









人脸识别综述
人脸识别是图像分析与理解最重要的应用之一,所谓人脸识别,就是利用计算机分析人脸视频或者图像,并从中提取出有效的识别信息,最终判别人脸对象的身份。人脸识别的研究可以追溯到20世纪 60年代末期,主要的思路是设计特征提取器,再利用机器学习的算法进行分类。2012深度学习引入人脸识别领域后,特征提取转由神经网络完成,深度学习在人脸识别上取得了巨大的成功。下面以时间为顺序,梳理下人脸识别各算法的发展历程。
一、传统算法
(一)基于几何特征
1、原理
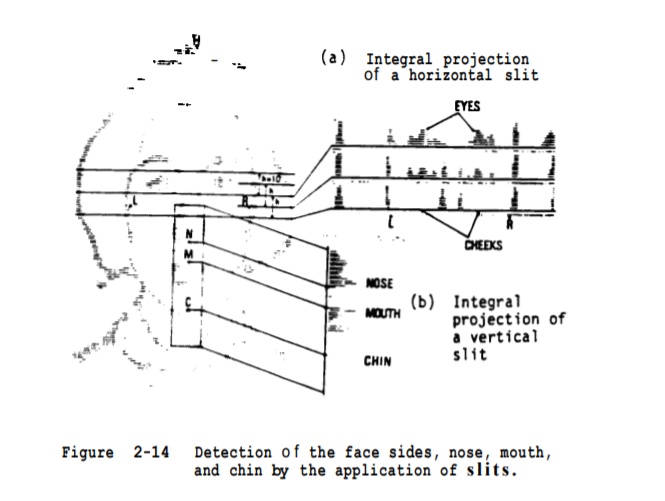
人脸由眼睛、鼻子、嘴巴、下巴等部件构成,这些部件的形状、大小,以及各部件在脸上的分布各异,构成各种各样的人脸,利用这些部件的形状和结构关系的几何描述,做为人脸识别的特征。比如:眼角点、鼻尖点和两个嘴角点,构造若干特征向量。特征向量通常包括人脸指定两点间的距离、曲率、角度等。
1973年,Kelly’s and Kanade’s PhD theses,第一篇人脸识别的paper,
2、优缺点
(1)优点
算法识别速度快,需要的内存小。
(2)缺点
一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求。
(二)基于全局信息(holistic method)
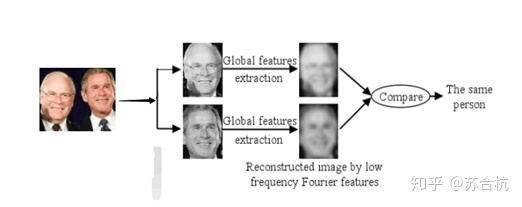
基于几何特征的方法,萃取人脸部件的轮廓和几何关系,并没有用到图片中的其他信息,为了提高识别准确度,全局算法应运而生,全局算法的特征向量,包含人脸图像上所有部分的信息。
按照对全局特征处理方法的不同,介绍下面两种方法
1、PCA(Principal Components Analysis)
a.提出背景:
照片的识别,可以看成特征向量相互匹配的过程。如果2张100*100的照片,在各个维度上都相近,那么我们可以认为,这两张照片属于同一个人。但是以100 * 100的照片为例,数据维度10000维,数据维度太高,计算机处理复杂度高,需要将维度降低(因为10000维里面数据之间存在相关关系,所以可以除去重复维度信息,而保持信息不丢失)
b.降维方法
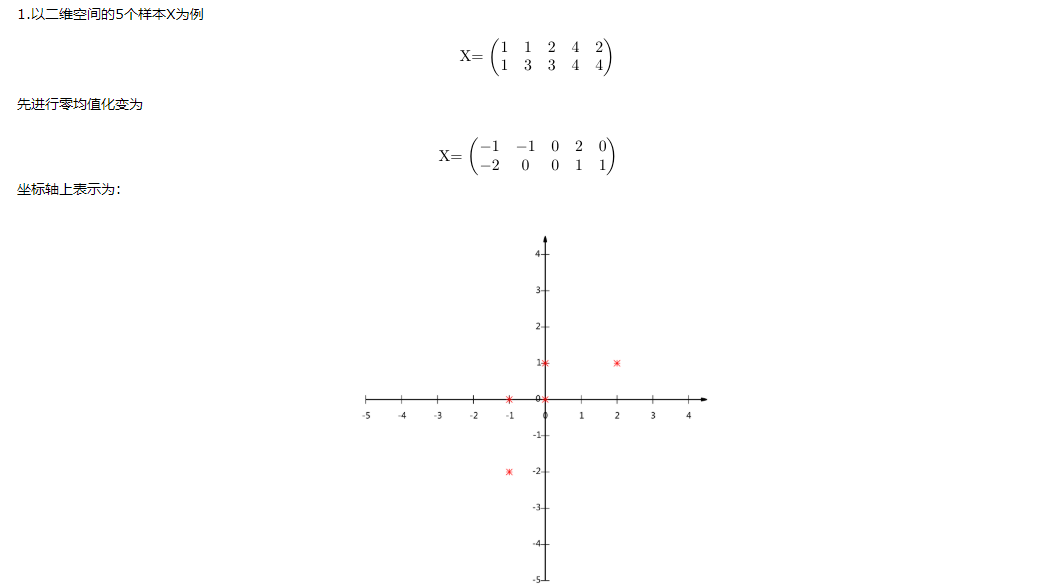


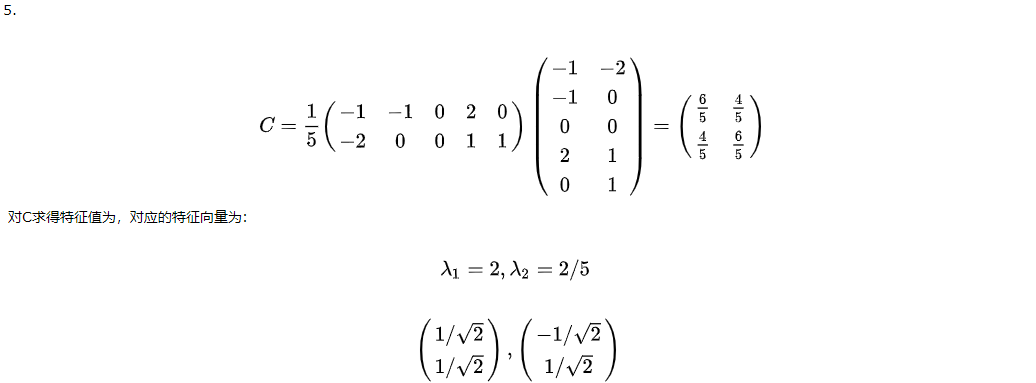
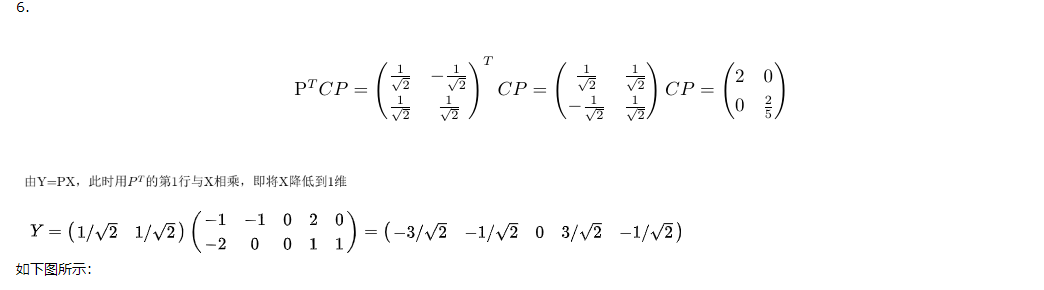
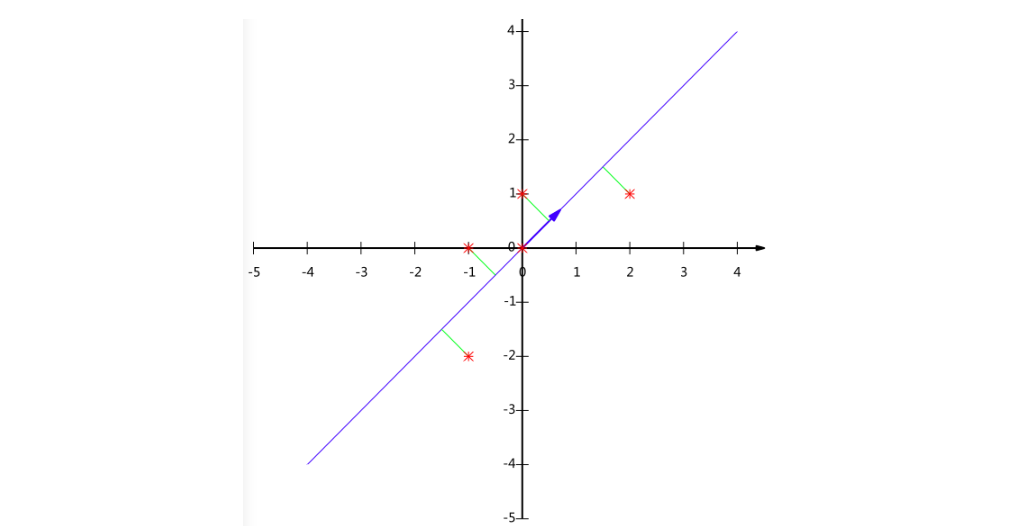
降低维度后,再拿这个压缩过的向量做识别即可。典型的方法有egienface等。

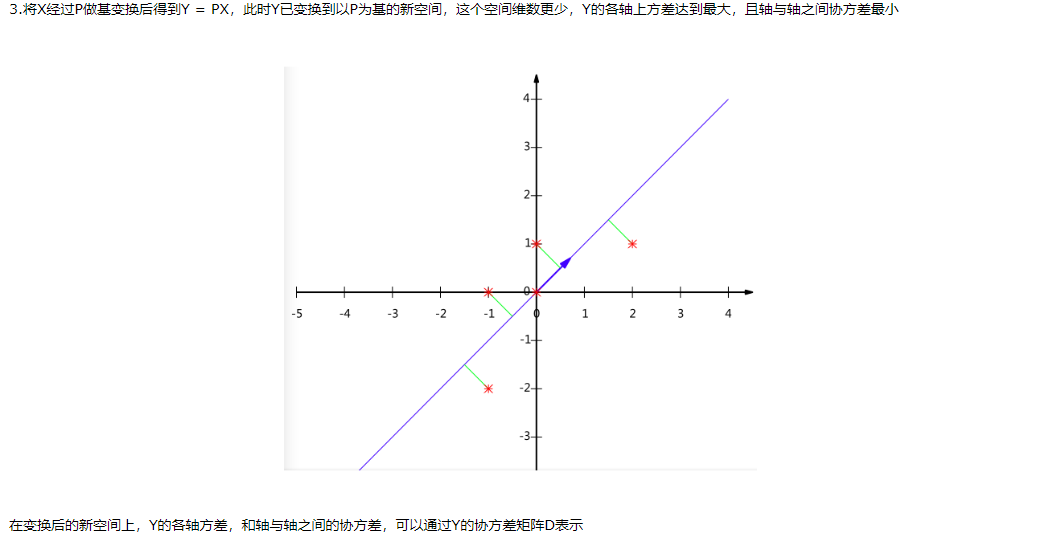
PCA所作的是将数据映射到最方便表示这组数据的坐标系上,映射时没有利用任何数据分类信息。做PCA其实是在信息损失尽可能低的情况下,将数据降维。如果在降维的时候加入分类信息,效果会不会更好?
2、LDA(Linear Discriminant Analysis线性判别分析)
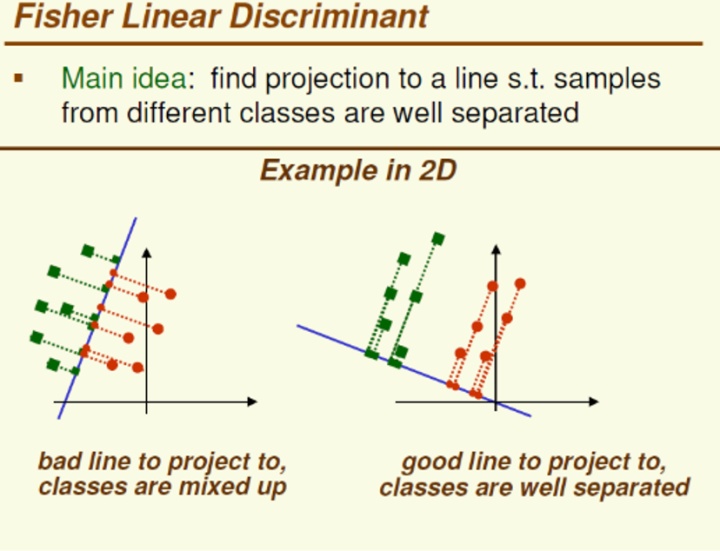
左图是PCA,它所作的只是将数据映射到,最方便表示这组数据的坐标轴上。分类效果可能一般。
右图是LDA,可以明显看出,在增加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就可以区分,减少了很大的运算量)。
LDA的典型方法有Fisher Linear Discriminant等,它求一个线性变换,使样本数据中“between classes scatter matrix”(类间协方差矩阵)和“within classes scatter matrix”(同内协方差矩阵)之比的达到最大。
(三)基于局部信息
基于局部信息的的提取方法也叫Feature-based method。我们考虑一种情况,同一个人的2张照片,它们之间唯一的区别是其中一人的眼睛是闭着的。在整体方法中,所有的特征向量的都可能不同(每一个特征向量都能看到全图信息)。但在在基于特征的方法中,大部分特征保持不变,只有与眼睛周围提取的特征向量会不同。而且,我们可以在基于特征方法中,将描述符设计为对变化(例如缩放、旋转或平移)保持不变。使其鲁棒性更强。
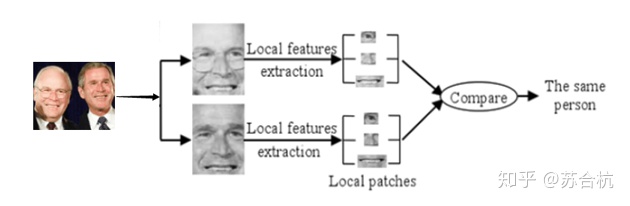
基于局部信息的典型算法是LBP(Local Binary Pattern,局部二值模式),由芬兰的T. Ojala, M.Pietikäinen, 和 D. Harwood 在1994年提出,用于图像的局部纹理特征提取。
1、原理
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









