






1.场景
在搭建好Hadoop+Spark环境后,现准备在此环境上提交简单的任务到Spark进行计算并输出结果。搭建过程:http://www.cnblogs.com/zengxiaoliang/p/6478859.html
本人比较熟悉Java语言,现以Java的WordCount为例讲解这整个过程,要实现计算出给定文本中每个单词出现的次数。
2.环境测试
在讲解例子之前,我想先测试一下之前搭建好的环境。
2.1测试Hadoop环境
首先创建一个文件wordcount.txt 内容如下:
Hello hadoop
hello spark
hello bigdata
yellow banana
red apple
然后执行如下命令:
hadoop fs -mkdir -p /Hadoop/Input(在HDFS创建目录)
hadoop fs -put wordcount.txt /Hadoop/Input(将wordcount.txt文件上传到HDFS)
hadoop fs -ls /Hadoop/Input (查看上传的文件)
hadoop fs -text /Hadoop/Input/wordcount.txt (查看文件内容)
2.2Spark环境测试
我使用spark-shell,做一个简单的WordCount的测试。我就用上面Hadoop测试上传到HDFS的文件wordcount.txt。
首先启动spark-shell命令:
spark-shell
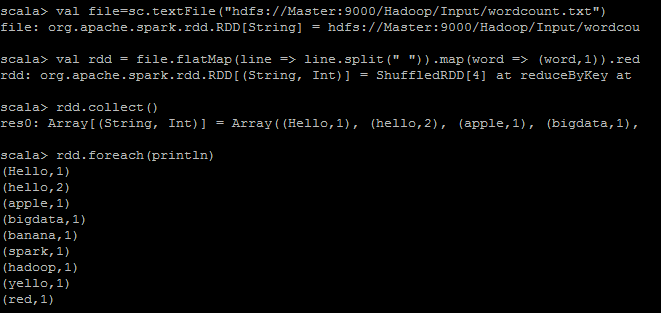
然后直接输入scala语句:
val file=sc.textFile("hdfs://Master:9000/Hadoop/Input/wordcount.txt")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
退出使用如下命令:
:quit
这样环境测试就结束了。
3.Java实现单词计数
packagecom.example.spark;importjava.util.Arrays;importjava.util.Iterator;importjava.util.List;importjava.util.regex.Pattern;importorg.apache.spark.SparkConf;importorg.apache.spark.api.java.JavaPairRDD;importorg.apache.spark.api.java.JavaRDD;importorg.apache.spark.api.java.JavaSparkContext;importorg.apache.spark.api.java.function.FlatMapFunction;importorg.apache.spark.api.java.function.Function2;importorg.apache.spark.api.java.function.PairFunction;importscala.Tuple2;public final classWordCount {private static final Pattern SPACE = Pattern.compile(" ");public static void main(String[] args) throwsException {
SparkConf conf= new SparkConf().setAppName("kevin's first spark app");
JavaSparkContext sc= newJavaSparkContext(conf);
JavaRDD lines = sc.textFile(args[0]).cache();
JavaRDD words = lines.flatMap(new FlatMapFunction() {private static final long serialVersionUID = 1L;
@Overridepublic Iteratorcall(String s) {returnArrays.asList(SPACE.split(s)).iterator();
}
});
JavaPairRDD ones = words.mapToPair(new PairFunction() {private static final long serialVersionUID = 1L;
@Overridepublic Tuple2call(String s) {return new Tuple2(s, 1);
}
});
JavaPairRDD counts = ones.reduceByKey(new Function2() {private static final long serialVersionUID = 1L;
@OverridepublicInteger call(Integer i1, Integer i2) {return i1 +i2;
}
});
List> output =counts.collect();for (Tuple2, ?>tuple : output) {
System.out.println(tuple._1()+ ": " +tuple._2());
}
sc.close();
}
}
4.任务提交实现
将上面Java实现的单词计数打成jar包spark-example-0.0.1-SNAPSHOT.jar,并且将jar包上传到Master节点,我是将jar包上传到/opt目录下,本文将以两种方式提交任务到spark,第一种是以spark-submit命令的方式提交任务,第二种是以java web的方式提交任务。
4.1以spark-submit命令的方式提交任务
spark-submit --master spark://114.55.246.88:7077 --class com.example.spark.WordCount /opt/spark-example-0.0.1-SNAPSHOT.jar hdfs://Master:9000/Hadoop/Input/wordcount.txt
4.2以java web的方式提交任务
我是用spring boot搭建的java web框架,实现代码如下:
1)新建maven项目spark-submit
2)pom.xml文件内容,这里要注意spark的依赖jar包要与scala的版本相对应,如spark-core_2.11,这后面2.11就是你安装的scala的版本。
4.0.0
org.springframework.boot
spring-boot-starter-parent
1.4.1.RELEASE
spark-submit
spark-submit
com.example.spark.SparkSubmitApplication
UTF-8
1.8
3.4
2.1.0
org.apache.commons
commons-lang3
${commons.version}
org.apache.tomcat.embed
tomcat-embed-jasper
provided
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.boot
spring-boot-starter-test
test
com.jayway.jsonpath
json-path
org.springframework.boot
spring-boot-starter-web
spring-boot-starter-tomcat
org.springframework.boot
org.springframework.boot
spring-boot-starter-jetty
org.eclipse.jetty.websocket
*
org.springframework.boot
spring-boot-starter-jetty
provided
javax.servlet
jstl
org.eclipse.jetty
apache-jsp
provided
org.springframework.boot
spring-boot-starter-data-solr
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-web
javax.servlet
jstl
org.apache.spark
spark-core_2.11
${org.apache.spark-version}
org.apache.spark
spark-sql_2.11
${org.apache.spark-version}
org.apache.spark
spark-hive_2.11
${org.apache.spark-version}
org.apache.spark
spark-streaming_2.11
${org.apache.spark-version}
org.apache.hadoop
hadoop-client
2.7.3
org.apache.spark
spark-streaming-kafka_2.11
1.6.3
org.apache.spark
spark-graphx_2.11
${org.apache.spark-version}
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
com.fasterxml.jackson.core
jackson-core
2.6.5
com.fasterxml.jackson.core
jackson-databind
2.6.5
com.fasterxml.jackson.core
jackson-annotations
2.6.5
war
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
maven2
http://repo1.maven.org/maven2/
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
maven-war-plugin
src/main/webapp
org.mortbay.jetty
jetty-maven-plugin
spring.profiles.active
development
org.eclipse.jetty.server.Request.maxFormContentSize
600000
true
/
7080
3)SubmitJobToSpark.java
packagecom.example.spark;importorg.apache.spark.deploy.SparkSubmit;/***@authorkevin
**/
public classSubmitJobToSpark {public static voidsubmitJob() {
String[] args= new String[] { "--master", "spark://114.55.246.88:7077", "--name", "test java submit job to spark", "--class", "com.example.spark.WordCount", "/opt/spark-example-0.0.1-SNAPSHOT.jar", "hdfs://Master:9000/Hadoop/Input/wordcount.txt"};
SparkSubmit.main(args);
}
}
4)SparkController.java
packagecom.example.spark.web.controller;importjavax.servlet.http.HttpServletRequest;importjavax.servlet.http.HttpServletResponse;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.stereotype.Controller;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RequestMethod;importorg.springframework.web.bind.annotation.ResponseBody;importcom.example.spark.SubmitJobToSpark;
@Controller
@RequestMapping("spark")public classSparkController {private Logger logger = LoggerFactory.getLogger(SparkController.class);
@RequestMapping(value= "sparkSubmit", method ={ RequestMethod.GET, RequestMethod.POST })
@ResponseBodypublicString sparkSubmit(HttpServletRequest request, HttpServletResponse response) {
logger.info("start submit spark tast...");
SubmitJobToSpark.submitJob();return "hello";
}
}
5)将项目spark-submit打成war包部署到Master节点tomcat上,访问如下请求:
http://114.55.246.88:9090/spark-submit/spark/sparkSubmit
在tomcat的log中能看到计算的结果。














 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









