





【第一部分】
Python中的 * 和 ** ,能够让函数支持任意数量的参数,它们在函数定义和调用中,有着不同的目的!
一. 打包参数
* 的作用:在函数定义中,收集所有位置参数到一个新的元组,并将整个元组赋值给变量args>>> def f(*args): # * 在函数定义中使用
print(args)>>> f()()>>> f(1)(1,)>>> f(1, 2, 3, 4)(1, 2, 3, 4)
** 的作用:在函数定义中,收集关键字参数到一个新的字典,并将整个字典赋值给变量kwargs>>> def f(**kwargs): # ** 在函数定义中使用
print(kwargs)>>> f(){}>>> f(a=1, b=2){'a': 1, 'b': 2}
二. 解包参数
* 的作用:在函数调用中,* 能够将元组或列表解包成不同的参数>>> def func(a, b, c, d):
print(a, b, c, d)
>>> args = (1, 2, 3, 4)
>>> func(*args) # * 在函数调用中使用
1 2 3 4
>>> args = [1, 2, 3, 4]
>>> func(*args)
1 2 3 4
** 的作用:在函数调用中,** 会以键/值的形式解包一个字典,使其成为一个独立的关键字参数>>> def func(a, b, c, d):
print(a, b, c, d)
>>> kwargs = {"a": 1, "b": 2, "c": 3, "d": 4}
>>> func(**kwargs) # ** 在函数调用中使用
1 2 3 4
三. 注意
1. 在函数定义时, * 表示打包;在函数体内部, * 表示的却是解包,事实上,下面例子中print(*args)是print()函数的调用>>> def foo(*args, **kwargs):
print(args) #未解包参数
print(*args) #解包参数
>>> v = (1, 2, 4)
>>> d = {'a':1, 'b':12}
>>> foo(v, d)
((1, 2, 4), {'a': 1, 'b': 12})
(1, 2, 4) {'a': 1, 'b': 12}
2. * 和 ** 的打包和解包并不能脱离函数而存在
如下的例子中,表面上看没有调用什么函数,实际上调用了format()函数>>> c = {"name": 'zhang', "age": 2}
>>> **cSyntaxError: invalid syntax
>>> "Name:{name}, Age:{age}".format(**c)'Name:zhang, Age:2'
参考源码中对format函数的定义
这里为什么不用print()函数而用format()呢
可以试试print()函数来解包>>> print(**c)
Traceback (most recent call last): File "", line 1, in
print(**c)TypeError: 'age' is an invalid keyword argument for this function
因为print()函数只支持 *args,不支持 **kwargs!
更多详细信息具体参见博客:
【第二部分】
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
应用:在深度学习的Dropout正则化方法中,可以用于生成dropout随机向量(dl),例如(keep_prob表示保留神经元的比例):dl = np.random.rand(al.shape[0],al.shape[1])!
np.random.randn()函数
np.random.randn(d0,d1,d2……dn)
语法:
1) 当函数括号内没有参数时,则返回一个浮点数;
2)当函数括号内有一个参数时,则返回秩为1的数组,不能表示向量和矩阵;
3)当函数括号内有两个及以上参数时,则返回对应维度的数组,能表示向量或矩阵;
4)np.random.standard_normal()函数与np.random.randn()类似,但是np.random.standard_normal()
的输入参数为元组(tuple).
5)np.random.randn()的输入通常为整数,但是如果为浮点数,则会自动直接截断转换为整数。
作用:
通过本函数可以返回一个或一组服从标准正态分布的随机样本值。
特点:
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。对应的正态分布曲线如下所示,即
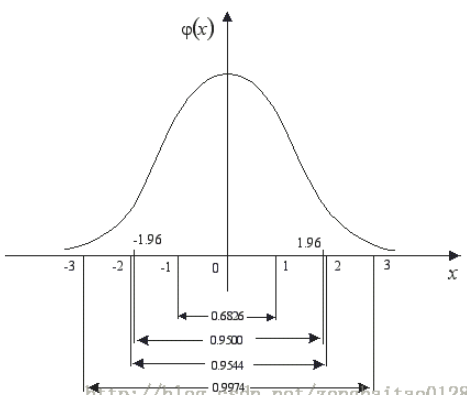
标准正态分布曲线下面积分布规律是:
在-1.96~+1.96范围内曲线下的面积等于0.9500(即取值在这个范围的概率为95%),在-2.58~+2.58范围内曲线下面积为0.9900(即取值在这个范围的概率为99%).
因此,由 np.random.randn()函数所产生的随机样本基本上取值主要在-1.96~+1.96之间,当然也不排除存在较大值的情形,只是概率较小而已。
numpy.random.uniform()
1. 函数原型: numpy.random.uniform(low,high,size)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出m*n*k个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。这里顺便说下ndarray类型,表示一个N维数组对象,其有一个shape(表维度大小)和dtype(说明数组数据类型的对象),使用zeros和ones函数可以创建数据全0或全1的数组,原型:
numpy.ones(shape,dtype=None,order='C'),
其中,shape表数组形状(m*n),dtype表类型,order表是以C还是fortran形式存放数据。
2. 类似uniform,还有以下随机数产生函数:
a. randint: 原型:numpy.random.randint(low, high=None, size=None, dtype='l'),产生随机整数;
b. random_integers: 原型: numpy.random.random_integers(low, high=None, size=None),在闭区间上产生随机整数;
c. random_sample: 原型: numpy.random.random_sample(size=None),在[0.0,1.0)上随机采样;
d. random: 原型: numpy.random.random(size=None),和random_sample一样,是random_sample的别名;
e. rand: 原型: numpy.random.rand(d0, d1, ..., dn),产生d0 - d1 - ... - dn形状的在[0,1)上均匀分布的float型数。
f. randn: 原型:numpy.random.randn(d0,d1,...,dn),产生d0 - d1 - ... - dn形状的标准正态分布的float型数。
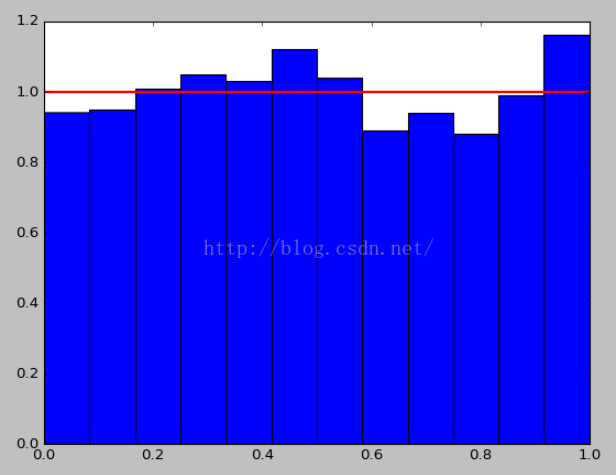
Example code:
import matplotlib.pyplot as plt
import numpy as np
s = np.random.uniform(0,1,1000) # 产生1200个[0,1)的数
count, bins, ignored = plt.hist(s, 10, normed=True)
"""
hist原型:
matplotlib.pyplot.hist(x, bins=10, range=None, normed=False, weights=None,
cumulative=False, bottom=None, histtype='bar', align='mid',
orientation='vertical',rwidth=None, log=False, color=None, label=None,
stacked=False, hold=None,data=None,**kwargs)
输入参数很多,具体查看matplotlib.org,本例中用到3个参数,分别表示:s数据源,bins=12表示bin
的个数,即画多少条条状图,normed表示是否归一化,每条条状图y坐标为n/(len(x)`dbin),整个条状图积分值为1
输出:count表示数组,长度为bins,里面保存的是每个条状图的纵坐标值
bins:数组,长度为bins+1,里面保存的是所有条状图的横坐标,即边缘位置
ignored: patches,即附加参数,列表或列表的列表,本例中没有用到。
"""
plt.plot(bins, np.ones_like(bins), linewidth=2, color='r')
plt.show()
点滴分享,福泽你我!Add oil!
转载本文请联系原作者获取授权,同时请注明本文来自张伟科学网博客。
链接地址:http://blog.sciencenet.cn/blog-3428464-1247727.html
上一篇:[转载]理解权重衰减(weight decay)和学习率衰减(learning rate decay)及Dropout
下一篇:Python绘图函数add_subplot 、 subplots_adjust、imshow及画图流程和弹窗设置















 2426
2426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









