






业务的需求
公司的运营部门需要统计自本年度1月1日—9月30日所有相关供应商的商品动销数据。
数据库导出的原始表格共计44857条数据。
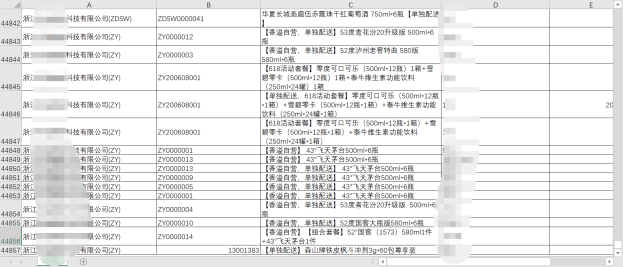
因数据较多,且不同供应商在售的商品数量不同,所以无法对表格进行固定行数的拆分。
需要针对不同供应商拆分成独立的子表格进行商品动销分析。
下图为拆分后的结果,每个供应商会是一个单独的Excel文件产出:
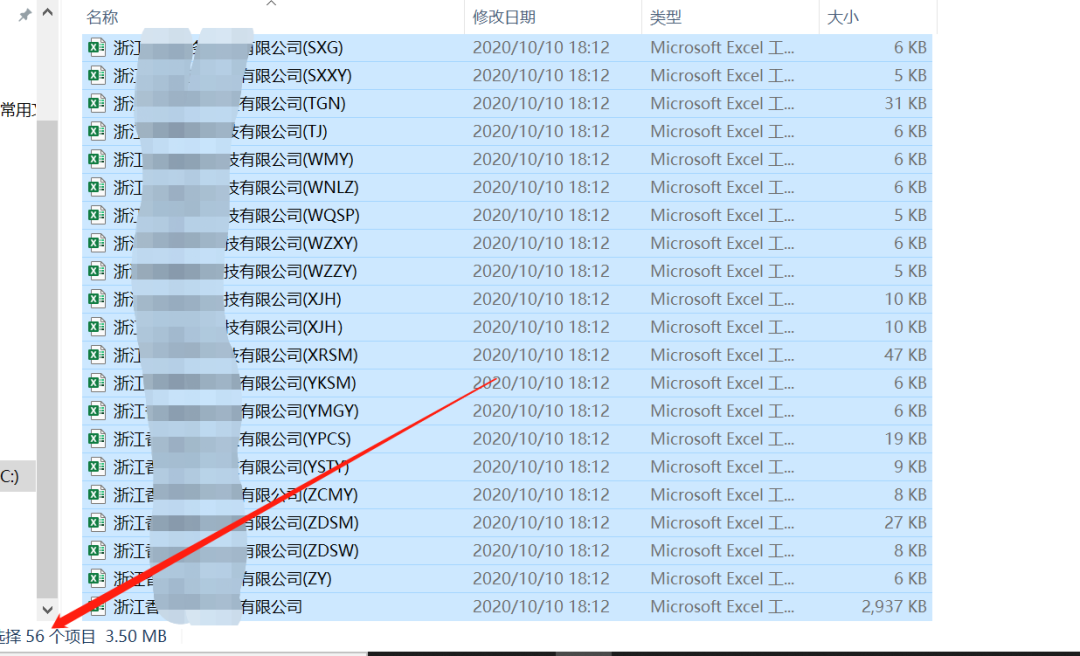
拆分后子表内容是单个独立供应商所有的商品动销数据:

Python代码的实现
1、读取原Excel文件
前几行例行公事,没啥可解释的,闭着眼睛写
对,这么简单的事情都要装逼,才能显示我们的与众不同
import pandas as pd
filepath = r'C:\Users\33589\Desktop\非烟销售数据汇总.xlsx'
df = pd.read_excel(filepath)
2、取出去重后的供应商列表
下一行:通过unique函数,拿到目标分类筛选的名称列表(内心So easy 啊!!!)
class_list = list(df['供应商'].unique())
class_list
3、产出每个供应商的Excel文件
通过for循环 + 布尔值让系统自动筛选同名行,并进行保存!搞定!!
for i in class_list:
df_cut = df[df["供应商"]==i]
df_cut.to_excel(r'.\%s.xlsx'%(i),encoding = 'utf-8')
后记
每当全年总结统计的时候,看到这么一个大的Excel表格,如果只是使用Excel来完成,带给运营的就是大量的重复筛选和统计劳动,简直傻眼。
使用Python却只需要几行代码,虽然每个供应商的行数不定,却可以快速导出到不同的文件实现分析,即使文件非常大也不会有问题,并且代码编写一次就可以多次运行,体现Python高性能+自动化+应对复杂场景的强大。
再次感谢“邋遢道人”提供真实案例的分享,也欢迎粉丝们提供真实案例投稿,欢迎哦^_^。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









