






上一节我们初步认识pandas,这一节将会利用pandas进行简单的数据筛选和其他处理,请大家耐心跟着小帮手一点一点融会贯通哟~
目录
一. 数据导入回顾
二. 数据筛选
三. 给数据打标签
四. 行的查改增删

一. 数据导入回顾
我们先用一个文件例子进行数据导入的回顾和练习。假设我们电脑上有一个excel文件‘2019年销售数据.xlsx' :
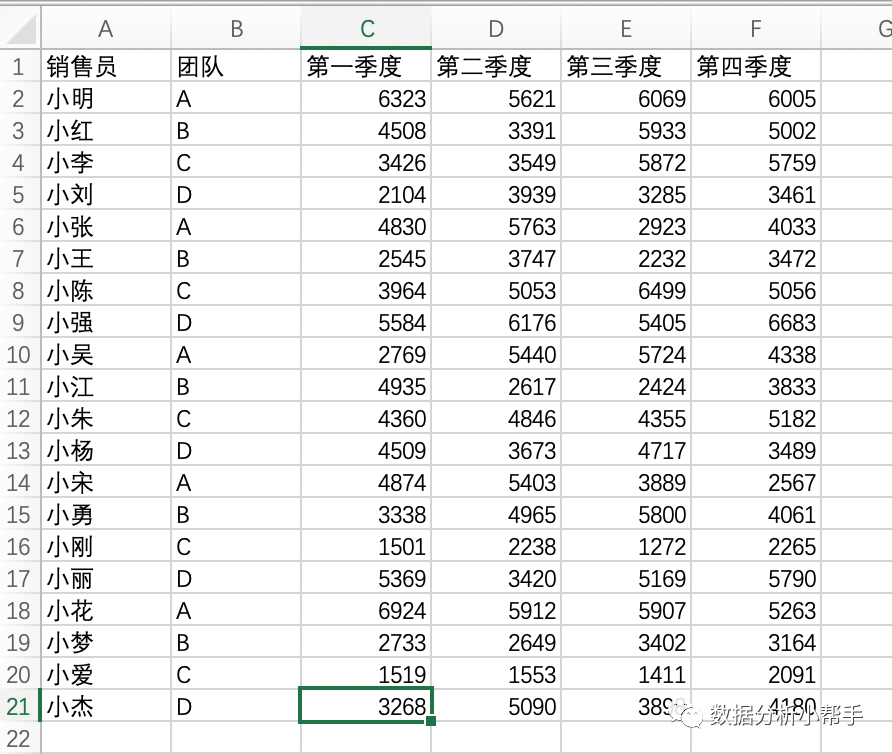
导入数据的代码如下(代码过长,滑动查看):
import pandas as pddf=pd.read_excel('/Users/harrison/Desktop/2019年销售数据.xlsx')为了查看导入表格的形式,我们可以通过以下代码查看一下表格的前5条数据:
print(df.head())输出的结果如下:
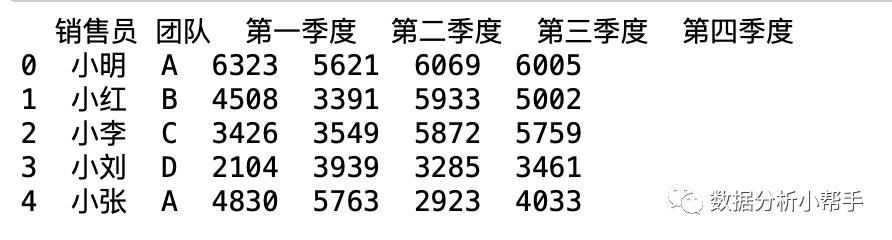
查看部分数据的方法除了head()还有:
tail():查看末尾5条数据
info():查看表格的属性(上一节有运行展示)
接下来,假设需要查看一年的销售额,我们需要对四个季度的销售额进行加法运算:
df['总和']=df['第一季度']+df['第二季度']+df['第三季度']+df['第四季度']print(df.head())前五条的结果就变为:
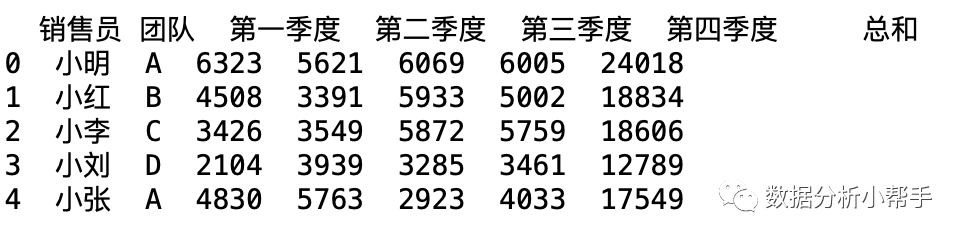
这样我们就算出了每个销售员每年的销售额是多少!
二. 数据筛选
还是以2019年销售数据.xlsx 为例,我们想要筛选出那些总销售额低于平均值的销售员,同样也只要一行代码即可:
df[df['总和']这样表格中就只会保留满足这一条件的数据:

这些人的业绩低于公司业绩的平均值,绩效不合格,需要重点关注他们,帮他们提高业绩。
我们也可以写多个条件进行判断,在 pandas 中要表示同时满足,各条件之间要用 & 符号连接。如果要表示只要满足之一,各条件之间要用 | 符号来连接。并且每个条件要用括号括起来,举个例子:
# 筛选出总和大于 10000 且小于 12000 的df[(df['总和'] > 10000) & (df['总和'] < 12000)]# 筛选出总和小于 5000 或大于 12000 的df[(df['总和'] < 5000) | (df['总和'] > 12000)]三. 给数据打标签
pandas 的 cut() 方法常用于数据的分类和打标签,它的主要参数和用法如下:
pd.cut(df['总和'], bins=[0, 1000, 2000, 3000], labels=['不合格', '良好', '优秀'])第一个参数是要分类的列,参数 bins 是分类的方式,即分类区间。默认是左开右闭,上面的例子中表示按 (0, 1000]、(1000, 2000] 和 (2000, 3000] 分为三组。如果你想要左闭右开的方式,可以再添加一个参数 right=False。
最后的参数 labels 分别对应了这三组的标签名。即 (0, 1000] 表示不合格,(1000, 2000] 表示良好,(2000, 3000] 表示优秀。
应用到我们的例子当中,需要按平均值来分类,对应的代码如下:
df['绩效'] = pd.cut(x=df['总和'], bins=[0, df['总和'].mean() * 0.9, df['总和'].mean() * 1.2, df['总和'].max()], labels=['不合格', '良好', '优秀'])调用print(df.head())得到的结果为:
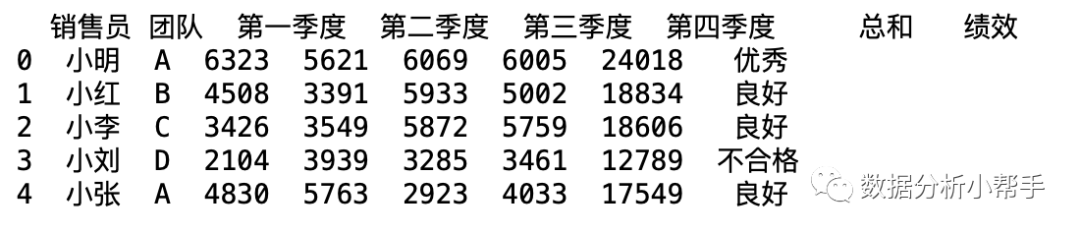
可以看到,使用 pandas,只要一行代码就完成了对员工的绩效评分!
四. 行的查改增删
首先,我们用 DataFrame 构建一个简单的表格:

列是通过列名来获取的,同理,行是通过最左边的索引来获取。在不指定的情况下,索引值默认从 0 开始依次递增。我们可以使用 loc 基于索引进行表格行的查改增删。
1. 查看行
以查看上面表格中第一行的数据为例,代码和输出结果如下:

如果你在构建表格时像下面这样单独设置了索引,同样也可以用对应的索引值来获取表格行的数据:
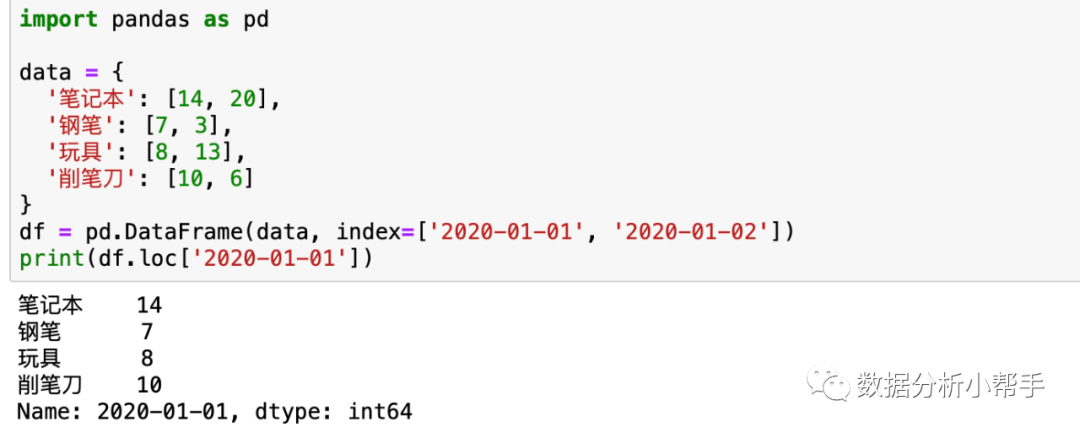
除了第一个参数索引外,还支持第二个参数列名。即同时基于行和列获取指定的数据,比如:
print(df.loc[0, '笔记本'])上面代码的意思是获取行为 0 且列为笔记本的数据,运行的结果为 14。
同时,行和列还支持分片的写法,我们来看几个例子:
# 行分片print(df.loc[0:1, '笔记本'])# 列分片print(df.loc[0, '笔记本':'玩具'])# 同时分片print(df.loc[0:1, '笔记本':'玩具'])上面代码的运行结果分别如下:
#行分片

#列分片

#同时分片

也可以通过省略冒号前后的内容来实现全选,例如:df.loc[:, '笔记本':'玩具']
loc 同时也支持布尔索引来进行数据的筛选,比如获取笔记本销量大于 15 的数据:
df.loc[df['笔记本'] > 15]上面的写法等价于 df[df['笔记本'] > 15],不同之处在于 loc 还能通过第二个参数筛选出只想查看的列,比如:

除了比较常用的 loc 之外,我们还能使用 iloc。用法和 loc 一样,区别在于 loc 使用的参数是索引,而 iloc 的参数是位置,即第几行。
因此,在不指定索引的情况下,loc 和 iloc 的效果是一样的。但当单独指定了索引,我们想获取前 3 行数据时可以像下面这样写:

索引变成了日期,想要按位置获取数据的话只能使用 iloc,这时如果使用 df.loc[:3] 将会报错。
2. 修改行
假设某行的数据有问题,我们需要进行修正。修改起来同样也很简单,直接赋值即可。这里分为两种情况:
赋值为一个数字;
赋值为长度和列数相等列表。
对于第一种情况,这一行所有的数据都会被修改成同样的数字:
df.loc[0] = 1 # 第一行都改成 1print(df)而第二种情况则是按列表顺序修改对应的列:
# 将第一行按顺序修改成 1 2 3 4df.loc[0] = [1, 2, 3, 4]print(df)当然你也可以使用例如 df.loc[0, '笔记本'] = 23 定位到行和列来修改特定的数据。
3. 新增行
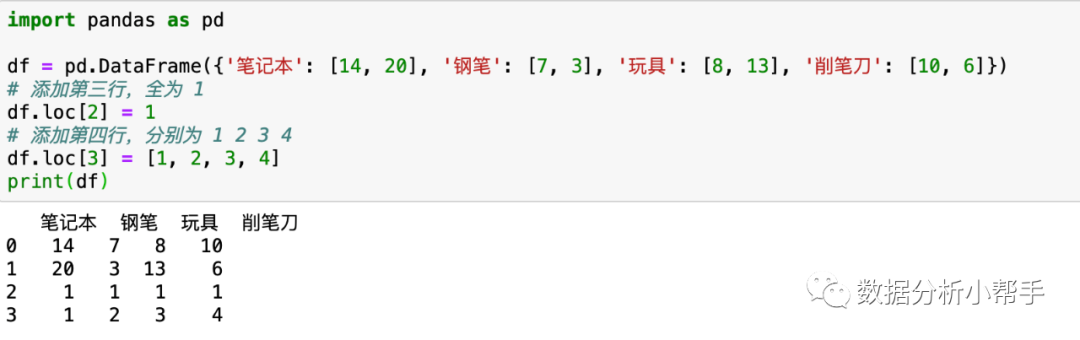
你应该也发现了,行和列的基本操作都是类似的,只是具体的方式不同。新增行也是如此,只需传入表格中不存在的索引即可。
4. 删除行
删除行和删除列一样,都是使用 drop() 方法。删除列的使用传入了 axis=1 表示对列进行删除,axis 默认为 0,因此删除行时省略 axis 参数即可。
df.drop(0, inplace=True) # 删除第一行print(df)# 或者 print(df.drop(0))温馨提醒:第四部分---行的查改增删最好可以对比第五节pandas入门中列的查改增删进行学习
?
长按关注公众号
欢迎留言交流
















 9807
9807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









