






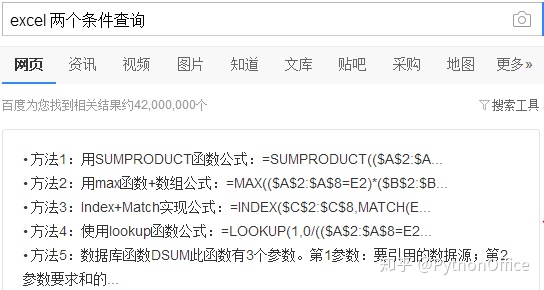
Excel自带查询并返回满足条件的值的函数,即大名鼎鼎,人见人爱,我们经常使用的vlookup,它可以搜索满足条件的元素,并返回指定列的值。比如有两个内容有差异的Excel表,都有一列是工单号,其中一个表有工单对应的数量,另一个没有此信息,我们想将工单数量也添加到另一个表,就可以使用vlookup函数,很快可以搞定。现实工作中,我们不只是面临单个条件的查询,往往面临2个或以上条件的查询,比如本例中的两条件查询。对于两个条件的查询,Excel也可以搞定。度娘一下,有如下方法:
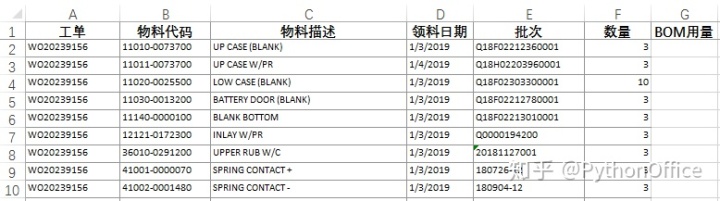
本例的要求是,根据“工单号”和“物料代码”作为2个查询条件,将“BOM用量”信息返回到“工单领取物料”表。

即将上面这个表(BOM用量)中的“BOM用量”列的数据根据“工单”及“物料编号”两个条件做匹配,然后返回到下表的“BOM用量”列。为什么要用两个条件呢?因为一个物料会有多个工单使用,而在每个工单中的单个用量是不同的,所以只用一个条件查询,会得到错误的结果。
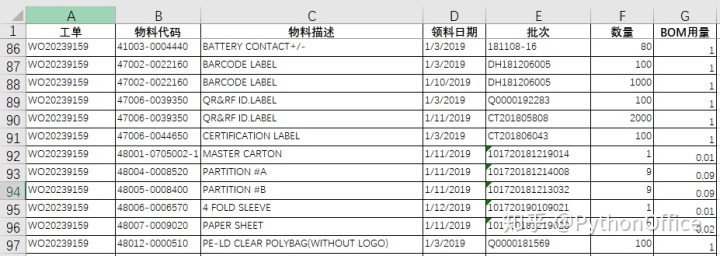
我使用了index+match函数来处理,3万多行数据,4核CPU足足跑了32分钟。盯着那个进度条,过程是让人焦虑的:

虽然终于完成查询,但极其考验人的耐性。现在试试Phtyon,看看效率能提升多少呢?
#1.从“BOM用量”表中提取信息
from openpyxl import load_workbook
wb = load_workbook("dataBOM用量.xlsx")
ws= wb.active
data = {} #用于储存提取的信息
for row in range(2, ws.max_row+1): #从第2行开始(第1行是标题)遍历工作表每一行,将需要的数据提取出来
work_order= ws['A' + str(row)].value #为工单号
material_pn = ws['C' + str(row)].value #为物料编号
BOM_usage = ws['F' + str(row)].value #BOM用量
#因为有两个查询条件,所以需要三层嵌套字典,以便形成如下这样的嵌套结构
#WO20239156 {'11140-0000100': {'BOM用量': 1}, '11010-0073700': {'BOM用量': 1}}
data.setdefault(work_order,{})
data[work_order].setdefault(material_pn,{'BOM用量':BOM_usage})还是用openpyxl模块读取工作簿,再读取工作表。此处只用到3个信息,即工单号,物料编号及BOM用量,分别提取出来,存入work_order,material_pn,BOM_usage,然后按嵌套字典的方式存入data字典。此处用到setdefault函数,字面意思就是为字典设定默认键值。以字典WO20239156 {'11140-0000100': {'BOM用量': 1}}为例,它最外层的键是WO20239156,这时会检查它是否已在字典的外层键中存在,若不存在,则设置为外层键;若已存在,则进入下一层,检查其包含的物料编号11140-0000100是否存在第二层键中,若不存在,则设置为第二层的键;若存在,则进入内层,并将“BOM用量”设置为内层键,将BOM_usage设置为其值。如此循环直到整个工作表3万多行数据全部读取完毕,并存入data。别觉得3万多行数据很多,对于Python来说就是小菜一碟,几十上百万行的数据都不在话下。
下面随机检查一下数据,看看有无问题。len(data)可查看字典data外层键的数量,其实就是对应的工单数,共733个,非常正确。然后再看看键值对及指定键的数据,都显示正常。
len(data)
>>733
for key,value in data.items():
print(key,value)
>>
WO20239156 {'11140-0000100': {'BOM用量': 1}, '11010-0073700': {'BOM用量': 1}, '68076-0000024': {'BOM用量': 1}...
data['WO20285088']['36012-0215900']
>>{'BOM用量': 1.99}数据获取完成后,就可以开始按两条件查询并写入到“工单领取物料”表中了。
%%time
wb1 = load_workbook("data工单领取物料.xlsx")
ws1= wb1.active
#遍历工作表的1,2列的所有行,只要某行中的1,2列数据匹配字典data中的工单号及物料编码,就在工作表的G列对应的行写入BOM用量的数据
for row in range(2,ws1.max_row+1):
wo = ws1['A' + str(row)].value
material = ws1['B' + str(row)].value
if wo in data.keys() and material in data[wo].keys():
ws1.cell(row=row,column=7).value=data[wo][material]["BOM用量"]
wb1.save("data工单领取物料.xlsx")>>Wall time: 1min 16s
三万多行数据的查询和写入,用时1分钟多一点点,比起Excel的32分钟,效率提升不止一点点。此处,先打开需要匹配并写入数据的表“工单领取物料”,然后将每行里的工单号和物料编号提取出来,并跟第一步获取的数据data中的工单号和物料编号进行比对,当两者都一致的情况下,将其对应的“BOM用量”的值写入该行第7列。此处用到if判断语句,and是指两个条件都必须满足,然后才执行数据写入。数据写完后,保存工作表。最后随机挑几个检查一下,没得问题,噢耶!收工!
如果您有需要处理的问题,可发邮件到我邮箱:donyo@qq.com,一起探讨处理。
以上在Jupyter notebook上完成,所用到的代码及Excel 资料已上传GitHub及百度网盘, 欢迎下载到本地随意玩。
Python版本:Python 3.6 64bit
操作系统:Windows 7
GitHub:Office_Automation_by_Using_Python
百度Pan:http://pan.baidu.com/s/1JjW_keLq0zsKN2l_BhV27A 提取码: z8nk
WX:Python操作Office软件高效工作















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









