





原文:In defense of grid features for visual question answering
基于自下而上注意力(bottom-up attention)的边界框视觉特征近年来超越了基于网格的卷积特征,成为了视觉问答(visual question answering,VQA)等视觉和语言相结合的任务中图像特征的标准应用。但是,目前,对于边界框区域特征是否是自下而上注意力成功的原因仍然无法合理解释。本文重新检验了网格特征在VQA中的有效性,发现网格特征可以在获得相同准确率的同时能够将推理速度提高一个数量级,这一结论也在其他的VQA模型、数据集以及类似任务(比如图片描述)中得到了验证。由于网格特征会使得模型设计和训练更加简单,因此有助于端到端进行VQA模型训练和预测。
1. Introduction
在基于视觉和自然语言的多模态领域,近年来最有意义的一项工作非自下而上注意力bottom-up attention莫属。与常规的自上而下注意力(top-down attention)不同,自下而上注意力是采用目标检测器仅仅依靠输入图像本身来识别最有意义的区域,采用基于边界框的特征来表示图片信息,这样的特征提取方式很大程度提升了VQA相关模型的性能。
自然而然地,我们会问,为什么基于边界框地特征效果会这么好。一个显而易见地解释是基于边界框的特征提供了更好的、更有针对性的局部特征;另外一个可能的解释是多个边界框特征可以提供粗粒度和细粒度的图片信息,即使这些框有可能互相重叠。但是,这些可能的优势真的就是边界框特征优于网格特征的原因吗?
通过研究,我们发现在VQA任务中,我们从相同的预训练目标检测器中提取网格特征一样地能够得到与基于边界框特征相似的模型效果;特别地,只要在模型训练时稍加修改,网格特征就能比基于边界框特征的效果更好。消融实验也证明了自下而上注意力之所以能够得到高精度结果的原因在于:1)预训练检测器中使用的Visual Genome数据集中提供了大量的目标及属性标注数据;2)输入图像都是高分辨率的;而对于特征形式本身,不管是边界框特征还是网格特征对精度影响都很小。
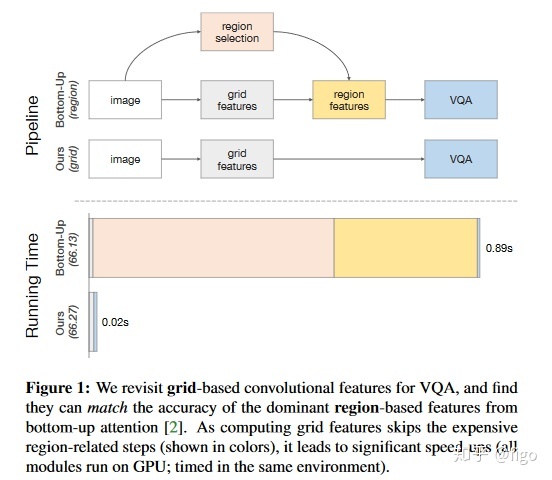
上述研究结果对于以后多模态任务的设计非常重要,将图像特征表示从边界框特征替换为网格特征的最直接收益就在于极大加快了推理速度,如图1所示。以ResNet-50作为主干网络为例,我们发现对于每张图片,VQA任务的整体耗时由原来的0.89s降低至0.02s,精度还略有提高。得益于此,我们试图去端到端地训练VQA模型。之前由于对图像特征模型需要在VQA数据集上进行微调,而微调非常耗时而且难以达到预期目标。
2.Related work
(1) VQA中的视觉特征:VQA任务中,图像的视觉特征非常重要。在VQA领域早期,视觉特征一般通过VGG或者ResNet提取的网格特征来表示,后来又被效果更加显著的自下而上注意力的边界框特征替代。目前,主流的SOTA的VQA模型都是采用边界框特征。
(2)VQA预训练:大部分的VQA都采用两个独立的预训练模型:视觉特征提取模型(一般基于ImageNet和VG);语言特征的词嵌入预训练模型。近年来研究的热点也集中到将两个模型进行联合训练。一个通用的策略是将视觉区域和单词都作为token,采用BERT的变体模型来对mask的token进行预测,实现联合预训练。
(3)Region vs grid:关于边界框特征和网格特征的争论都和目标检测有关:基于R-CNN的目标检测模型证实了边界框特征对于目标检测效果的巨大优势;而基于一阶段的目标检测模型则认为检测任务不需要显式地获得边界框,但是同样能够达到较好的目标检测结果。在本文中,我们采用的是后者的思路。
3. From region to grid
3.1 自下而上注意力的边界框特征
自下而上注意力的边界框特征的提取采用的是Faster R-CNN目标检测模型。为了在VQA任务中获得图像特征,需要进行如下两个步骤:
区域选择:由于Faster R-CNN是一个两阶段的检测器,区域选择在整个pipline中发生了两次。第一次选择是通过RPN确定候选框作为感兴趣区域ROI(Region of Interest);第二次选择是用来获取topN的边界框。在这两步中,都采用了非极大抑制(NMS)来保留有最大分类分值的区域,移除掉其他邻近的相似结果。
区域特征计算:根据第一步提供的区域结果,采用RoIPool操作来获得原始区域级别的特征,另外一个网络则去计算这个区域对应的输出特征,最后包含了边界框特征和对应框内图像特征的组合特征就作为最终的图像特征。
3.2 来自相同层的网格特征
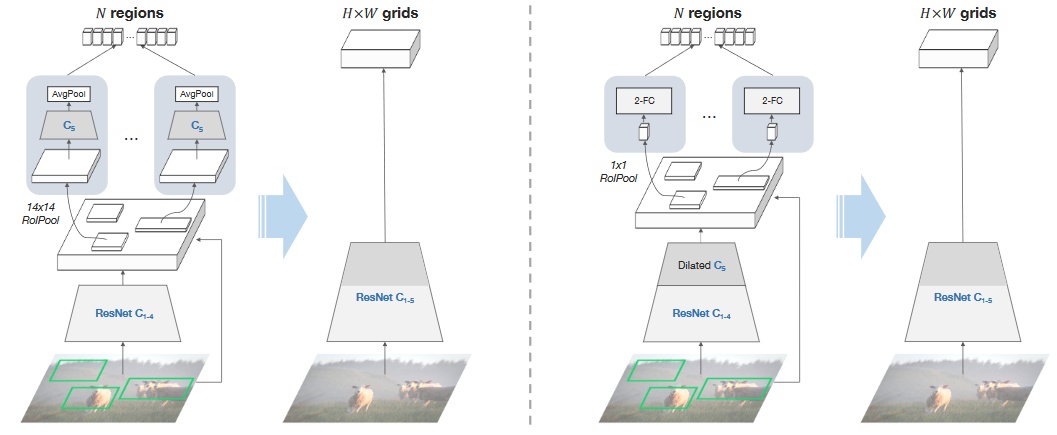
将边界框特征转换为网格特征最简单直接的方式是看是否能在网络的同一层计算相关特征,但是是以共享的全卷积方式。为此,我们需要先研究下Faster R-CNN网络的结构。
Faster R-CNN是c4模型的变体,增加了一个额外的分支去获得属性分类。它将ResNet的权重参数分为了两个部分:给定输入的图片,首先采用ResNet前C4层计算feature map,这个feature map对所有区域都是共享的。然后,区域特征首先是采用C5 block在14×14 RoIPooled的特征上计算获得,C5的输出经过一个平均池化后得到每一个区域的最终向量表示。既然所有最终的区域特征都是来自于C5,所以我们可以直接在原始的ResNet上提取C5的输出作为网格特征即可。Fig.2左边的图为上述转换的示意图。
在后续的实验中已经证明仅仅采用上述简单的转换,采用网格特征就能在VQA中表现很好。VQA性能因此稍有降低,但其主要原因是因为Fast R-CNN是基于区域进行目标检测的优化模型,可能不太适用于网格特征。因此可以在此基础上进行额外的调整来提高网格特征的效果。
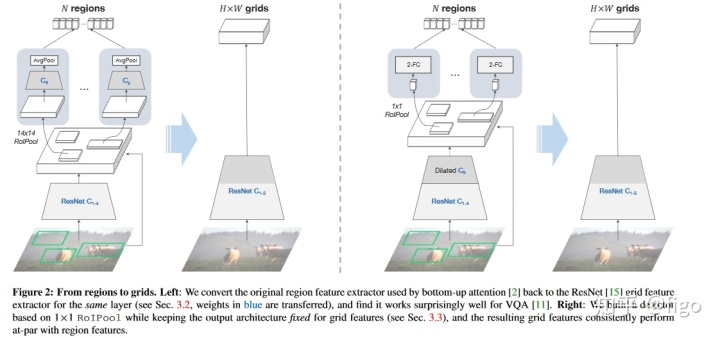
3.3 1×1 RoIPool
额外调整的思路很简单,就是采用1×1 RoIPool,也就是说对于每一个区域,只采用一个向量来表示其区域特征,而不是Faster R-CNN中的三维张量。这样做起初看可能会觉得这是非常规操作,因为另外的两个空间维度(宽和高)对于区分二维物体的不同部分非常有用。确实,我们也证明了这样做会使得在VG上的目标检测效果变差,但是采用1×1 RoIPool也意味着在网格feature map上的每一个向量都会被强制包括这个区域的所有信息,间接上使得网格特征表征的信息更加丰富。
但是直接采用1×1 RoIPool是有问题的,因为C5包括了几个ImageNet预训练卷积层,这些层在输入图像的某些空间维度表现效果最好。为了解决这个问题,我们采用了完整的ResNet作为主干网络,对于区域特征,我们在C5之后增加了两个1024D的FC层,接受压缩后的向量作为输入。
为了降低在训练目标检测器时从C5取出的特征有低分辨率的问题,strider为2的网络层改为strider为1,其他层设置膨胀系数为2。
Fig2右图为上述调整的示意图。
4.实验
4.1 experiment setup
Faster R-CNN:采用ResNet为主干网络,在ImageNet上进行预训练。根据自上而下注意力原理,将模型在VG数据集上进行训练,该数据集包括区域粒度的1600个目标类别和400个属性分类。对于边界框特征,输出数量N=100。
VQA split:VQA2.0数据集切分采用默认切分。
VQA模型:采用Pythia的协同注意力模型co-attention model,将图像特征(网格特征或者边界框特征)和问题的文本特征融合,输出答案。
4.2 实验结果
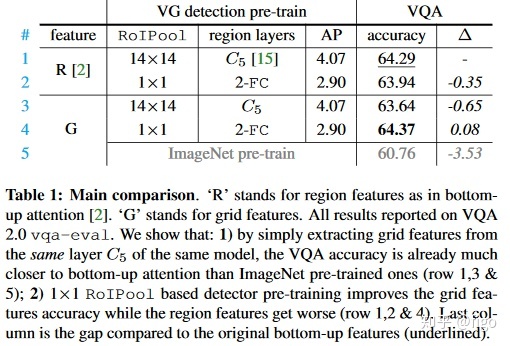
主要结果如Table1所示。首先和常规的边界框特征相比,直接从C5抽取网格特征的结果表现非常好,前者准确率64.29%,而后者为63.64%,而如果直接采用ImageNet预训练模型的结果,准确率仅为60.76%。
当采用1×1 RoIPool后,基于边界框特征的准确率为63.94%,而网格特征的准确率为64.73%,后者效果更好。这也证明了采用网格特征的优越性。
4.3 边界框数量的影响
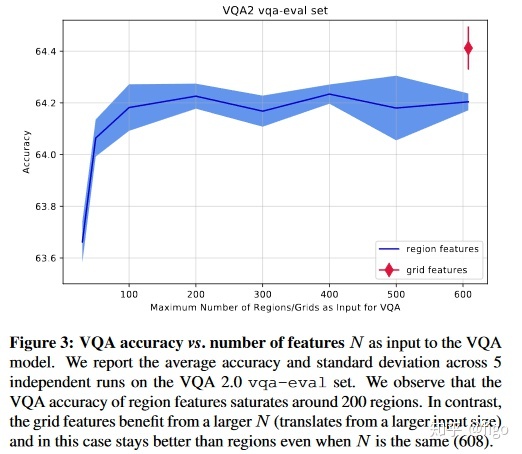
下图为对边界框数量的敏感性分析。本文中的边界框特征默认设置采用N=100。而由于网格特征是全卷积的feature map,对于最大图片输入尺寸600×1000,在C5上strider为32的情况下,会得到608个feature map,比默认的边界框数量要大很多。
当N从36变化到600时,其准确率的变化如下图蓝色线条所示,边界框数量的增加可以一定程度上提高准确率。但是当N=600时,其准确率还是远低于网格特征的结果,表明边界框数量并非影响准确率的主要原因。
4.4 推理时间
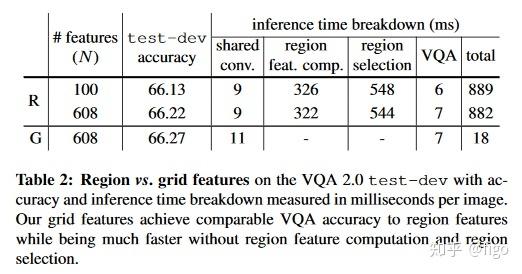
VQA2.0测试集上的耗时结果如下图所示。可以看出,基于网格特征的VQA推理时间比基于边界框特征的推理时间要节省约48倍。
一些典型的VQA结果如下图所示。

5.为什么网格特征在VQA中表现很好
本文通过进一步的实验表明,网格特征之所以在VQA中表现较好,主要原因包括:
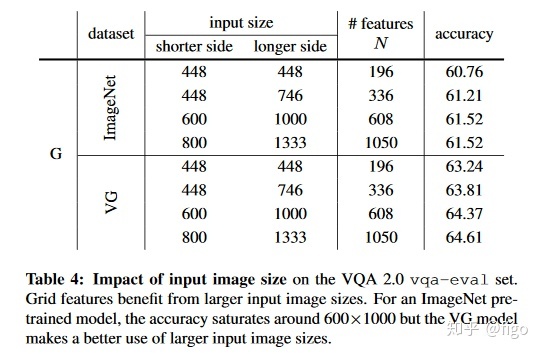
1)输入图片的尺寸:图片尺寸越大,基于网格特征的VQA效果更好。
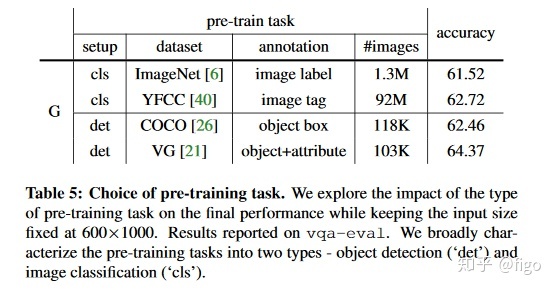
2)预训练任务:通过分类任务和目标检测任务对比发现,不管什么任务,预训练时训练数据越多,预训练模型能力越强,在VQA中的表现也更好。
感兴趣的朋友也可以关注公众号【NLP论文翻译工程师】,一起交流。
http://weixin.qq.com/r/6ilrc-PEeq4FrbcQ93z4 (二维码自动识别)















 7279
7279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









