





在Java中,我比较ORM熟悉的只有Hibernate和Mybatis,其他的并未实践使用过,在这二者之间我更喜欢Mybatis,因为它精简、灵活(毕竟我是上年纪的程序员,喜欢自己写SQL)。
刚才有提到Mybatis,但是这里的重点是介绍Mybatis-Plus,它是Mybatis的增强版,如果要了解Mybatis的细节的话请点击这里。
简介
据MyBatis-Plus官网介绍,MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。这看上去挺香的,所以必须得尝尝。
这里涉及到的环境、组件如下:
- MariaDB 10.3.10
- Windows 10
- IntelliJ IDEA 2019.3.1
- 64 bit JDK 1.8.0_231
- Spring Boot 2.2.3.RELEASE
- Lombok 1.18.10
- Knife4j 2.0.1
- Mybatis-plus 3.3.0
- Druid
Spring Boot 整合Mybatis-Plus
我之前一直是直接用的Mybatis,但是作为喜欢偷懒的人,当然得想办法来提高我们的效率,所以就想着用Mybatis-Plus来省去一些单表的CRUD操作再结合MyBatis-Plus配套的AutoGenerator代码生成器,就能为我们节省不少时间。
引入依赖包
首先,我们得引入Mybatis-Plus和mariadb-java-client等几个包:
com.github.xiaoymin knife4j-spring-boot-starter 2.0.1com.baomidou mybatis-plus-boot-starter 3.3.0org.mariadb.jdbc mariadb-java-client 2.5.3在application.yml配置我们的数据库连接信息
spring: datasource: driver-class-name: org.mariadb.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/nacos_config?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true username: root password: root minimum-idle: 5 maximum-pool-size: 50 auto-commit: true idle-timeout: 30000 max-lifetime: 1800000 connection-timeout: 30000 connection-test-query: SELECT 1这里我新建一个名为User的实体,具体属性如下:
@Data@Builder@TableName("users")public class User { private String username; private String password; private int enabled;}新建一个UserMapper接口:
public interface UserMapper extends BaseMapper {}在我们的启动类加上@MapperScan来指定我们的Mapper扫描目录:
@MapperScan("com.eyiadmin.demo.mapper")我新建一个单元测试,来试试我们的UserMapper的selectList:
@RunWith(SpringRunner.class)@SpringBootTestpublic class UserTests { @Autowired private UserMapper userMapper; @Test public void testUser() { List userList = userMapper.selectList(null); userList.forEach(System.out::println); }}会看到Mybatis-Plus为我取出的数据:
2020-01-20 09:44:14.125 TRACE org.apache.ibatis.logging.jdbc.BaseJdbcLogger.trace(BaseJdbcLogger.java:149) 2CNU7X5OLAUE004 --- [ main] c.e.d.m.U.selectList : <== Columns: username, password, enabled2020-01-20 09:44:14.125 TRACE org.apache.ibatis.logging.jdbc.BaseJdbcLogger.trace(BaseJdbcLogger.java:149) 2CNU7X5OLAUE004 --- [ main] c.e.d.m.U.selectList : <== Row: nacos, $2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu, 12020-01-20 09:44:14.131 DEBUG org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:143) 2CNU7X5OLAUE004 --- [ main] c.e.d.m.U.selectList : <== Total: 1User(username=nacos, password=$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu, enabled=1)我们再试试Mybatis-Plus为什么封装的Insert:
@Test public void TestUserInsert() { int row = userMapper.insert(User.builder().password("aaaa").username("bbbb").enabled(1).build()); Assert.assertEquals(row, 1); }可以看到日志:
2020-01-20 09:51:32.021 DEBUG org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:143) 2CNU7X5OLAUE004 --- [ main] c.e.d.m.U.insert : ==> Preparing: INSERT INTO users ( username, password, enabled ) VALUES ( ?, ?, ? ) 2020-01-20 09:51:32.036 DEBUG org.apache.ibatis.logging.jdbc.BaseJdbcLogger.debug(BaseJdbcLogger.java:143) 2CNU7X5OLAUE004 --- [ main] c.e.d.m.U.insert : ==> Parameters: bbbb(String), aaaa(String), 1(Integer)其他高端操作请阅读相关文档https://mp.baomidou.com/guide/quick-start.html
Spring Boot整合Druid数据库连接池
在Spring Boot 2.X默认使用了HikariCP作为数据库连接池,据说hikariCP性能最高(hikariCP>druid>dbcp>c3p0),但是我更喜欢Druid全面的功能和毫不逊色的性能。
开撸吧,首先当然还是引入我们的需要的Druid依赖包:
com.alibaba druid-spring-boot-starter 1.1.21接下来就是修改我们的的application.yml配置:
spring: datasource: driver-class-name: org.mariadb.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/nacos_config?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true username: root password: root ### 连接池配置 druid: initial-size: 50 max-active: 200 min-idle: 50 max-wait: 50 validation-query: SELECT 1可以看到我们的日志信息为:
2020-01-20 10:14:54.581 INFO com.alibaba.druid.pool.DruidDataSource.close(DruidDataSource.java:2003) 2CNU7X5OLAUE004 --- [extShutdownHook] c.a.d.p.DruidDataSource : {dataSource-1} closing ...2020-01-20 10:14:54.691 INFO com.alibaba.druid.pool.DruidDataSource.close(DruidDataSource.java:2075) 2CNU7X5OLAUE004 --- [extShutdownHook] c.a.d.p.DruidDataSource : {dataSource-1} closed现在我们增加一个Controller来获取Druid的监控数据:
@RestControllerpublic class DruidStatController { @GetMapping("/druid/status") public Object druidStat(){ // DruidStatManagerFacade#getDataSourceStatDataList 该方法可以获取所有数据源的监控数据,除此之外 DruidStatManagerFacade 还提供了一些其他方法,你可以按需选择使用。 return DruidStatManagerFacade.getInstance().getDataSourceStatDataList(); }}访问http://localhost:8080/druid/status可以得到一个json:
[{"Identity": 1914285129,"Name": "DataSource-1914285129","DbType": "mysql","DriverClassName": "org.mariadb.jdbc.Driver","URL": "jdbc:mysql://127.0.0.1:3306/nacos_config?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true","UserName": "root","FilterClassNames": [],"WaitThreadCount": 0,"NotEmptyWaitCount": 0,"NotEmptyWaitMillis": 0,"PoolingCount": 50,"PoolingPeak": 50,"PoolingPeakTime": "2020-01-20T02:26:22.466+0000","ActiveCount": 0,"ActivePeak": 0,"ActivePeakTime": null,"InitialSize": 50,"MinIdle": 50,"MaxActive": 200,"QueryTimeout": 0,"TransactionQueryTimeout": 0,"LoginTimeout": 0,"ValidConnectionCheckerClassName": null,"ExceptionSorterClassName": null,"TestOnBorrow": false,"TestOnReturn": false,"TestWhileIdle": true,"DefaultAutoCommit": true,"DefaultReadOnly": null,"DefaultTransactionIsolation": null,"LogicConnectCount": 0,"LogicCloseCount": 0,"LogicConnectErrorCount": 0,"PhysicalConnectCount": 50,"PhysicalCloseCount": 0,"PhysicalConnectErrorCount": 0,"DiscardCount": 0,"ExecuteCount": 0,"ExecuteUpdateCount": 0,"ExecuteQueryCount": 0,"ExecuteBatchCount": 0,"ErrorCount": 0,"CommitCount": 0,"RollbackCount": 0,"PSCacheAccessCount": 0,"PSCacheHitCount": 0,"PSCacheMissCount": 0,"StartTransactionCount": 0,"TransactionHistogram": [0, 0, 0, 0, 0, 0, 0],"ConnectionHoldTimeHistogram": [0, 0, 0, 0, 0, 0, 0, 0],"RemoveAbandoned": false,"ClobOpenCount": 0,"BlobOpenCount": 0,"KeepAliveCheckCount": 0,"KeepAlive": false,"FailFast": false,"MaxWait": 50,"MaxWaitThreadCount": -1,"PoolPreparedStatements": false,"MaxPoolPreparedStatementPerConnectionSize": 10,"MinEvictableIdleTimeMillis": 1800000,"MaxEvictableIdleTimeMillis": 25200000,"LogDifferentThread": true,"RecycleErrorCount": 0,"PreparedStatementOpenCount": 0,"PreparedStatementClosedCount": 0,"UseUnfairLock": true,"InitGlobalVariants": false,"InitVariants": false}]我们还可以打开stat-view-servlet,需要加入如下配置:
spring: datasource: druid: stat-view-servlet: enabled: true login-username: admin login-password: admin这是启动后,访问http://localhost:8080/druid/index.html页面就会跳转到登录页面,输入我们配置的用户名和密码admin/admin:
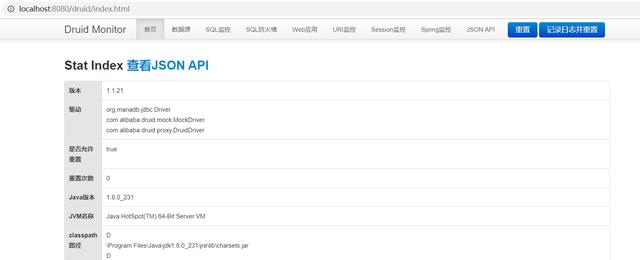
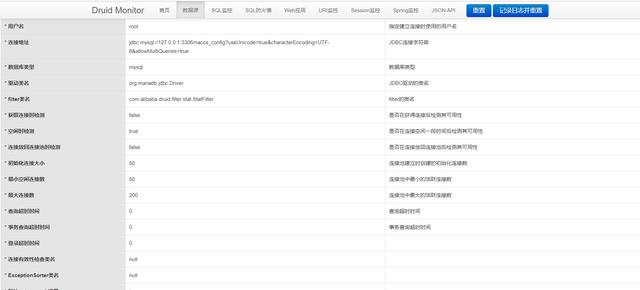
可以看到Druid提供的功能是比较全面的,另外在第三张图可以看到我们的相关参数,大家也可以参照这个来配置连接池。
MyBatis-Plus的代码生成器
Mybatis有Generator工具为我们提高编码效率,MyBatis-Plus也不示弱,它也提供有MyBatis-Plus AutoGenerator 。在上面的简单实体只有3个属性,假如有几十个属性怎么办呢?这时候AutoGenerator就可以帮我们一个大忙。首先引入所需包:
com.baomidou mybatis-plus-generator 3.3.0org.apache.velocity velocity-engine-core 2.1具体使用方式,可以去`mybatis-plus`官网查看详细教程
Knife4j的使用
这里我引入了Knife4j包:
com.github.xiaoymin knife4j-spring-boot-starter 2.新建一个SwaggerConfiguration类配置我们的Swagger:
@Configuration@EnableSwagger2@EnableKnife4j@Import(BeanValidatorPluginsConfiguration.class)public class SwaggerConfiguration { @Bean("createRestApi") public Docket createRestApi() { return new Docket(DocumentationType.SWAGGER_2) .apiInfo( new ApiInfoBuilder() //页面标题 .title("Demo Web Api文档") //创建人 .contact(new Contact("eyiadmin", "https://springfox.github.io/springfox/", "eyiadmin@163.com")) .version("1.0") .description("Demo Web Api文档") .build()) .select() //API接口所在的包位置 .apis(RequestHandlerSelectors.basePackage("com.eyiadmin.demo.controller")) .paths(PathSelectors.any()) .build(); }}新建一个名为UserController的Controller:
@RequestMapping("/v1/user")@RestController@Api(tags = "User API展示")public class UserController { @Autowired UserMapper userMapper; @GetMapping("/list") public ResponseResult> getUserList() { return ResponseResult.success(userMapper.selectList(null)); }}启动起来,访问localhost:8080/doc.html:
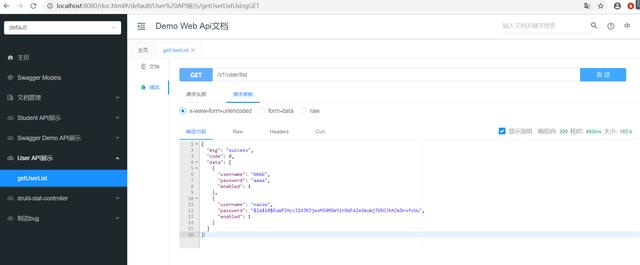
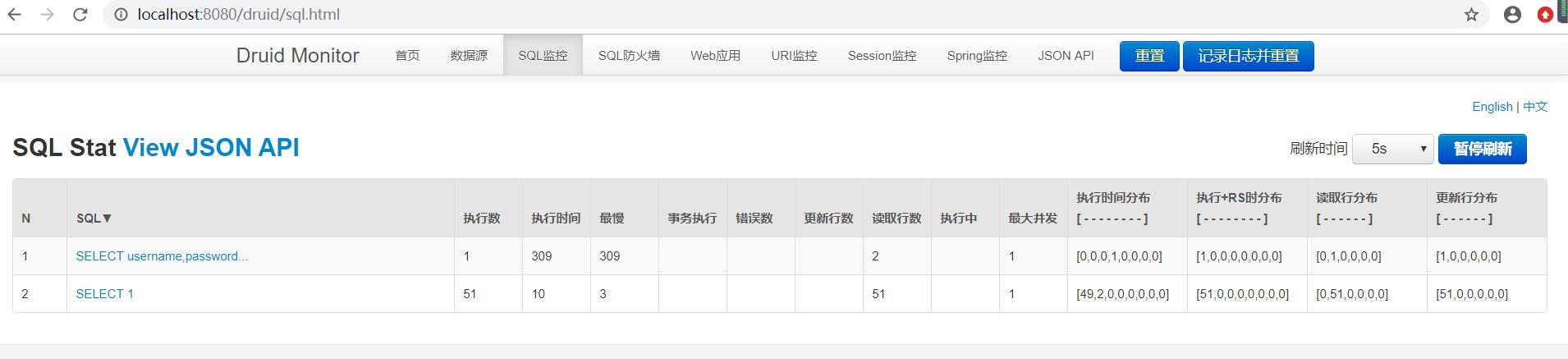
调用我们的接口,可以看到Druid监控到了我们SQL语句的执行情况
过于Swagger也可以看看我之前的一篇文章Spring Boot集成Swagger















 2798
2798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









