






数据库的性能优化是个非常复杂的事情,熟悉Oracle的专家能手更是数不胜数,所以写了数十篇文章都没敢写过Oracle。直到最近,单位请来了Oracle原厂培训,请Oracle大师来给新入职的同学做培训,作为张罗这事的参与者之一,笔者也跟着听了一天,竟然发现大师有几个地方讲错了,主要是在理论联系实际的问题分析、AWR报告解读方面,提问之后竟然把大师挂在了台上。后来想想,大师也有不懂的,我怕什么呢,写!从性能测试的角度看Oracle,我们换个视角。
一个业务的响应时间受到这个业务所以环节性能的影响,如果被测系统涉及到数据库,则需要对数据库指标进行监控。这里的数据库指标并不是服务器本身的CPU、内存、IO等指标(当然,这些指标也是要监控的),而是指从数据库角度来看的指标,例如Buffer命中率、SQL执行时间等,本文介绍Oracle数据库的指标。
数据库的指标千千万,一般来说,会重点关注一些指标,这里就介绍一下作为测试人员需要关注的指标。
关注指标之前,需要做的是关注Oracle系统的告警(例如:表空间满了)。只有告警消除后,各类指标才是正常状态下的指标。
查看Oracle性能指标的方法有不少,本文主要以AWR报告为目标做介绍。自动工作量存储(Automatic Workload Repository AWR)是随着数据库一起被安装的,它不仅能收集统计数据,还能从统计数据中分析出度量数据,后续会详细介绍AWR,本文主要介绍指标本身的概念。
SQL语句执行时间、吞吐量
数据库的用户是应用,应用使用数据库来执行SQL语句。SQL语句的执行时间最能反映满意用户需要的能力。当一个应用处理速度比较慢的时候,自然会查看数据库的SQL执行时间。
一个数据库有千千万个指标,其他指标即使异常到令人发指,只要用户满意,往往也没有人去刻意做调优。
执行时间:
在AWR>Main Report>SQL Statistics目录下,可以看到如下SQL语句执行时间的分目录。

如果应用程序比较慢,并且比较怀疑是数据库的原因,那么关注一下排在前几位的SQL语句。作为初次观察,关注SQL ordered by Elapsed Time,这个指标是按照整个SQL的执行时间来排序的,以下图为例:
这里有SQL语句的名称、执行次数(Executions)和每次的执行时间(Elapsed Time per Exec(s))。如果这个执行时间比预想的要长,那么需要查看一下这个语句的执行计划。
吞吐量:
执行次数除以总时间(两个AWR快照之间的时间)就是这条SQL的吞吐量,吞吐量同样是比较重要的指标。SQL吞吐量无法根据业务压力而增长说明单条SQL的执行效率有问题或者系统的并发有问题(应用、中间件、数据库等环节均可能有并发的问题)
另外,%Total、%CPU、%IO这些指标一定要注意这个分目录的具体解释,因为每个分目录下的解释不一定一样,并且,这些指标可能和你大脑中想象的含义也不一样。

我看了解释以后发现和我的第一想象是不一样的。在看指标的时候,千万不要根据自己的猜测、经验来看,一定要查阅各个系统、各个产品自身对该指标的定义。
这里再多说几句,我们个人会对Oracle的一些指标有误解,那么Oracle作为一个产品也会对其他产品有误解。例如,AWR报告的开头部分:

这一段是Oracle对自身所处的系统环境信息做一个抓取,系统共18个核,72个逻辑CPU,但这个系统不一定有18个核的能力,还得具体查看环境是不是虚拟化平台,如果是,那么这18个核是虚拟的核,而真正能得到的CPU能力可能小于18。
Top等待
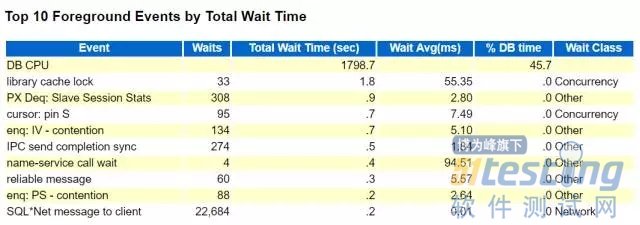
如果觉得数据库有性能问题,那么最先查看的就是Top等待事件。

看看哪个事件的Total Wait Time最大,就重点解决哪个事件。DB CPU如果最大一般是正常的,需继续关注DB CPU之外的事件。
等待事件五花八门,遇到没见过的可以网上查查,但看懂网上查来的结果也是需要些数据库的知识了,此处不是一朝一夕的花架子。
举一个性能测试中常见的例子,测试环境或者是刚刚搭建的生产环境常常是Oracle的默认参数,没有经过调整,log switch占到了Top等待事件的前面。
日志切换(Log switch)为什么等待时间这么多呢?首先就要了解日志、日志组是干什么,日志为什么要切换,什么情况下切不过去。
Redo日志组假如初始是2个日志,每个日志10M大小,分别记为A和B。当A写满的时候,就要switch到B去写日志,这时候就发生了日志切换。此时,可能1)如果开启了日志归档,需要将A写到归档日志里面。如果B这时候也写满了,就要再次switch回A。如果A还没有归档完成,那么就需要切换等待。可能2)A里面的内容还没有完成提交,B也不能把A的日志冲掉,此时产生了切换等待。
了解清楚之后,在不改变应用程序的情况下,可以通过增加单个日志大小(减少切换次数)、增加日志组个数(减少切换时可能的等待)来解决。比如日志大小从10M改为1G,日志从2个改为4个。
Instance Efficiency Percentages
这个分类下面大部分是Buffer命中率。命中率在数据库中是至关重要的,命中率的高低直接影响了数据库的性能。
介绍几个经常关注的指标
Buffer Nowait >99
在缓冲区中获取buffer 的未等待比率, 一旦此数据较低说明数据库存在大量出现buffer busy waits。
Buffer Hit >95
数据块在数据缓冲区中的命中率,通常应该在95%以上,否则考虑加大db_cache_size。当然,命中率低也不一定是cache小,也可能SQL写的烂、执行计划不当等原因。
Library Hit >95
代表着SQL在共享区的命中率,通常在95%以上。
当你发出一条SQL语句交付Oracle,在执行和获取结果前,Oracle对此SQL将进行几个步骤的处理过程,语法检查、语义检查、对sql语句进行解析、执行SQL返回结果。其中SQL解析的过程生成解析树(parse tree)及执行计划(execution plan)。这个过程是非常消耗CPU资源的,因此Oracle将解析好的SQL语句(或者说是执行计划)放在library cache中等待复用。
较低的库缓冲区的命中率意味着SQL语句被过早的推出了缓冲区(又要再次硬解析),加大共享池。
Redo Nowait >99
写日志的不等待比率,太低可能是log_buffer偏小,或者log_buffer向磁盘刷日志的参数 _log_io_size(默认为1/3*log_buffer/log_block_size,设置_log_io_size 为合适的值,比如适当减小),或者存放日志的磁盘性能不好(比如RAID划分不当,RAID5或6改为RAID10),或者日志组个数偏少、每个redo log大小偏小,导致log buffer的数据不能及时进入磁盘。
In Memory Sort >95
值过低表明很多排序都在TEMP表(磁盘)中进行,需要检查是否有效率过低的SQL,分析sort_area_size是否太小。也有可能是SQL太烂,需要优化SQL,技术上优化不了了就改为优化业务流程。
Soft Parse >95
能够复用现有执行计划就是软解析,不能复用就要重新硬解析。
近似当作SQL在共享区的命中率,通常高,代表使用了绑定变量, 如果低于80%意味着大量硬解析,SQL没有被有效的重用,需要调整应用使用绑定变量,或者设置cursor sharing参数。
内存使用情况
数据库的内存大小对性能的影响往往比CPU的多少还要重要。
因此需要关注操作系统分给Oracle多少内存(memory target),以及Oracle内部各个内存区域的使用情况。
尽管Oracle11g之后内存默认是自动管理的,但我们了解内存自动变化的情况,对性能分析也有帮助,另外有些用户还是习惯用采用手工方式进行内存区域的划分,划分的是否合理,也可以从内存使用的情况来检查。

假如内存采用了默认的自动管理方式,我们关注的不仅仅是大小,还有在测试过程中的变化趋势。所有的项目都有Begin时的大小和End时的大小,关注其变化趋势。


如果某个区域有明显变大的趋势,说明对这个区域的需求量比较大,而初始的值比较小,Oracle在运行过程中慢慢的调整它。
但Oracle的调整并不是实时的,也不一定能把各个内存区域的配比调到性能最优状态(况且还会有Oracle自身的bug)。

内存advisory
内存的advisory也是值得一看的。可以从中看看目前的内存够不够用。毕竟一个项目上线之前,谁都不知道它会吃多少内存,或者吃某个区域多少内存,测试环境可能内存还是打折的,遇到性能缓慢是不是由内存不足引起的呢?
关注Main Report>Advisory Statistics,可以看到好多区域的advisory

以SGA为例
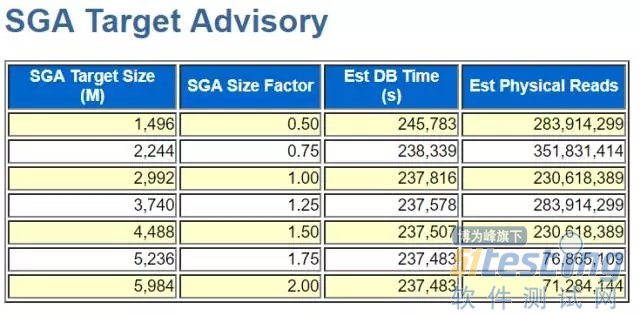
可以看到SGA设置为多少M的情况下,对应的DB Time是多少,物理读是多少。由此可以初步判断当前的内存设置是不是合理。















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









