






摘要
CYK算法是一个基于“动态规划”算法设计思想,用于测试串w对于一个上下文无关文法L的成员性的一个算法。CYK算法可以在\(O(n^3)\)的时间内得出结果。CYK算法是由三个独立发现同样思想本质的人(J. Cocke、 D. Younger和T. Kasami)来命名的。这篇博客将主要介绍乔姆斯基范式、CYK算法的流程以及其代码实现。
1. 乔姆斯基范式
任何一个非空且不含\(\epsilon\)的上下文无关文法(CFL)都具有特殊形式的文法G。G中所有的产生式都属于以下两个简单的形式之一:
(1). \(A \to BC\),其中A,B和C都是变元
(2). \(A \to a\),其中a是终结符
更进一步,\(G\)没有无用的符号。这样的文法就称为乔姆斯基范式或CNF
将一个一般的CFL构造一个CNF的过程如下:
(1). 为每个出现在长度大于等于2的产生式中的终结符a创建一个新的变元A,该变元只有一个产生式\(A \to a\)。接着,可以用A来替代所有产生式中出现的a。现在,所有产生式或者是单个终结符,或者是至少两个以上的变元并且没有终结符。
(2). 把所有形式为\(A \to B_1B_2B_3…B_k(k \ge 3)\)的产生式打断为以下一组产生式:\(A \to B_1C_1, C_1 \to B_2C_2, …, C_{k-3} \to B_{k-2}C_{k-2}, C_{k-2} \to B_{k-1}B_k\)。
现在,所有的产生式都符合CNF的定义。
2. CYK算法介绍
 CYK算法从一个CFL L的CNF文法\(G=(V, T, P, S)\),输入是T中的串\(w=a_1a_2…a_n\)。该算法在\(O(n^3)\)的时间内构造出一个表明w是否属于L的表。表的结构如图。水平轴对应串\(w=a_1a_2…a_n\)中的位置,图中假定\(n=5\)。\(x_{ij}\)是满足\(A \dot{\Rightarrow} a_ia_{i+1}…a_j\)的变元A的集合。特别地,如果S属于集合\(x_{1n}\),那么w就属于L。
CYK算法从一个CFL L的CNF文法\(G=(V, T, P, S)\),输入是T中的串\(w=a_1a_2…a_n\)。该算法在\(O(n^3)\)的时间内构造出一个表明w是否属于L的表。表的结构如图。水平轴对应串\(w=a_1a_2…a_n\)中的位置,图中假定\(n=5\)。\(x_{ij}\)是满足\(A \dot{\Rightarrow} a_ia_{i+1}…a_j\)的变元A的集合。特别地,如果S属于集合\(x_{1n}\),那么w就属于L。
为了填写这个表,我们一行一行,自下而上地处理。每一行对应一种长度的子串。最下面一行对应长度为1的子串,倒数第二行对应长度为2的子串,以此类推。最上面一行就对应长度为n的子串,即w本身。计算该表的任何一个表项的方法如下:
(1). 对于最下面一行的表项,即\(x_{ii}\),是使得\(A \to a_i\)是G的产生式的变元A的集合。
(2). 对于不在最下一行的表项,我们需要找到符合以下条件的变元A的集合:
I. 整数k满足\(i \leq k
II. B属于\(X_{ik}\)
III. C属于\(X_{k+1,j}\)
IV. \(A \to BC\)是G的产生式
例如,对于下列CNF文法G的产生式,对L(G)测试baaba的成员性所构造的表如图所示。下以\(x_{24}\)为例来展示\(x_{ij}\)的计算。我们可以选择\(k=2\)或\(k=3\)。因此,必须考虑所有\(x_{22}x_{34} \cup x_{23}x_{44}\)构成的产生体。这个串的集合是\(\{A, C\}\{S, C\} \cup \{B\}\{B\} = \{AS, AC, CS, CC, BB\}\)。该集合中只有\(CC\)是\(B \to CC\)的产生体,因此\(x_{24}=\{B\}\)。
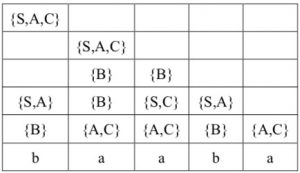
\(S \to AB | BC\)
\(A \to BA | a\)
\(B \to CC | b\)
\(C \to AB | a\)
3. CYK算法的实现
以下是CYK算法的核心函数。整个程序还包含了实现乔姆斯基范式的类、从文件读取乔姆斯基范式等关键功能的实现,由于篇幅原因不方便在此博客中全部展示。若要获取完整的可编译源文件,请访问Github:https://github.com/ssaalkjhgf/CYKAlgorithm.git
//************************************************************************************
//Use CYK algorithm to judge whether the string str is in the Chomsky normal form CFG
bool CYK(string str, const CNF& cnf) {
//Get each word in the string str
vector sentence = split(str, ' ');
int wordCount = sentence.size();
//Allocate memory for CYKMat, a matrix of set storing all the parsing conditions of str[i..j]
set** CYKMat = new set*[wordCount + 1];
for (int i = 0; i <= wordCount; i++) {
CYKMat[i] = new set[wordCount + 1];
}
//Preprocess the words, get the CYKMat[i][i]
for (int i = 1; i <= wordCount; i++) {
CYKMat[i][i] = cnf.produce(sentence[i - 1]);
}
//Calculate the rest part of CYKMat
//For each length
for (int length = 2; length <= wordCount; length++) {
//For each starting position
for (int i = 1; i <= wordCount - length + 1; i++) {
//For each middle point of str[i..i+length-1]
for (int k = i; k < i + length - 1; k++) {
//Get the set of variables that CYKMat[i][k] and CYKMat[k+1][i+length-1] can produce
set tmp = cnf.produce(CYKMat[i][k], CYKMat[k + 1][i + length - 1]);
//Union
CYKMat[i][i + length - 1].insert(tmp.begin(), tmp.end());
}
}
}
//If CYKMat[1][wordCount] consists of the starting symbol, accept the string
if (CYKMat[1][wordCount].find(cnf.getStartSymbol()) == CYKMat[1][wordCount].end())
return false;
else
return true;
}














 2463
2463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









