






前面咱们介绍了scrapy框架的使用,今天就来实战,爬取一下腾讯招聘的职位信息。
一、分析url
二、创建scrapy项目并生成爬虫
三、提取数据
四、保存数据
一、分析url
先确定url,这是网站的url:
url 咱们的需求是获取职位的名称、下面的工作职责、工作需求,并实现翻页操作。
分析网页源代码,发现这些信息都不在源码中,考虑使用抓包工具,进入network,刷新后出现一个带有“query”的文件,可以从中找到咱们想要的信息。因此,现在的url就是要作为起始的url:
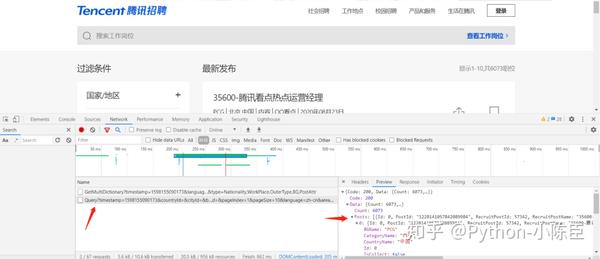
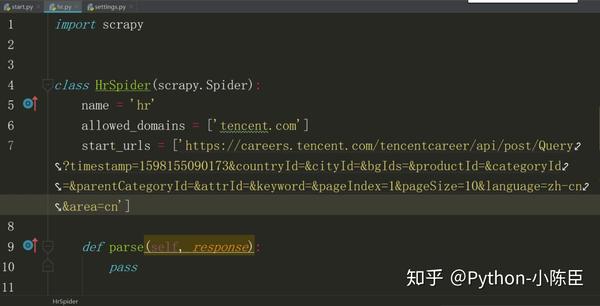
起始url(列表页,总的职位信息页面)为:
one_url 同样的方法,能找到起始url(详情页,单个职位的具体信息页面)为:
two_url 二、创建scrapy项目并生成爬虫
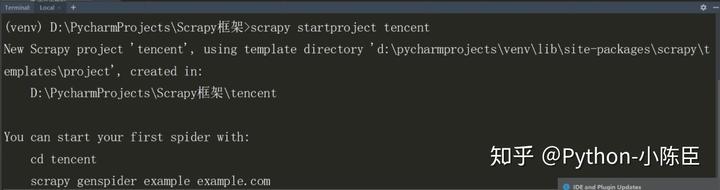
现在,通过terminal终端创建一个scrapy项目:
scrapy startproject tencent



三、提取数据
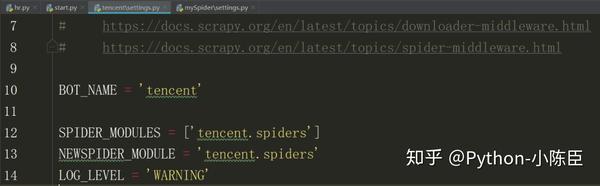
1.对setting文件进行设置
为了不让其他信息显示出来干扰数据,设置中加入如下字段:
LOG_LEVEL 如下图:
2.添加start文件
在总目录下添加start.py文件,用于运行爬虫。
start文件代码如下:
from 右键run运行。
结果如下:

可以看到,数据已经获取到了。要做进一步处理。
3.对解析函数parse()进行定义
因为要实现翻页操作,因此要对每一页的url进行遍历,在parse()中,这部分代码如下(要爬取1-10页):
import 结果如下:

接着编辑parse_two():
def 结果如下:

可以发现,整个数据是从最后一页(第10页)倒着往前打印的。至此,数据已经全都获取到了。
其中,要对页码url进行请求,获取每页数据,会用到scrapy.Request
这是其中的参数:
scrapy.Request(url,callback=None,method=‘GET’,headers=None,bod y=None,cookies=None,meta=None,encoding=‘utf-8’,priority=0,2 dont_filter=False,errback=None,flags=None)
scrapy.Request常用参数为:
callback:指定传⼊的URL交给哪个解析函数去处理,回调函数是用来自定义一个接收函数名(接收响应结果)。
meta:实现不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度。
dont_filter:让scrapy的去重不会过滤当前URL,scrapy默认有URL去重功能,对需要重复请求的URL有重要⽤途。
4.一些细节
4.1 items文件的使用
如果想把要获取的字段提前定义好,要用到items.py文件。在其中将之前定义要获取的字段按照这一格式写好:
class 将tencent文件夹设置成根目录:右键tencent文件夹
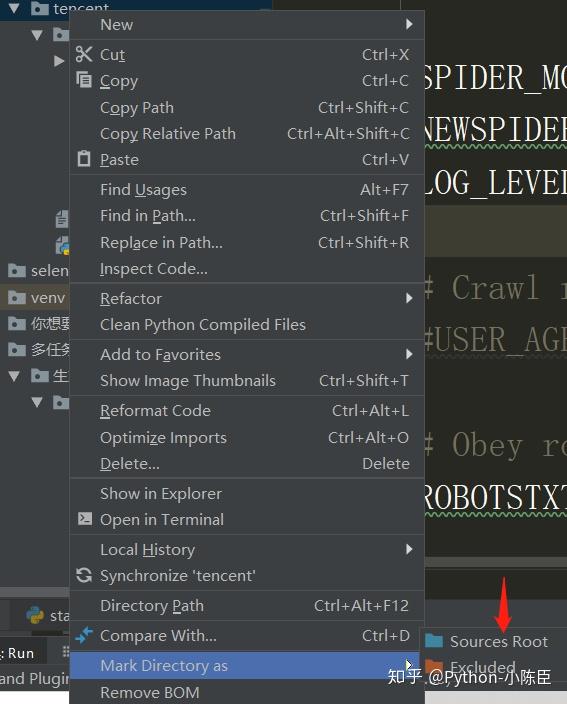
设置成根目录,在hr.py文件中导入:
from 在已定义的字段之前,加上:item=TencentItem(),再次执行即可,能够排除因字段错误导致的问题。
4.2验证爬虫文件的其他方式
前面咱们讲了2种方法,今天来介绍第三种方法。
isinstance():判断一个对象是否是另一个对象的实例,可以沿用到这里:
from 这样也能验证是不是某个爬虫文件的数据,要记住在这之前,要yield字段数据;打开setting中的pipeline。再去运行start.py文件。
四、保存数据
在pipelines文件中进行保存数据的剩余工作。关于pipelines的使用,在前面已经介绍过。
好了,今天的scrapy实战操作就到这里了。
Python爬虫基础部分:
- Python 怎么快速入门?11篇实战干货带你深入了解 Python爬虫!建议收藏
Python爬虫进阶部分:
- 第一篇:Python爬虫进阶(一)爬虫之动态数据与selenium
- 第二篇:Python爬虫进阶(二)爬虫之多任务模块(Ⅰ)
- 第三篇:Python爬虫进阶(三)爬虫之多任务模块(Ⅱ)
- 第四篇:Python爬虫进阶(四)爬虫之多任务模块(Ⅲ)
- 第五篇:Python爬虫实战之 爬取王者荣耀皮肤
- 第六篇:Python爬虫进阶(五)爬虫之多线程爬虫实战(爬取王者荣耀皮肤)
- 第七篇:Python爬虫进阶(六)爬虫之Scrapy初探(Ⅰ)
- 第八篇:Python爬虫进阶(七)爬虫之Scrapy初探(Ⅱ)
最近在知乎创建了一个新的Python技术圈子,在里面每天都会分享好玩有趣的Python知识,你如果对Python这门技术感兴趣的可以加入哦!交个朋友
Python技术 - 知乎www.zhihu.com















 2295
2295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









