





设想一下这么一个需求:
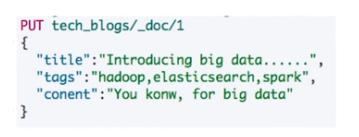
后期需要对Tags做aggs统计,tags文本中,逗号分隔的文本应该是一个数组,而不是字符串
在es中可以通过ingest node实现这个需求
Ingest Node(预处理节点)是ES用于功能上命名的一种节点类型,可以通过在elasticsearch.xml进行如下配置来标识出集群中的某个节点是否是Ingest Node.
在es 5.0引入的一种新的节点类型,默认配置下每个节点都是ingest node:
1.具有预处理数据的能力,可拦截index 和 bulk api的请求
2.对数据进行转换,并重新返回给index 和 bulk api
无须使用logstash就可以进行数据的预处理,例如
1.为某个字段设置默认值,重命名某个字段的字段名,对字段进行split操作
2.支持设置painless脚本,对数据进行更加复杂的加工
总结:
可以这么说,在Elasticsearch没有提供IngestNode这一概念时,我们想对存储在Elasticsearch里的数据在存储之前进行加工处理的话,我们只能依赖Logstash或自定义插件来完成这一功能,但是在Elasticsearch 5.x版本中,官方在内部集成了部分Logstash的功能,这就是Ingest,而具有Ingest能力的节点称之为Ingest Node。
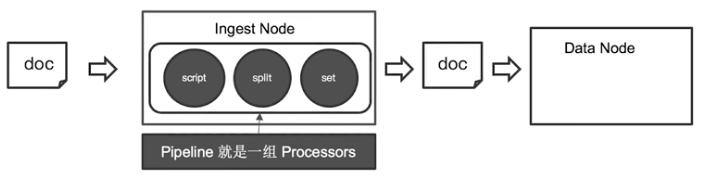
Pipeline(管道) 和 Processors (加工)
如果要脱离Logstash来对在Elasticsearch写入文档之前对文档进行加工处理,比如为文档某个字段设置默认值,重命名某个字段,设置通过脚本来完成更加复杂的加工逻辑,我们则必须要了解两个基本概念: Pipeline 和 Processors。
Pipeline - 对通过的文档按照顺序进行加工。
Processors - elasticsearch对一些加工行为进行了抽象的包装。es中有很多内置的processors也可以通过插件形式实现自己的processors。
定义一个Pipeline是件很简单的事情,官方给出了参考:
PUT _ingest/pipeline/my-pipeline-id{ "description" : "describe pipeline", "processors" : [ { "set" : { "field": "foo", "value": "bar" } } ]}上面的例子,表明通过指定的URL请求"_ingest/pipeline"定义了一个ID为"my-pipeline-id"的pipeline,其中请求体中的存在两个必须要的元素:
- description 描述该pipeline是做什么的
- processors 定义了一系列的processors,这里只是简单的定义了一个赋值操作,即将字段名为"foo"的字段值都设置为"bar"
简介 Simulate Pipeline API
既然Elasticsearch提供了预处理的能力,总不能是黑盒处理吧,为了让开发者更好的了解和使用预处理的方式和原理,官方也提供了相关的接口,来让我们对这些预处理操作进行测试,这些接口,官方称之为: Simulate Pipeline API。
在上面具体的例子中,我们并没有在请求URL中指定使用哪个pipeline,因此我们不得不在请求体中即时定义一个pipeline和对应的processorsPOST _ingest/pipeline/_simulate{ "pipeline" : { "description": "_description", "processors": [ { "set" : { "field" : "foo", "value" : "bar_new" } } ] }, "docs": [ { "_index": "index", "_type": "type", "_id": "id", "_source": { "foo": "bar" } }, { "_index": "index", "_type": "type", "_id": "id", "_source": { "foo": "rab" } } ]}在上面具体的例子中,我们并没有在请求URL中指定使用哪个pipeline,因此我们不得不在请求体中即时定义一个pipeline和对应的processors。
也可以通过url指定具体pipeline来测试:
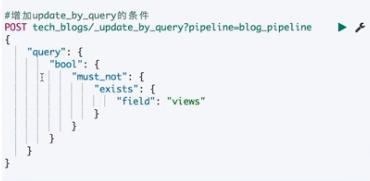
POST _ingest/pipeline/my-pipeline-id/_simulate{ "docs" : [ { "_source": {/** first document **/} }, { "_source": {/** second document **/} }, // ... ]}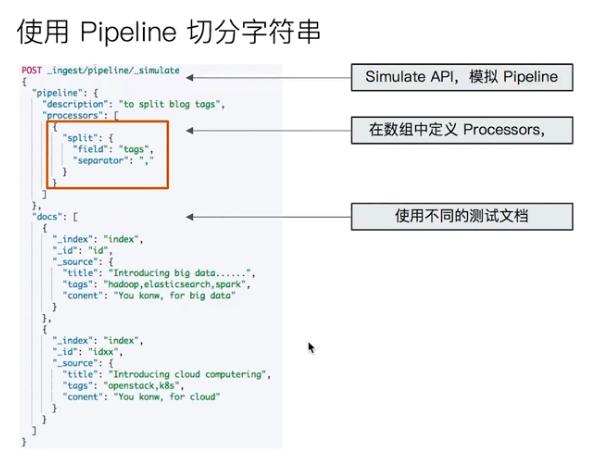


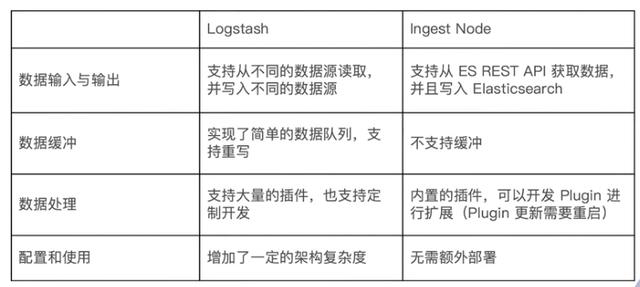
Logstash与ingest node比较
Painless介绍


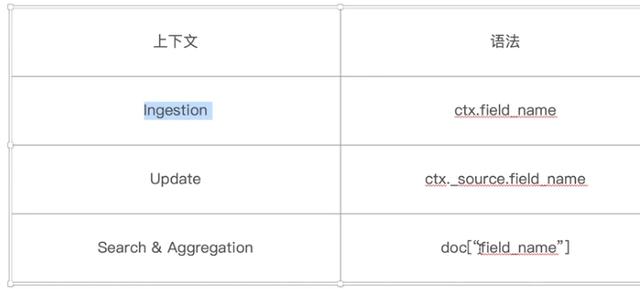
通过painless访问字段

脚本缓存
















 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









