





此号为知乎“学弱猹”的头条号,任何文章均享有著作权,侵权必究。
微信公众号:cha-diary,二维码会影响推荐,就不放啦。
————————————————————————————————————————————
这是一篇专题文章。它是一篇针对RNN系列模型的系统梳理。我们计划通过这一篇文章,带大家深入理解目前在推荐和机器翻译中非常常见的注意力机制(Attention)的原理。就目前来看,唱衰人工智能的寒冬可能还为时过早,但AI这个工具的重要性,似乎再怎么强调也不为过。
考虑到公众号内已经有相当多诸如“一文看懂Attention”这样的文章,再写一篇似乎就有点班门弄斧了。所以如果写的不是很好,这里就求各位轻喷了,哈哈哈。
那我们开始吧。
参考文献
- Ian Goodfellow, et al. deep learning
- Dzmitry Bahdanau, et al. Neural Machine Translation by Jointly Learning to Align and Translate
- Sepp Hochreiter, et al. Long short-term memory
- Cho. K., et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation.
- 郑泽宇, et al. Tensorflow实战Google深度学习框架
目录
- RNN
- 计算图展开
- 反向传播与梯度计算
- 双向RNN简介
- LSTM
- Attention机制
- encoder-decoder架构与Attention机制的原理
- 添加Attention机制的机器翻译模型的更新方程
01-1
RNN
RNN的中文名是循环神经网络 (Recurrent Neural Network)。考虑到循环就是“一步一步的执行”,也就是说它非常常见于处理序列数据,因此在翻译中极为重要。比方说,对于下面两句话
- I went to Nepal in 2009.
- In 2009, I went to Nepal.
对于2009这个年份,它很显然是与位置无关的。无论这个年份在哪个位置,它都会代表同一个含义——我在2009年去了尼泊尔。这也是为什么翻译中,全连接神经网络被率先否定。因为它类似于将每一个单词看作一个特征,然后对于每一个特征分配一个参数。这个参数实际上就包含了位置的特有信息。也就是说对于全连接神经网络,如果输入这个特征进行训练的话,在它眼里,2009在两句话中对应的语言规则就不一样了,这显然不是我们希望的结果。然而RNN是一定程度上可以缓解这个问题的。
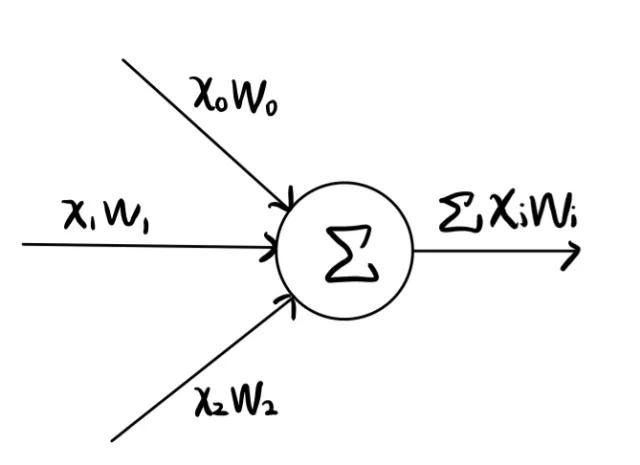
上图是全连接神经网络中某一个神经元的结构,可以看出来,每一个x_i就会对应一个参数w_i,这就表示参数会捕捉到位置的信息,在序列模型中一般是不被允许的。
我们从书上的角度出发来解释一下RNN的模型来源,再回过头看这个例子。
01-2
计算图展开
RNN来源于这么一个动态系统形式
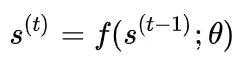
直观来看,我们所关心的变量 s 在第 t 步的值只会直接受到它上一步,也就是第 t-1 步的值影响。并且在宏观上还有一个超参数 heta 控制模型的状态。所以这就相当于“一步一步”求解的含义,你从第1步出发,可以通过这个函数不断地求值,得到你关心变量 s 的每一步的结果。
当然了,我们可以把它展开写成下面这种展开图的形式。
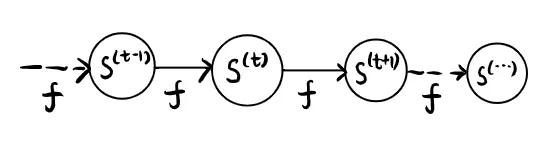
(计算图是神经网络中的一个术语,你只需要知道它是一张图就行。)
每一个节点代表一个时间的某一个变量的状态。这也是RNN最简单的一种形式。
稍微扩展一下,考虑在每一个时间点添加一个外部信号 x^{(t)} ,把模型修改为
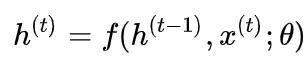
你可以看到,这可以类似于说,我们除了考虑“一步一步”的变量的推进,还会考虑每一个时间点上新的信息的输入。这里没有写成 s 而是写成了 h 的原因是,在RNN中,有这样的方法和规则的一般都是隐藏单元。
下面,我们祭出RNN最为经典的模型计算图。并且简单的说一下它的每一个元件的功能。
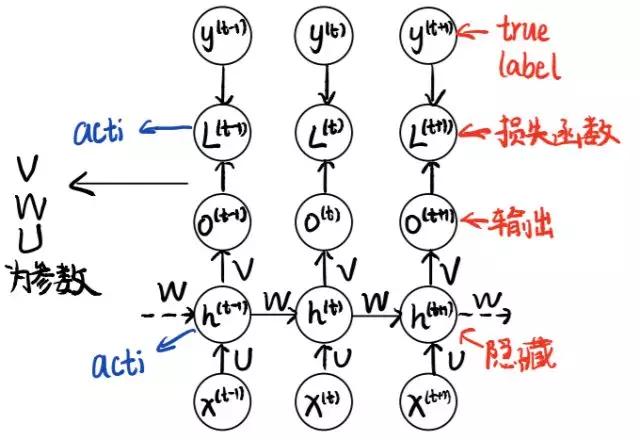
常见RNN计算图模型
这张图涉及到很多变量,大体上区分有随时间变化的时间变量,和不随时间变化的参数。可以结合笔记中的文字来看。
- 时间变量 x^{(t)} :一般是某一个特征的输入。比如说一个句子中的一个单词。
- 时间变量 h^{(t)} :隐藏节点,我们期待它能够抓住模型的特征,进而帮助训练出正确的结果。
- 时间变量 o^{(t)} :一般是某一个特征的模型输出。
- 时间变量 L^{(t)} :在某一个时间点的损失函数。最终的损失函数就是每一个时间点的损失之和。
- 时间变量 y^{(t)} :在某一个时间点的真实输出。损失函数也即是模型输出与真实输出的一个差距度量。
- 参数 U, V, W :通过反向传播不断训练的参数。
这里我们要说明的是,参数在这里就是矩阵。解释也并不困难,还是需要依赖全连接网络的前向传播结构。最最最简单的神经网络其实就是加权和,比方说下面这个图。
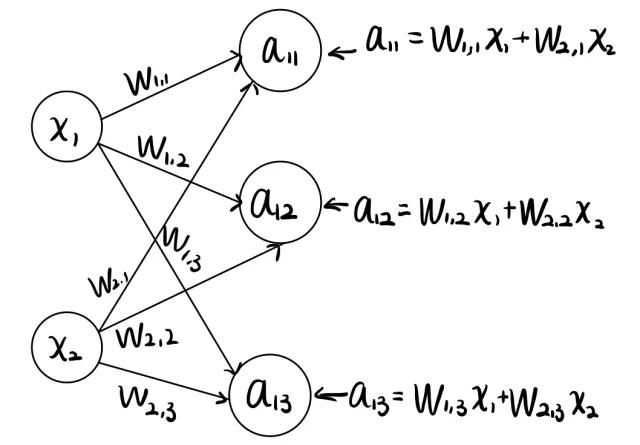
人工神经网络的一层
这是一个前向传播图,我们可以通过不同的参数 w_{ij} ,使得 x_i 的节点的值传送到 a_{1j} 这些节点上。你根据这线性组合的关系,容易发现,我们完全可以把这过程用矩阵乘法描述为
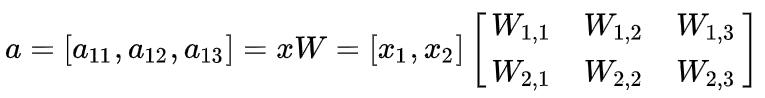
它还有一个名字,叫做人工神经网络(ANN)
我们介绍完参数的含义之后,你会发现,一个传播过程其实就是一个矩阵乘法。根据这个思想,我们也可以给出一个RNN模型的传播过程(更新方程)。
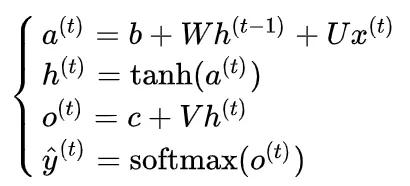
这里的 b,c 是偏置项,就有点类似于匀加速直线运动中,初始速度的含义。
其实我们仔细看这个公式会发现,我们只是把 h^{(t-1)} 与 x^{(t)} 的线性组合表示成为了 a^{(t)} ,但是如果你一直看下来,你可能会疑惑,为什么没有直接让它成为 h^{(t)} ,而是多做了一步双曲函数的嵌套?这牵涉到了人工神经网络的线性化局限。
你可以倒回去看一下上面那张人工神经网络的一层,如果你再加一层,结果会有什么好转吗?也许会,但是本质上,这个神经网络等于什么都没有动。为什么?考虑一下,假如说我们把那一层网络 a = x W 修改一下,加一层 y = aX ,那么组合一下就是 y = xWX ,你可以看出来 WX 其实就是另外一个矩阵而已,也就是说整个模型还是线性模型,本质上的表达能力没有丝毫的变化。因此我们为了制造非线性的内容,就考虑加上了激活函数。在这个模型中,我们加上的是双曲函数 anh 和软间隔 operatorname{softmax} 函数。其中softmax函数几乎在任何一个目前流行的模型中都能看到,它实际上是完成了一个归一化。
为了表示对它的尊重,我们写一下它的严格表达式。
Definition 1: softmax
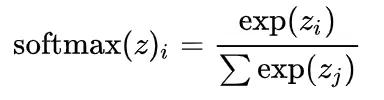
用同样的思路,你也可以理解与 o^{(t)} 有关的那个表达式。因为在网络中,它只与 h^{(t)} 有关,所以我们就只会写出 h^{(t)} 与偏置项两个部分。
01-3
反向传播与梯度计算
虽然现在tensorflow 2.0和老版本的keras让构建模型变得极为容易,但是如果你不想拘泥于做一个调包工程师,那么基本的原理还是需要康一康的。
在说明RNN的梯度计算之前,我们简单提一下反向传播 (back propagation)的含义和原理,它是任何一个神经网络优化的基础。
因为我们的神经网络每一步都是通过矩阵乘法计算,进而得到了所有的参数值,那么如何根据损失函数优化就成了问题。相信大家对梯度下降法不会特别陌生,那么我们做反向传播的意思,就是通过链式法则,使得每一步优化的梯度都能够很好地被求解出来。
对于这里,首先我们要明确,我们的损失函数为
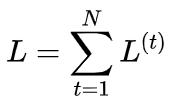
根据模型,我们输入 x^{(t)} ,然后得到 h^{(t)} ,然后再得到 o^{(t)} ,最后才有的 L^{(t)} 。所以如果要进行梯度下降的求解,就要先考虑 L^{(t)} 来优化我们的损失函数 L ,也就是要求 frac{partial L}{partial L^{(t)}} (就是偏导数,对着下面的公式图看一下),这个很简单就是1。
这一步结束之后,我们要计算的是损失函数基于 o^{(t)} 的梯度,所以写出来就是
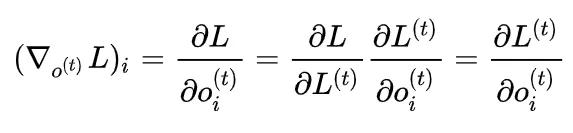
经典模型中,一般都会使用交叉熵损失函数。也就是说,我们要求
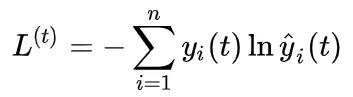
注意在这里, hat y_t 套了一层softmax激活函数,所以相当于会得到一个“所属每一个类的各个概率”,并不是严格的分类值0/1。而 y_t 虽然也是这样的含义,但是一般来说它都是真实的label,所以一般都是“某一类概率为1,其余类概率为0”这样的表示。
那么这样的话,我们考虑第 i 个分量,就有
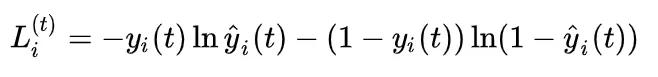
代入softmax函数就可以得到
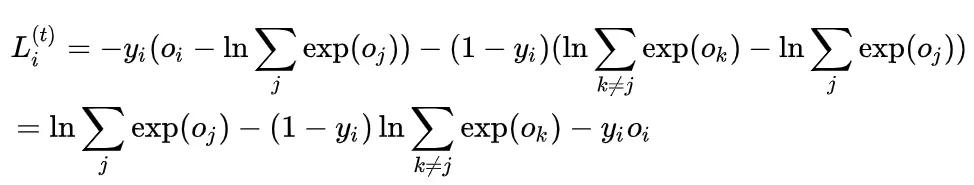
为了方便,我们略去了时间的标记 t。所以我们有
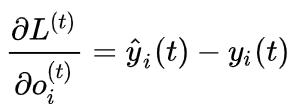
因为
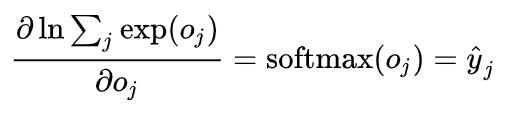
所以针对 o^{(t)} 我们的梯度计算好了,下面就需要进一步来看一下针对 h^{(t)} 的梯度。注意到 h^{(t)} 在时间上受到两个方向的参数制约:h^{(t+1)}, o^{(t)} 。因此根据链式法则,我们需要把它写成下面这个样子
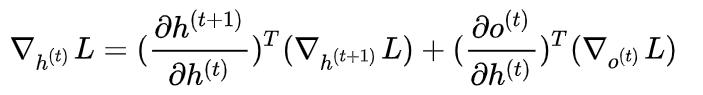
这里的几个部分中, abla_{h^{(t+1)}}L (abla是梯度的LaTeX符号) 是容易得到的,相当于取决于它的下一步,那么其实只需要关心最后一个时间点(假设为 au )对应的梯度就好。同样的 abla_{o^{(t)}}L 也是上面已经计算过的。至于两个偏导数,根据更新方程,我们可以注意到
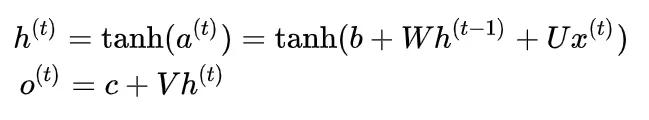
所以两个偏导数不难求,分别可以得到
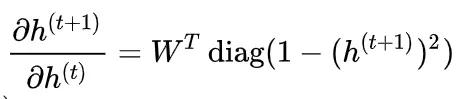
(包含元素 1-(h_i^{(t+1)})^2 的对角阵)和
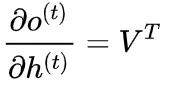
这是因为,单变元情况下
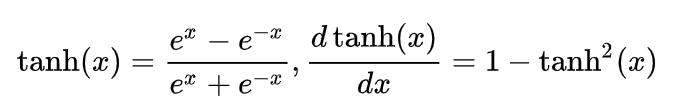
高维的情况做一点微小的变换,但是总体的结构是一致的。
至此,我们针对所有的内部节点的随时间变化的节点梯度都已经求好,但是固定的几个参数的梯度我们还没有求。需要注意的是,它们因为不随时间变化,所以实际上,会与每一个时间的对应相连的节点变量有关。比方说求解关于参数 c 的梯度,那么因为 o^{(t)} 中含有 c ,所以每一个 o^{(t)} 都会与 c 产生联系。因此它的梯度对应为
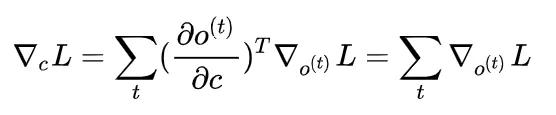
其它的结果我们也单独列在这里,不再证明。但是理解和求解的思路都比较一致。
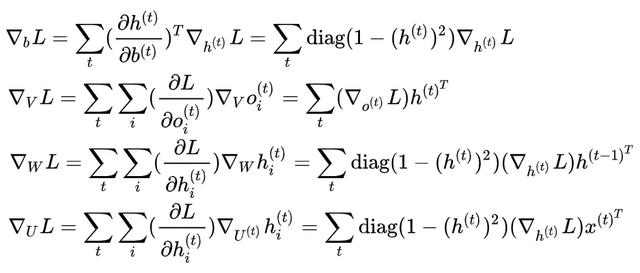
总结一下,就是说,对于一个深度学习模型,关键就是要给出它的更新方程和网络结构。有了这些,一切好说。
01-4
双向RNN简介
我们在介绍RNN的时候说,我们期望隐藏单元 h 能够抓住序列的信息。那么如果使用正常的RNN,实际的含义就是“我的这一步的信息由上一步决定”。但是问题在于,很多时候,你的这一步的信息,可能需要由下一步决定。那么这个时候,双向RNN就必须要使用了,我们直接放图。
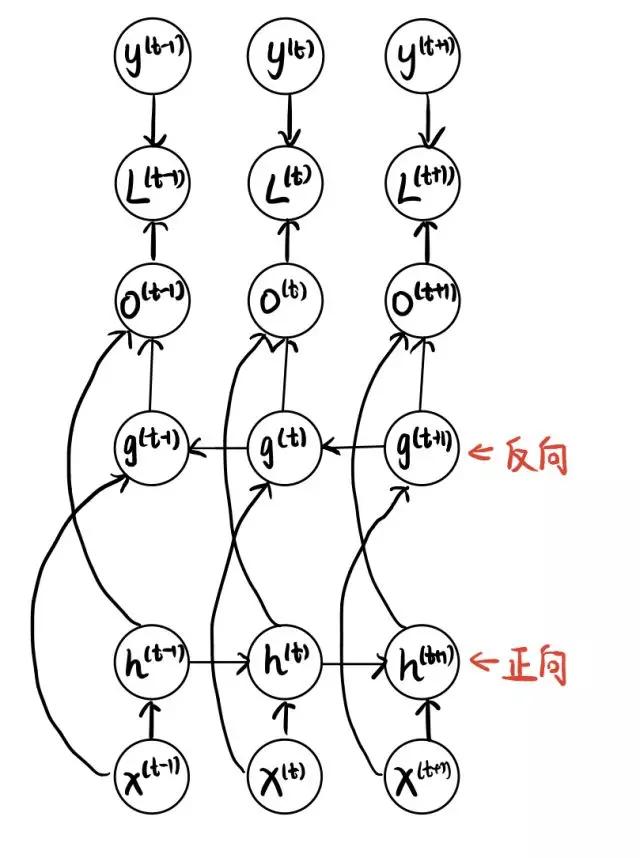
双向RNN
关键的地方我标记了出来,就是隐藏层多了一层,方向有所改变。其余部分没有特别的地方。
02-1
LSTM
LSTM提出是考虑到RNN模型的一个潜在缺陷:梯度消失,梯度爆炸。具体的你可以理解为,模型在不断迭代的过程中,梯度趋于0或者趋于无穷的一个现象。这当然不是我们喜欢的,因为这样子对于优化来说是致命的。除此之外,由于RNN只是“一步一步”的进行,因此如果一个位置上的某一个特征的结果需要依赖较远距离的另外一个特征,就会导致RNN的表现受到很大的限制。
LSTM的中文叫长短时记忆网络(long short-term memory),它是一个特殊的节点激活函数。神经网络必然是要祭出它的计算图的,我们这里也给出它的具体构造。
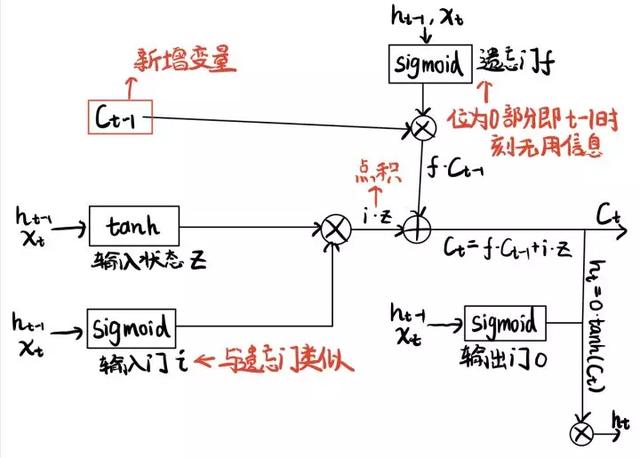
LSTM架构
点积是指点对点相乘,不是内积的意思,符号应该是circ
挺复杂的,我第一眼看我真以为它是代替RNN的又一个网络,并且它起名就真的有“网络”二字……
LSTM最重要的就是三个部分:输入门,遗忘门,输出门。直观理解,为了保证LSTM的信息抓取有效性,就需要遗忘门选择性的“遗忘”不重要的信息,而让输入门再“补充”正确的信息。每一个都是 operatorname{sigmoid} 激活函数,说明输出一个概率值。这是为了衡量“重要性”。变量中,接近于1那一个维度,对应的特征的重要性就很高。接近于0的那一个维度,对应的特征就不重要,如果做内积的话,对应的维度的信息就会被抹去,也就达到了“忘记”的目的。而这里为了辅助表示这种“筛选”,人工又添加了一个参数 c ,这个参数像是一个中间变量,虽然意义上和之前所说的RNN中的 h 一致,但是在这里为了保证各个门发挥作用,同时保证RNN中的变量不受影响,我们用 c 作了过渡。
说完了未知参数的含义,我们再来用这一个架构内的不同激活函数,说明LSTM的工作原理。
- 输入状态 z 的激活函数:同RNN内的激活函数 anh 节点。
- 输入门 i :套了一个,也就表示这一个时间点,对应的信息的保留程度,这个信息就对应 z 。所以它与 z 的点积,就是筛选“目前时间点”下,需要补充的信息。
- 遗忘门 f :一样的激活函数,它与 c_{t-1} 的点积,表示“上一个时间点”下,需要保留的信息,也就是需要遗忘的信息。
- oplus 节点:组合两部分信息,一部分是“目前时间点”下的补充信息,一部分是“上一时间点”的保留信息。
- 输出门 o :一样的激活函数,表示输出的部分需要的信息,它与 anh(c_t) 的点积就表明了输出中需要保留的信息。
最后,我们把LSTM中对应的更新方程列出来,结束这一部分。
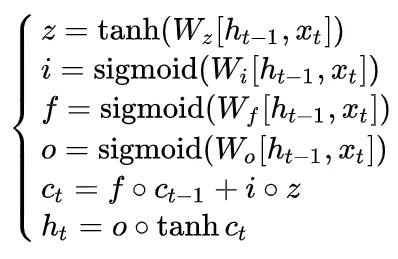
注意因为我们很多节点都输入了两个参数,因此常见的方法是把它们拼在一起然后在神经网络中做训练,当然了,这样的话这里的 W 的大小也就自然为 [2n,n] ,如果我们假设状态的维度都是 n 的话。
03-1
Attention机制
- Attention is all you need!
虽然这话不知道被多少篇paper轮着锤,但是Attention出现之后对于神经网络模型的革新确确实实起了相当大的作用。考虑到Attention机制本身是出现在机器翻译中的一个idea,我们会先介绍与机器翻译相关的RNN模型。
03-2
encoder-decoder架构与Attention机制的原理
这个算是机器翻译中一个非常有效的框架。为了方便大家对我们的背景首先我们要说一下什么是机器翻译。
机器翻译 (machine translation),其实就是给定两个语言的语料库,然后根据我们的语料库,对我们的翻译的句子进行编码,第一个单词就记为1,第二个单词就记为2。比方说abandon是英语单词中的第一个,那么对应1在模型中,这个特征值就为1,代表单词abandon。那么模型的目的就是输出正确的,在翻译语言下的编码,然后再根据语料库给出对应的语言的翻译。
那么encoder-decoder框架,顾名思义,模型被分为了两个部分:编码器 (encoder) 和解码器 (decoder)。首先编码器会输出一个固定长度的向量 c (语境向量, context vector),然后解码器就会根据这个向量和之前所有的,已经预测好的翻译词,来通过概率上推断的方法,判断下一个词应该是什么。
但是不知道你有没有发现传统的这样的架构问题在哪里?是的,问题就出在 c 上。我们在解码的时候,实际上每一个词究竟会依赖哪些词,是不能够一概而论的。所以传统的模型,实际上一直都是在用一个固定的 c 去监督“所有”的位置上的词语翻译。那么在句子十分长的时候,这个方法就会显得非常的累赘。那么Attention机制就是充分利用了人类的一个生物学局限:人类永远只能关注有限的视野。根据这个事实,我们不再关注 c ,而是针对每一个位置的预测,都给定一个单独的 c_i ,并且这个 c_i 是所有的隐藏状态的一个加权和。而这个权重如何设置,就充分体现“注意力”的智慧了。
OK,为了解释这个模型的含义,我们祭出它的架构图(没错,继续祭出计算图)
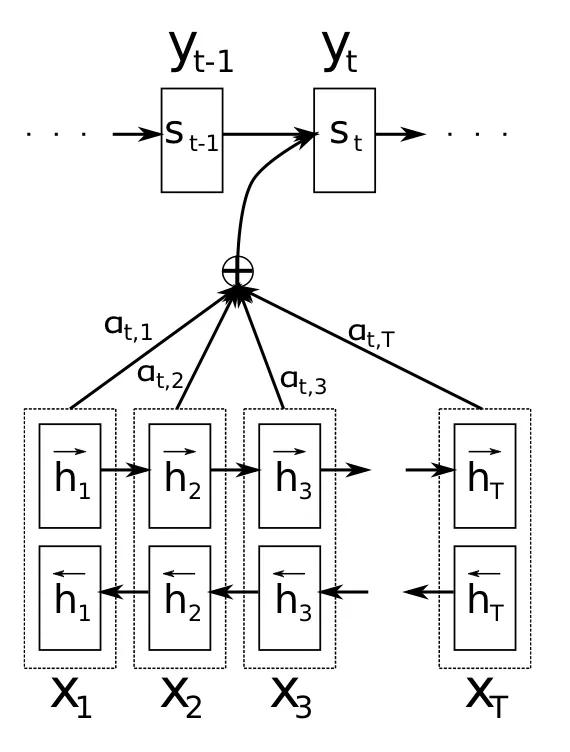
Attention机制下的seq2seq模型
我们可以看到,它的中间还是使用了一个 oplus 来过渡。下面这个部分就是我们的encoder,它是一个双向RNN, h 是隐藏状态,而上面的那个部分就是decoder,是一个标准RNN, s 是隐藏状态。
我们先从简单的decoder开始说。其实你可以看出来,根据我们的架构定义,decoder每一次预测都是一个条件概率预测,它会基于之前的预测的结果来预测下一个单词的翻译。所以写成条件概率就是
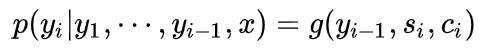
因为我们用标准的RNN作为decoder,所以在这里,实际上就是说, y_{i-1} 是上一个结果的输入, s_i 为隐藏状态, c_i 是对应的语境向量,注意这里的 i 是时间变量。
如果我们假设我们的输入的句子长度为 T_x ,那么因为这里的encoder是一个双向RNN,所以对应的它的隐藏状态维数也为 T_x ,而我们说Attention就是隐藏状态的一个加权和,所以实际上我们有
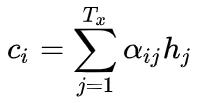
那么既然说 alpha_{ij} 是一个权重,你也许猜到了,我们可以先考虑构造一个量,衡量相关性强弱的量,然后使用softmax去构造出权重。
对,这就是
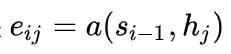
这个函数就是衡量输入的句子第 j 个位置(也就是 h_j )与输出的句子第 i 个位置(也就是 s_{i-1} )的相关性。你自然会发现,和之前固定的一个语境向量 c 不同,这里有了加权之后,模型就“有办法”找出与第 j 个位置相关性最高的,输入中的几个词语,而不仅仅是每一个句子的翻译,都要一下子把整个句子的信息都吃干净。不能一口吃成个胖子啊。
既然定义好了 e_{ij} ,对第二个分量 j 去做枚举,做softmax,就有
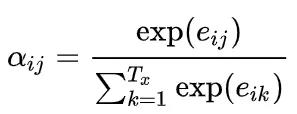
至此我们就完全的说清楚了图中的未知变量。
最后,论文中还提了一个细节,就是双向RNN中的隐藏状态是什么?我们知道双向RNN有两个方向:正向和反向。那么正向的话,模型学习会得到一个隐藏状态
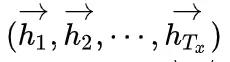
反向的话也会学到一个隐藏状态
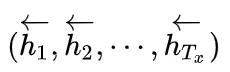
论文中定义我们的
实质上也就是把两个隐藏状态拼在了一起。
03-3
添加Attention机制的机器翻译模型的更新方程
还是一样,对于机器翻译模型,我们需要分开看encoder和decoder的架构。并且我们假设对应的 T_y 为输出的词向量的长度(之前我们有定义过 T_x 为输入的词向量的长度)。
需要提一嘴的是,论文中对RNN中的隐藏状态节点的激活函数作了修改,但不是LSTM,而是一个叫作门隐藏单元 (gated hidden unit)的东西 (Cho. K,参考文献4)。比方说在decoder结构中,就是
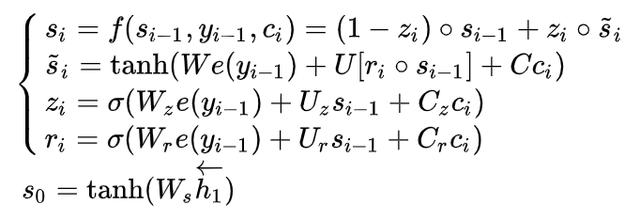
其中 W ,W_z, W_r in mathbb{R}^{n imes m}, U,U_z,U_r in mathbb{R}^{nimes n}, C,C_z,C_r in mathbb{R}^{n imes 2n} 。注意 n 是序列长度, m 是embedding规定的长度。There is a difference.
这里的 e(cdot) 是词嵌入 (embedding),你可以理解为一种转换,或者是数据挖掘中的数据预处理。把词语转为固定长度的一个特征,用于模型的训练。比方说在翻译中,我们输入会有
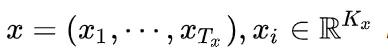
那么也就是说,句子长度为 T_x ,词汇量为 K_x ,而embedding就是通过一个矩阵,把它转为一个固定的 m 维向量。
如果你了解了LSTM的原理的话,其实直观上来看这里的 z_i,r_i 就扮演着“门”的作用(更新门与复位门),负责保留或遗忘信息。具体为什么设置成这样,感兴趣的可以参考原论文,这里不再赘述啦。
OK,那么针对encoder,其实也差不多。

反向也有一个类似的模型,也会需要一系列对应的参数。
W ,W_z, W_r in mathbb{R}^{n imes m}, U,U_z,U_r in mathbb{R}^{nimes n}。decoder只是比encoder多了一个 c_i 而已。
当然,最后还有一个就是我们的函数 a(cdot,cdot) (也就是alignment model,我也不知道咋翻译好)是啥子?论文中给出的答案是
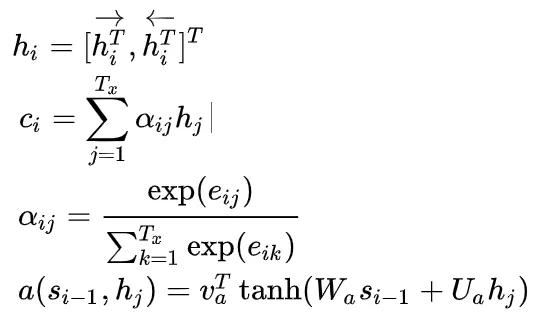
(为了方便阅读,把之前的几个结果也抄了下来)
你会发现也是简单粗暴的。
当这些模型都设置好之后,我们就会让它去跑很多很多的数据,然后不断地训练得到我们的所需要的参数。这也就是深度学习所“玄学”的地方:我只告诉你结构,所有的细节都靠模型自己去学,所以称它“炼丹”,似乎也并没有太大的问题。
至此,我们算是比较好的介绍完了Attention的原理和有趣之处。
小结
本节我们主要关注了以RNN为主导的序列深度学习模型。同时也重点介绍了广为流传的Attention机制。在下一节中我们会继续深入,对部分大厂的深度学习模型和应用场景做介绍,并深入了解Attention机制的潜在威力。
第一次涉足AI的科普文,有些难顶,望各位老铁给点面子!















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









