







一、多表连接查询
如下图,把学生和班级表进行合并,合并后就能知道每个学生的班主任都是谁。
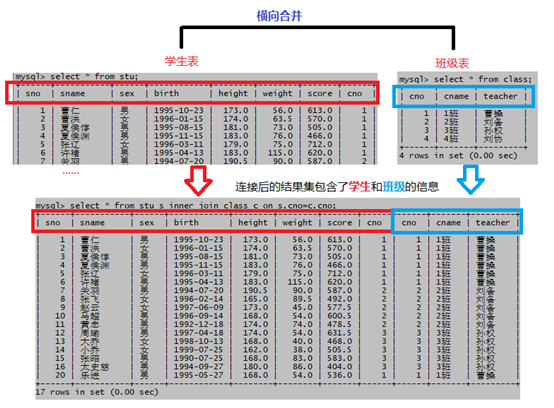
特点:
(1)将分散在多个表中的信息(列)横向合并在一起
(2)通常需要指明连接条件
只要2个或多个表中列的数据类型类似(例如:都为数值型、都为字符型等)就可以连接在一起,但通常会根据列的实际业务含义进行连接,这样才有实际意义
(3)多表连接查询和单表查询相比会耗费更多的系统资源
二、通过实例学习多表连接查询
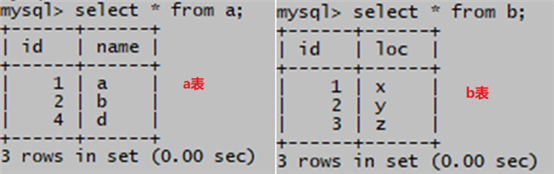
1、创建两个测试表a和b进行学习
create table a (id int, name char(10));
create table b (id int, loc char(10));表a内容:
insert into a values (1,'a');
insert into a values (2,'b');
insert into a values (4,'d'); (注意这里是4)表b内容:
insert into b values (1,'x');
insert into b values (2,'y');
insert into b values (3,'z');表如下:
2、语法
(1)不使用表别名
select table1.column, table2.column from table1 [inner|left|right] join table2 on table1.col1 = table2.col1;(2)使用表别名
select a.column,b.column from table1 a [inner|left|right] join table2 b on a.col1=b.col1;
3、分类
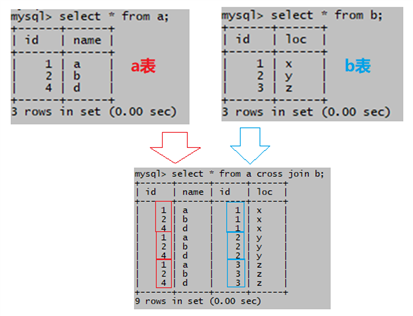
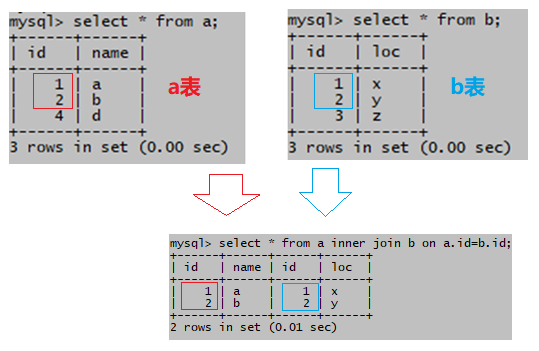
(1)交叉连接
不指定连接条件,结果集被叫做笛卡尔积,记录数为a表记录数m乘以b表记录数n
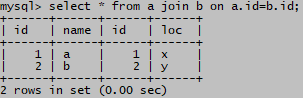
select * from a join b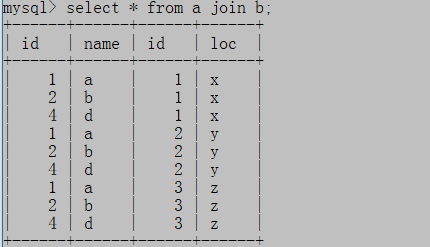 ;
;
交叉链接过程如图:
无连接条件,结果记录数= 3 * 3 =9
(2)内联接
指定连接条件,结果集包含符合连接条件的记录数
select * from a join b on a.id=b.id;链接a和b中id相等的行
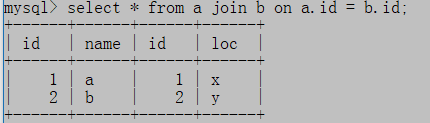
条件可以随便写:
例如:
select * from a join b on a.name=b.loc;结果:
![]()
内链接过程如图:
有连接条件,结果记录数= 3 * 3 =9
结果集显示符合连接条件的a表中的行,b表中的行,a表的id有1,2,b表的id也有1,2;如果不符合连接条件,结果集将无记录。
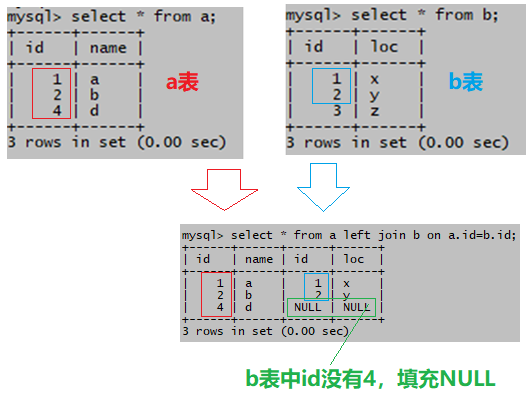
(3)左连接 (左外连接)
指定连接条件,结果集包含左表全部记录,右表中符合连接条件的记录和右表中不符合连接条件的记录(用NULL值填充)
select * from a left join b on a.id=b.id;以a所有元素进行连接,但是b中没有id=4的所以是null;

左链接过程如图:
有连接条件,左表的记录会全部显示
左指的是,上面语句中a写在了b的左边,结果集显示左表a的所有行,右表b中符合连接条件的行,a表的id有1,2,4,b表的id没有4,b表中不符合连接条件的行会用NULL值来填充
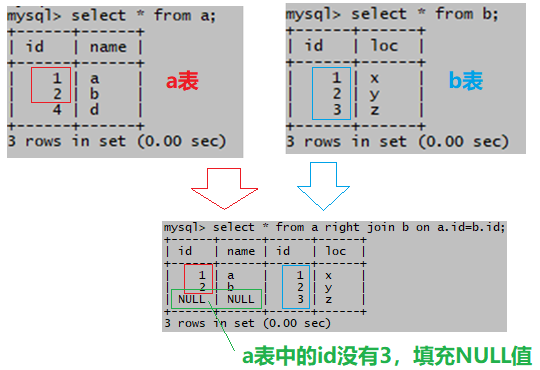
(4)右连接 (右外连接)
指定连接条件,结果集包含右表全部记录,左表中符合连接条件的记录和左表中不符合连接条件的记录(用NULL值填充)
select * from a right join b on a.id=b.id;以b所有元素进行连接,但是a中没有id=3的所以是null;

右链接过程如图:
有连接条件,右表的记录会全部显示
右指的是,上面语句中b写在了a的右边,结果集显示右表b的所有行,左表a中符合连接条件的行,b表的id有1,2,3,a表的id没有3,a表中不符合连接条件的行会用NULL值来填充
4、多表连接查询-连接条件
多表连接条件可以分为等值和非等值两种
(1)等值连接条件
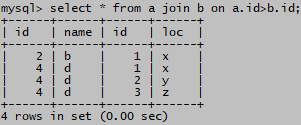
select * from a join b on a.id=b.id; 2条记录(2)非等值连接条件
select * from a join b on a.id>b.id; 4条记录
select * from a join b on a.id<b.id; 3条记录以上 a.id=b.id;a.id>b.id;a.id<b.id三种查询记录数加起来是9条
等于2个表交叉连接的数量

还有其他的写法,根据业务需求定,有实际意义最重要
select * from a join b on a.id between 1 and 3 and b.id<4;
四、多表连接查询练习
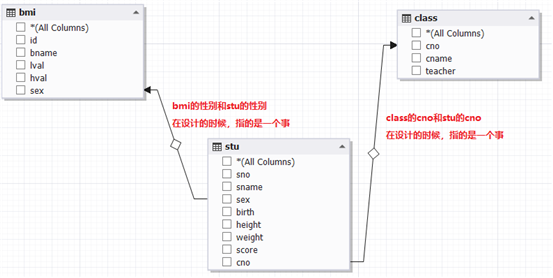
我们使用上次 的学生老师和体重指数表来更深的了解多表连接查询
例子1:显示学生的学号,姓名,性别,班号,班级名称以及他们的班主任姓名,按照班号和学号排序
select s.sno 学号,s.sname 姓名,s.sex 性别,s.cno 班号,c.cname 班名,c.teacher 班主任 from stu s inner join class c on s.cno=c.cno order by s.cno,s.sno;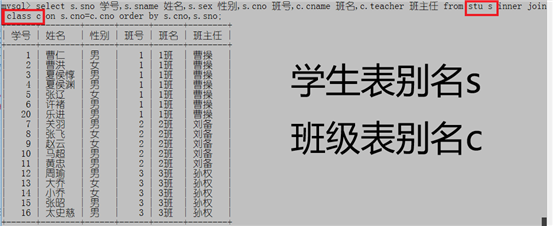
例子2:显示全部学生的学号,姓名,性别,班号,班级名称以及他们的班主任姓名,无班主任的显示‘暂无’,按照班号和学号排序
回顾一个知识点:
常用空值处理函数
ifnull(v1,v2) -- 如果v1为空返回v2,否则返回v1
isnull(expr) – 如果表达式为null空值,返回1,表达式非空则返回0
select s.sno 学号,s.sname 姓名,s.sex 性别,s.cno 班号,c.cname 班名,ifnull(c.teacher,'暂无') 班主任 from stu s left join class c on s.cno=c.cno order by s.cno,s.sno;
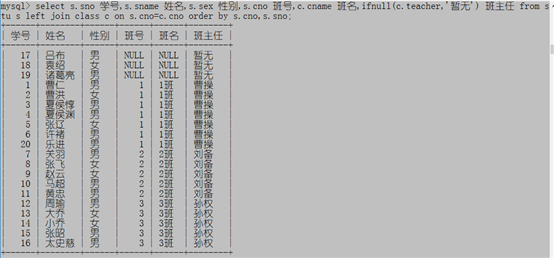
如果想让没有班级的学生排在后面可以使用isnull()
select s.sno 学号,s.sname 姓名,s.sex 性别,s.cno 班号,c.cname 班名,ifnull(c.teacher,'暂无') 班主任,isnull(s.cno) from stu s left join class c on s.cno=c.cno order by isnull(s.cno),s.cno,s.sno;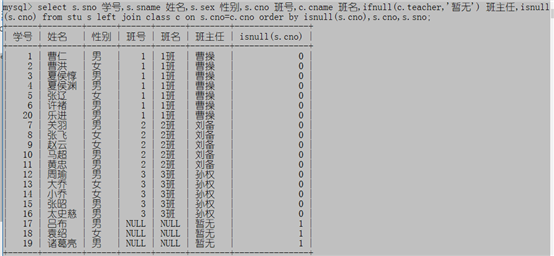
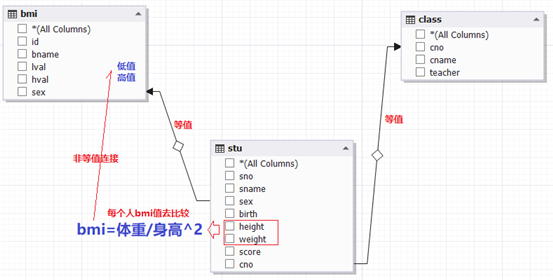
链接三个表:
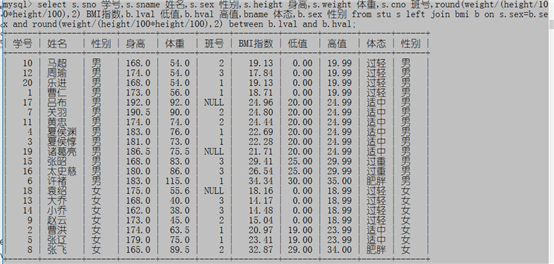
例子3:显示所有学生的学号,姓名,性别,身高,体重,班号,BMI指数(体重/身高^2),BMI表中对应的体态,低值,高值和性别
select s.sno 学号,s.sname 姓名,s.sex 性别,s.height 身高,s.weight 体重,s.cno 班号,round(weight/(height/100*height/100),2) BMI指数,b.lval 低值,b.hval 高值,bname 体态,b.sex 性别 from stu s left join bmi b on s.sex=b.sex and round(weight/(height/100*height/100),2) between b.lval and b.hval;这个题的关键就在于对bmi的判断,首先我们要找到突破点就是找到两个表的共性sex,然后根据bmi指数进行链接
例子4:基于例3的结果,把肥胖的同学和他们的班主任找出来
select s.sno 学号,s.sname 姓名,s.sex 性别,s.height 身高,s.weight 体重,s.cno 班号,round(weight/(height/100*height/100),2) BMI指数,b.lval 低值,b.hval 高值,bname 体态,b.sex 性别,c.cname 班名,c.teacher 班主任 from stu s left join bmi b on s.sex=b.sex and round(weight/(height/100*height/100),2) between b.lval and b.hval join class c on s.cno=c.cno where b.bname='肥胖';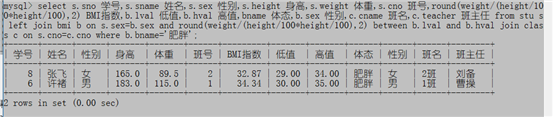
五、复合查询
复合查询指用集合运算符对多个查询结果集进行运算,产生新的查询结果集。
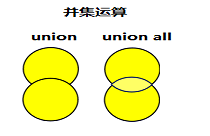
1、MySQL常用集合运算符包括以下2种:
(1)union,
对两个结果集进行并集操作,重复行只取一次,同时进行默认规则的排序
(2)union all
对两个结果集进行并集操作,包括所有重复行,不进行排序
2、实例
创建示例表:复制我们班级表第一行
create table class1 as select * from class where cno=1; 在新表中添加5班班主任董卓
insert into class1 values(5,'5班','董卓');查看:
select * from class;
select * from class1;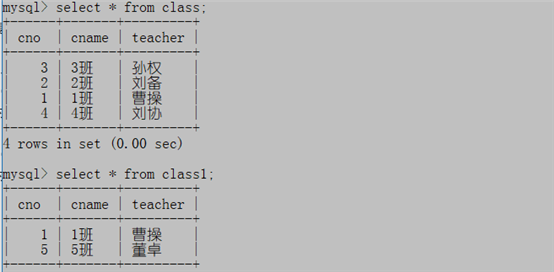
例1:求表class和class1的并集,重复记录只显示一次
select * from class union select * from class1;
默认排序为增序,顺序列1、列2、列3......
也可以自定义排序,order by写在语句的最后:
select * from class union select * from class1 order by 2 desc,3,1;
例2:求表class和class1的并集,重复记录重复显示
select * from class union all select * from class1;
例3:求表class和class1的交集
mysql无intersect集合运算符,交集运算可以通过多表连接实现
select * from class join class1 on class.cno=class1.cno;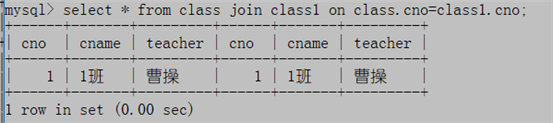
select c.cno,c.cname,c.teacher from class c join class1 c1 on c.cno=c1.cno;
例4:求表class和class1的差集,即显示class表中在class1表中没有的行记录
mysql无minus集合运算符,差集运算可以通过多表连接实现,
按照以下思路一步一步进行:
1. select * from class c left join class1 c1 on c.cno=c1.cno;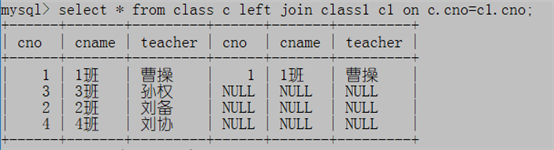
2. select * from class c left join class1 c1 on c.cno=c1.cno where c1.cno is null;只显示c1中没有的
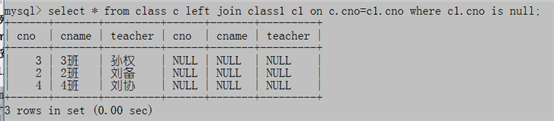
3. select c.cno,c.cname,c.teacher from class c left join class1 c1 on c.cno=c1.cno where c1.cno is null;只显示c1没有的,并只显示前3列。

例5:求表class1和class的差集,即显示class1表中在class表中没有的行记录
select c1.cno,c1.cname,c1.teacher from class c right join class1 c1 on c.cno=c1.cno where c.cno is null;或者
select c1.cno,c1.cname,c1.teacher from class1 c1 left join class c on c1.cno=c.cno where c.cno is null;左右连接是相对的,记一种就够了

六、子查询
1、SELECT 语句结构
SELECT 列1,列2 ... from TABLE_NAME WHERE 列 = 值 GROUP BY 分组列 HAVING 分组列 = 值 ORDER BY 列上面‘列、table name、值’的位置还可以嵌套额外的SELECT语句(子查询),与外部SELECT语句(主查询)结合起来使用,用一个查询语句实现更为复杂的任务。那些嵌套的SELECT语句往往被称为子查询;子查询需要用括号( )括起来。
2、分类
(1)非关联子查询:子查询可以单独于主查询执行,仅执行1次,效率较高
(2)关联子查询:子查询不能单独于主查询执行,如果主查询有N行,子查询将执行N次,效率相对较低,但灵活度高
3、非关联子查询
例1:查询学生中哪些人比张飞的体重重?
select sname,weight from stu where weight>(select weight from stu where sname='张飞');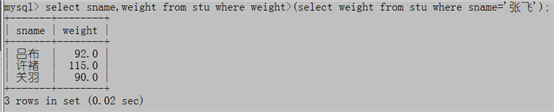
例2:2班3班中哪些同学的身高比1班的平均身高高?
select sname,height from stu where cno in (2,3) and height>(select avg(height) from stu where cno=1 );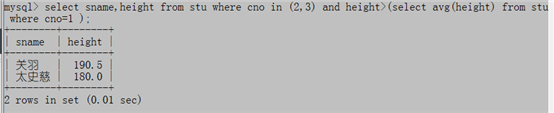
例3:每个班的高考状元都是谁?
select sname,score from stu where (cno,score) in (select cno,max(score) from stu group by cno)and cno is not null;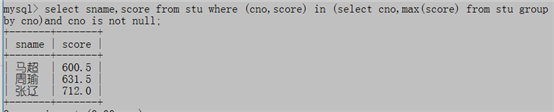
例4:哪些同学的体重比所有班的平均体重都重?
学习一个知识点:
>ALL运算符:比所有的值都大;
<ALL运算符:比所有的值都小
>ANY运算符:比最小的那个大就行;
<ANY运算符:比最大的那个小就行
select * from stu where weight>all(select avg(weight) from stu where cno is not null group by cno) and cno is not null;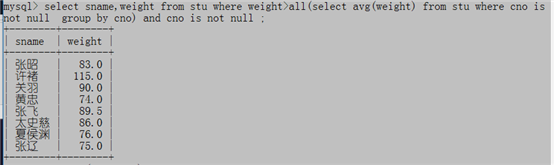
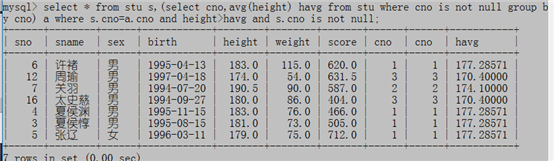
例5:哪些同学的身高高于本班的平均身高?
扩充知识点:之前学了join,这个是可以简写的,例如
select * from a join b on a.id=b.id;可以写为:
select * from a,b where a.id=b.id;
select * from stu s,(select cno,avg(height) havg from stu where cno is not null group by cno) a where s.cno=a.cno and height>havg and s.cno is not null;FROM后面的子查询也叫内联视图,
内联视图:(select cno,avg(height) havg from stu where cno is not null group by cno)代表一个假表
MySQL中这个内联视图子查询必须起个表别名,否则报错
例6:不用多表连接方式,列出3班学生姓名和3班的班主任
select sname 学生姓名,(select teacher from class where cno=3) 班主任 from stu o where cno=3;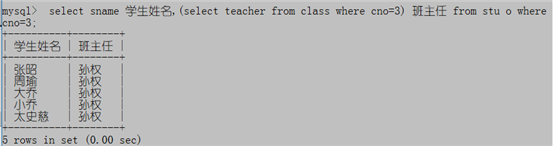
4、关联子查询
做这种题,一定要注意使用简称,要不句子一写长就不知道自己在写啥了。
例1:不用多表连接方式,列出每个学生的班号,姓名和其所在班的班主任
select o.cno 班号,o.sname 姓名,(select teacher from class i where i.cno=o.cno) 班主任 from stu o where o.cno is not null order by 1;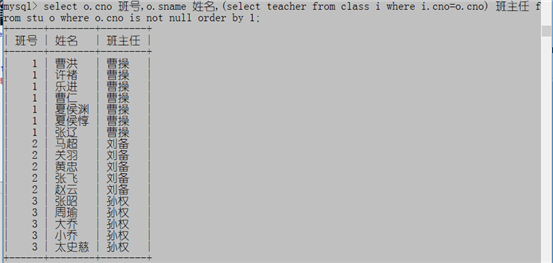
过程说明:
特点:子查询不能单独执行,主查询必须起个别名
单独执行:select teacher from class i where i.cno=o.cno; 报错,不知道o.cno的o表是什么,o是外部主查询的别名,脱离了外部查询,子查询执行不了

例2:不用多表连接方式,根据学生赵云的性别、身高和体重,查看他的bmi指标是否合适?
select sname 姓名,sex 性别,height 身高,weight 体重,(select bname from bmi i where o.weight/(o.height/100*o.height/100) between i.lval and i.hval and i.sex=o.sex) 体态 from stu o where o.sname='赵云';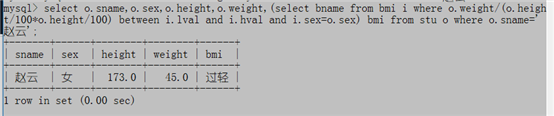
例3:使用关联子查询,在已分班学生中列出身高高于本班平均身高的学生。
select * from stu o where o.cno is not null and o.height>(select avg(height) from stu i where i.cno=o.cno);
练习:
1、体重最重的同学的班主任是谁?
(法1)select sname,weight,teacher from stu s,class c where s.cno=c.cno and weight=(select max(weight) from stu);
(法2)select sname,weight,teacher from (select * from stu where weight=(select max(weight) from stu)) a,class b where a.cno=b.cno;
(法3)select sname,weight,teacher from (select * from stu where weight>=all(select weight from stu)) a,class b where a.cno=b.cno;
(法4)select o.sname,o.weight,(select teacher from class i where i.cno = o.cno) teacher from stu o where weight = (select max(weight) from stu);
2、未分班的同学中哪些同学的体重比一些已分班的各班最重的同学重?
select * from stu where cno is null and weight>any(select max(weight) from stu where cno is not null group by cno);注意:运算符>any比>all相对宽松,比值列表中最小的那个大就行

3、从学生表和班级表中找出姓曹的人,并标明其角色,学生或者教师
select sname 姓名,'学生' 角色 from stu where sname like '曹%' union all select teacher,'教师' 角色 from class where substring(teacher,1,1)='曹';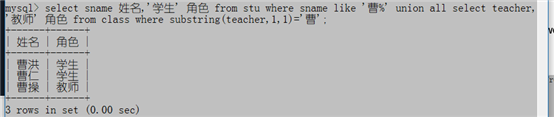
4、所有新同学外出实训,单位要求学校给每个同学的名字制作工牌,不同字的用料不同,价格不同,本着不能浪费的原则统计一下新生名字中有多少个‘张’,多少个‘曹’,多少个‘刘’,多少个‘羽’,没有的字不要做。
算出名字最多几个字
select max(char_length(sname)) 最多字数 from stu;用substring函数切割名字,用union all运算符叠加字,形成的结果集作为内联视图,再按照不同字分组统计每个字的个数
select zi 字,count(*) 数量 from (select substring(sname,1,1) zi from stu union all select substring(sname,2,1) from stu union all select substring(sname,3,1) from stu) t group by zi;但是这样会统计进去16个空字符,因为很多人名字只有两个字,所以截取第三个字的时候为空。
所以最终版

七、约束
1、约束的作用
约束(constraint)是数据库用来提高数据质量和保证数据完整性的一套机制
约束作用在表列上,是表定义(DDL语句)的一部分
约束其实我们之前就已经见过例如下图中的null、key等等
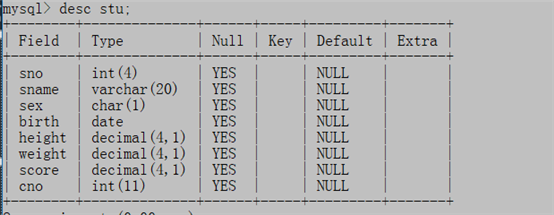
2、约束分类
(1)非空约束 (not null)
insert,update数据时是不允许空值(null)
(2)唯一性约束 (unique)
insert,update数据时不允许重值,可以允许空值,自动创建唯一性索引
(3)主键约束 (primary key)
非空约束 + 唯一约束。主键的列不允许有重值和空值,自动创建唯一性索引
(4)外键约束 (foreign key)
引用主键构成完整性约束。允许有空值,不允许存在对应主键约束的列所有数值以外的其它值
3、查看约束
desc table_name;
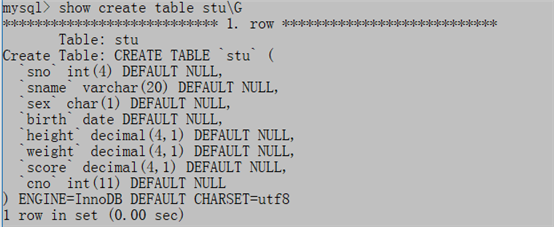
show create table table_name\G
show keys from table_name; 看不了非空约束
或者
show index from table_name;看不了非空约束
4、非空约束
非空约束用于确保其所在列的值不能为空值null
只有列级定义和追加定义
(1)语法
列级定义
create table t (id int not null,name char(10));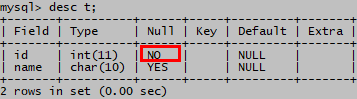
追加定义
alter table t modify name char(10) not null;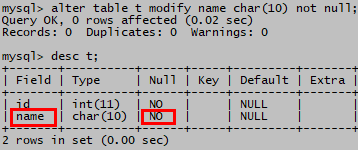
(2)测试
insert into t (id,name) values(null,null); 报错
insert into t (id,name) values(1,null);报错
insert into t (id) values(1); 报错,因为没有指定name值,默认用null填充
insert into t values(1,‘a'); 成功
允许为空
alter table t modify id int null;
设置默认值
alter table t modify id int null default 100;
alter table t modify name char(10) default 'abc';
insert into t (id) values(2); 成功,没有指定name值用默认值填充
drop table t; 删除t表,表列和行记录都没有了
5、唯一性约束
表列中不允许有重复值,但是可以有空值
(1)语法
列级定义
create table t1 (id int unique,name char(10));表级定义
create table t2 (id int,name char(10),unique(id));
追加定义
create table t3(id int,name char(10));
alter table t3 modify id int unique;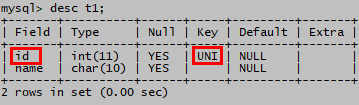
(2)测试
insert into t1 values(1,'a');
insert into t1 values(1, 'b'); 报错,id中不允许重值,2个1
insert into t1 values(null, 'b'); 成功,id允许有空值

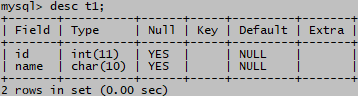
(3)删除unique约束
show keys from t1;
drop index id on t1;
desc t1;
drop table t1,t2,t3;
6、主键约束
(1)约束的定义方式
创建表时建立约束(事中)
建表之前就已经规划好了
列级定义:直接写在表头定义的时候
create table t (id int primary key,name char(10));
表级定义:放在表头后面primary key( ),括号里写谁谁就被约束
create table t (id int,name char(10),primary key(id));
修改表时追加约束(事后)
建表之后根据需要追加
追加定义
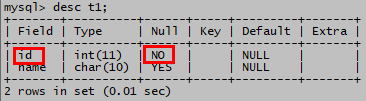
alter table t add primary key(id);(2)测试
insert into t1 values(1,'a');
insert into t1 values(1, 'a'); 报错,id中不允许重值,2个1
insert into t1 values(null, 'b'); 报错,id不允许有空值
(3)删除primary key约束
show keys from t1;
alter table t1 drop primary key;
show keys from t1; 自动创建的索引被删除
desc t1; 非空约束还在,没有被级联删除
alter table t2 add primary key(name); 失败,t2表已有主键,一个表不能有多个主键,可以建立非空+唯一约束代替
alter table t2 modify name char(10) not null unique; 成功
desc t2;drop table t1,t2,t3;
7、外键约束
引用主键构成完整性约束。外键允许有空值,不允许存在对应主键约束的列所有数值以外的其它值。MySQL自动创建非唯一性索引
(1)语法 (1个表)
表级定义
create table t1(id int,name char(10),pid int,primary key(id),foreign key(pid) references t1(id));
追加定义
create table t2(id int,name char(10),pid int);
alter table t2 add primary key(id);
alter table t2 add foreign key(pid) references t2(id);
(2)语法 (2个表)
表级定义
--先建立外键要引用的主表
create table c (cid int primary key,cname char(10));
-- 再建立包含外键的从表
create table s (sid int,sname char(10),cid int,foreign key(cid) references c(cid));追加定义
create table s1 (sid int,sname char(10),cid int);
alter table s1 add foreign key(cid) references c(cid);(3)测试
insert into s (sid,sname,cid) values(1,'张三',101);报错,因为c表中cid不存在100的值,当前c表中没有任何记录
insert into c (cid,cname) values(101,'1班'); c表中插入cid为101的值
insert into s (sid,sname,cid) values(1,'张三',101);再次插入成功
insert into s (sid,sname,cid) values(2,‘李四’,null); 插入成功,外键列可以有空值
(4)删除
删除s表cid列中的外键约束
先要找出s表cid上外键约束的名称
select * from information_schema.key_column_usage where table_name='s' and referenced_table_name is not null\G然后再删除s表cid上的外键约束
alter table s drop foreign key s_ibfk_1;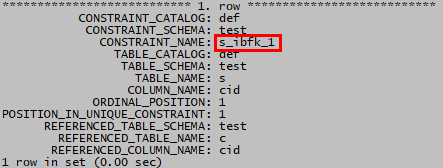















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









