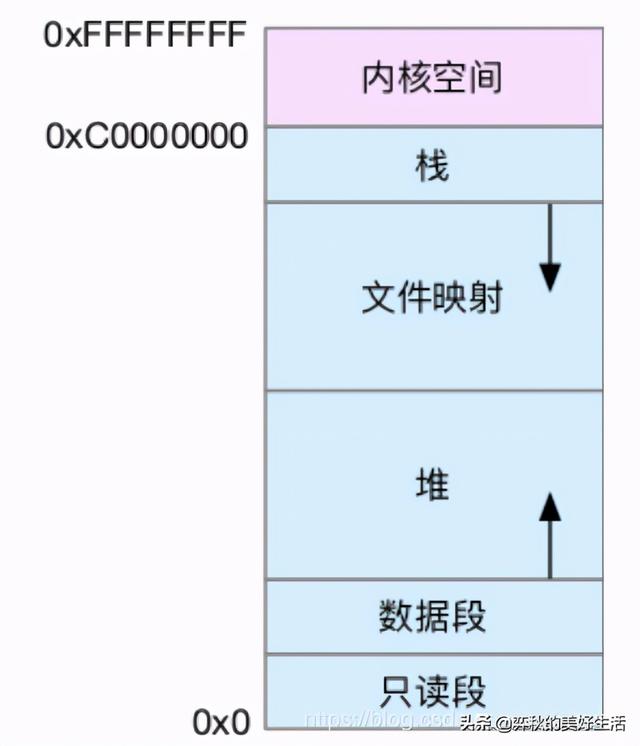
1. 只读段,包括代码和常量等。
2. 数据段,包括全局变量等。
3. 堆,包括动态分配的内存,从低地址开始向上增长。
4. 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
5. 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc()或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。64位系统的内存分布也类似,只不过内存空间要大得多。
内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和mmap()。对小块内存(小于128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块
空闲内存分配出去。
这两种方式,自然各有优缺点。
- brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
- mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是malloc 只对大块内存使用 mmap 的原因。如果太小的内存也使用mmap分配内核的管理负担会更大。
来个例子理解一下
servers]# strace cat /dev/null execve("/bin/cat", ["cat", "/dev/null"], [/* 29 vars */]) = 0brk(0) = 0x1e0d000mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f42ef607000access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)open("/etc/ld.so.cache", O_RDONLY) = 3fstat(3, {st_mode=S_IFREG|0644, st_size=77682, ...}) = 0mmap(NULL, 77682, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f42ef5f4000close(3) = 0open("/lib64/libc.so.6", O_RDONLY) = 3read(3, "177ELF21130000000030>01000p3563412323000"..., 832) = 832fstat(3, {st_mode=S_IFREG|0755, st_size=1926760, ...}) = 0mmap(0x339ae00000, 3750152, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x339ae00000mprotect(0x339af8a000, 2097152, PROT_NONE) = 0mmap(0x339b18a000, 20480, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x18a000) = 0x339b18a000mmap(0x339b18f000, 18696, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x339b18f000close(3) = 0mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f42ef5f3000mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f42ef5f2000mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f42ef5f1000arch_prctl(ARCH_SET_FS, 0x7f42ef5f2700) = 0mprotect(0x339b18a000, 16384, PROT_READ) = 0mprotect(0x339a81f000, 4096, PROT_READ) = 0munmap(0x7f42ef5f4000, 77682) = 0brk(0) = 0x1e0d000brk(0x1e2e000) = 0x1e2e000open("/usr/lib/locale/locale-archive", O_RDONLY) = 3fstat(3, {st_mode=S_IFREG|0644, st_size=99158576, ...}) = 0mmap(NULL, 99158576, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f42e9760000close(3) = 0fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 4), ...}) = 0open("/dev/null", O_RDONLY) = 3fstat(3, {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 3), ...}) = 0read(3, "", 32768) = 0close(3) = 0close(1) = 0close(2) = 0exit_group(0) = ?当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在MMU中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如brk方式造成的内存碎片)
比页(4KB)还小的内存如何分配?
如果为它们也分配单独的页,那就太浪费内存了
所以
- 在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。
- 在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。(malloc本身不会使用slab只有内核中使用kmalloc才回通过slab分配内存) 因此需要注意对于内核空间才会用slab 分配内存
对内存来说,如果只分配而不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完内存后,还需要调用 free() 或 unmap() ,来释放这些不用的内存。
内存紧张时触发内存回收机制
- 回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。
Swap 把系统的可用内存变大了。不过要注意,通常只在内存不足时,才会发生 Swap 交换。并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题
- 杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程
OOM killer是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
- 一个进程消耗的内存越大,oom_score 就越大;
- 一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj ,从而调整进程的 oom_score。oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM。
echo -16 > /proc/$(pidof watch)/oom_adj如何查看内存使用情况
free
第一列,total 是总内存大小;
第二列,used 是已使用内存的大小,包含了共享内存;
第三列,free 是未使用内存的大小;
第四列,shared 是共享内存的大小;
第五列,buff/cache 是缓存和缓冲区的大小;
top
主要列含义:
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
%MEM 是进程使用物理内存占系统总内存的百分比。
第一,虚拟内存通常并不会全部分配物理内存。
第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
问题:如何统计所有进程的物理内存使用量?
The “proportional set size” (PSS) of a process is the count of pagesit has in memory, where each page is divided by the number ofprocesses sharing it. So if a process has 1000 pages all to itself, and1000 shared with one other process, its PSS will be 1500.每个进程的 PSS ,是指把共享内存平分到各个进程后,再加上进程本身的非共享内存大小的和。就像文档中的这个例子,一个进程的非共享内存为 1000 页,它和另一个进程的共享进程也是 1000 页,那么它的 PSS=1000/2+1000=1500 页。这样,你就可以直接累加 PSS ,不用担心共享内存重复计算的问题了。
grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB", total }'













 2844
2844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









