






一、 Sharding-JDBC介绍
引用官方的一段介绍
① Sharding-JDBC是一个开源的分布式数据库中间件解决方案。它在Java的JDBC层以对业务应用零侵入的方式额外提供数据分片,读写分离,柔性事务和分布式治理能力。并在其基础上提供封装了MySQL协议的服务端版本,用于完成对异构语言的支持。
② Sharding-JDBC是基于JDBC的客户端版本定位为轻量级Java框架,使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
③ Sharding-JDBC封装了MySQL协议的服务端版本定位为透明化的MySQL代理端,可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
不同于Mycat等中间件,Sharding-JDBC是在代码层面上进行读写分离,传统的读写分离是由开发者自行在业务逻辑中去实现读库与写库两种操作分离,而Sharding-JDBC则是进一步将这种实现剥离出来。对于开发者来说,无需自行去维护读库与写库操作,原有的业务逻辑无需做修改即可实现读写分离,整个过程是透明的。对于运维来说,也可以少维护一个中间件服务器。此方案适用于读多写少或读少写多场景,通过读写分离,可以较为显著地提升系统整体的吞吐量。下面,我将通过一个例子简单演示一下读写分离,源码放在最后一节,欢迎下载与指正。
二、搭建MySql主从复制库
推荐使用docker进行搭建,可参考别的博主写的这篇文章进行搭建
docker mysql 主从复制
下面内容是上述文章提到的关键点及关键命令,记录下来方便查阅,第一次搭建的童鞋建议按照上述文章或自行上网查找相关搭建教程进行搭建。
读写分离Mysql配置文件
主从库的配置文件都和下面的一样,唯一的区别在于配置中的server-id = 1值不能一样,可为任意数字
# Copyright (c) 2014, Oracle and/or its affiliates. All rights reserved.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
#
# The MySQL Community Server configuration file.
#
# For explanations see
# http://dev.mysql.com/doc/mysql/en/server-system-variables.html
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
[mysqld_safe]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
nice = 0
[mysqld]
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
lc-messages-dir = /usr/share/mysql
explicit_defaults_for_timestamp
log-bin = mysql-bin
server-id = 1
# Instead of skip-networking the default is now to listen only on
# localhost which is more compatible and is not less secure.
#bind-address = 127.0.0.1
#log-error = /var/log/mysql/error.log
# Recommended in standard MySQL setup
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# * IMPORTANT: Additional settings that can override those from this file!
# The files must end with '.cnf', otherwise they'll be ignored.
#
!includedir /etc/mysql/conf.d/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
关闭selinux
此步骤必须进行,否则在主库中执行show matser status命令返回的结果为空。
setenforce 0
1
运行主从数据库容器
docker run -d -e MYSQL_ROOT_PASSWORD=123456--name mysql-master -v /home/mysql/m.cnf:/etc/mysql/my.cnf -p 3306:3306 mysql:5.7 &&\
docker run -d -e MYSQL_ROOT_PASSWORD=123456--name mysql-slave -v /home/mysql/s.cnf:/etc/mysql/my.cnf -p 3307:3306 mysql:5.7
1
2
3
使用navicat等工具进入主库命令行模式
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '545347837';
show master status;
1
2
记住File、Position的值
使用navicat等工具进入从库命令行模式
change master to master_host='192.168.0.1',
master_user='backup',
master_password='123456',
master_log_file='mysql-bin.000003',master_log_pos=431,master_port=3306;
start slave;
1
2
3
4
5
上面的master_log_file与master_log_pos分别对应上一步的File、Position值
主从复制测试
在主库中随便建立一个数据库,观察在从库中是否也建立了一模一样的数据库
三、建立测试表(用户信息表userinfo)
在主库中建立一个数据库,名字随意,再建议一张用户信息表,两个字段,一个为id,一个为name,脚本如下
CREATE TABLE `userinfo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
1
2
3
4
5
四、POM.xml
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
com.czh
sharding
0.0.1-SNAPSHOT
jar
sharding
Demo project for Spring Boot
org.springframework.boot
spring-boot-starter-parent
1.5.12.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter-data-jpa
org.apache.tomcat
tomcat-jdbc
org.springframework.boot
spring-boot-starter-web
mysql
mysql-connector-java
com.zaxxer
HikariCP
io.shardingjdbc
sharding-jdbc-core
2.0.3
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
由于考虑到能够应用到读写分离的场景必定是对数据持久层性能要求有较高的要求,而数据库连接池在数据运输中扮演着重要的角色,在这种场景下它的性能对系统的吞吐影响就不能忽略了,故我在这里摈弃了tomcat自带的tomcat-jdbc连接池,而是使用业内公认速度最快、性能最好、并且是spring boot官方推荐使用的HikariCP作为数据库连接池。使用spring data jpa作为数据持久层框架。
五、配置文件
读写分离配置文件(sharding-jdbc.yml)
dataSources:
db_master: !!com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.10.100:3306/sphere?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
db_slave: !!com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.10.100:3307/sphere?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
masterSlaveRule:
name: db_ms
masterDataSourceName: db_master
slaveDataSourceNames: [db_slave]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这份配置文档是从官方网站获取的,值得注意的是,在Sharding-JDBC的连接池配置中,需要自行手动指定具体数据库实现类,如上述的!!com.zaxxer.hikari.HikariDataSource(类名前面的两个感叹号不能去掉,那是代表实现类的意思)。另外由于不同的连接池可能对于数据库配置字段有所区别,比如HikariDataSource的配置数据库地址字段为jdbcUrl,需要根据实际情况修改上述配置文档的字段。这份配置文档可支持一主多从配置。配置好后将此yml文件放到与application.properties同个目录下。
application.properties
无需进行配置,可保持空白。
六、编码
实体类
package com.czh.sharding.model;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
/**
* 用户信息实体
*@author 菜头君
*@date 2018年5月19日
*/
@Table(name ="userinfo")
@Entity
public class UserInfo {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private int id;
@Column
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
数据库操作接口
package com.czh.sharding.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.czh.sharding.model.UserInfo;
/**
* 用户表操作接口
*@author 菜头君
*@date 2018年5月19日
*/
public interface UserInfoRepository extends JpaRepository{
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
控制器
package com.czh.sharding.controller;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import com.czh.sharding.model.UserInfo;
import com.czh.sharding.repository.UserInfoRepository;
/**
* 用户信息控制器
*@author 菜头君
*@date 2018年5月19日
*/
@RestController
public class UserInfoController {
@Autowired
UserInfoRepository userInfoRepository;
/**
* 获取所有用户信息
*@return
*/
@GetMapping("/userinfo")
public List getUserInfos(){
return userInfoRepository.findAll();
}
/**
* 增加新用户
*@param name
*@return
*/
@GetMapping("/userinfo/{name}")
public UserInfo addUserInfo(@PathVariable String name){
UserInfo userInfo = new UserInfo();
userInfo.setName(name);
return userInfoRepository.save(userInfo);
}
/**
* 增加新用户后再立即查找该用户信息
*@param name
*@return
*/
@GetMapping("/userinfo/wr/{name}")
public UserInfo writeAndRead(@PathVariable String name) {
UserInfo userInfo = new UserInfo();
userInfo.setName(name);
userInfoRepository.saveAndFlush(userInfo);
return userInfoRepository.findOne(userInfo.getId());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
入口类
package com.czh.sharding;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.sql.SQLException;
import javax.sql.DataSource;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.util.ResourceUtils;
import io.shardingjdbc.core.api.MasterSlaveDataSourceFactory;
/**
* 入口
*@author 菜头君
*@date 2018年5月19日
*/
@SpringBootApplication
public class JdbcShardingApplication {
public static void main(String[] args) {
SpringApplication.run(JdbcShardingApplication.class, args);
}
/**
* 配置读写分离数据源
*@return
*@throws FileNotFoundException
*@throws SQLException
*@throws IOException
*/
@Bean
public DataSource dataSource() throws FileNotFoundException, SQLException, IOException {
return MasterSlaveDataSourceFactory.createDataSource(ResourceUtils.getFile("classpath:sharding-jdbc.yml"));
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
注意,数据源需要手动注入,直接使用MasterSlaveDataSourceFactory的创建数据源方式,将sharding-jdbc.yml传入后可创建出一个数据源,后面的操作就和普通数据源一样,但在内部里,该数据源就会自动将操作进行读写分离。
七、读写分离验证
通过上述步骤,我们就快速搭建了读写分离环境,在业务代码中,也完全没有对数据库操作做任何特殊处理,那么Sharding-JDBC真的能让人无感知地将操作路由到不同的数据库吗?理论上,读操作应该全部路由到从库中,而写操作则路由到主库中,根据官方介绍,若在同一线程中,执行完写操作又立刻执行读操作,为了避免由于主从同步延迟引起的数据不一致问题,Sharding-JDBC此时会强制将读操作也路由到主库中,为此我设计了以下三个测试用例来进行验证。
写操作验证
在这里我将从库关闭,主库保持开启,此时进行写操作,即新增用户信息操作。

可以看到从库已关闭
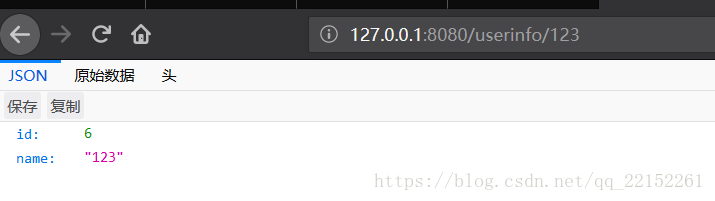
此时是可以进行保存操作的,那我们再从数据库读取数据试一下
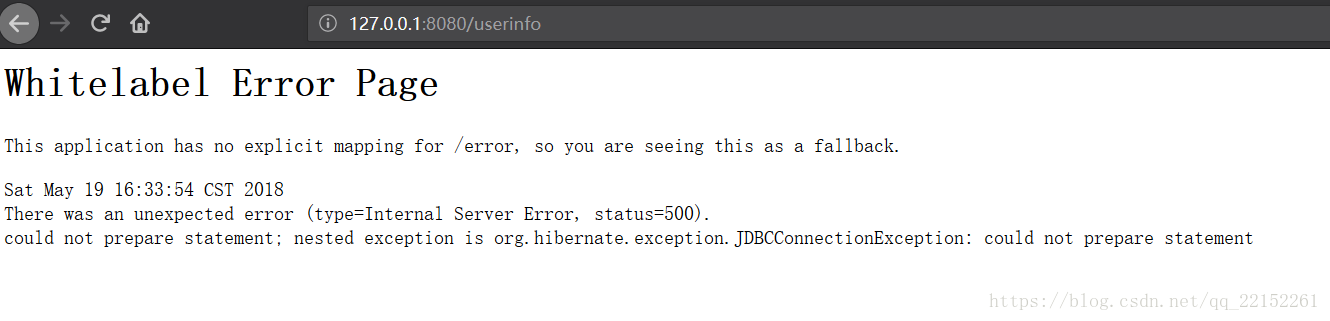
此时发现报错了,证明读取操作失败了,此步验证通过。
读操作验证
在这里我将主库关闭,从库保持开启,如下图。

此时进行读操作
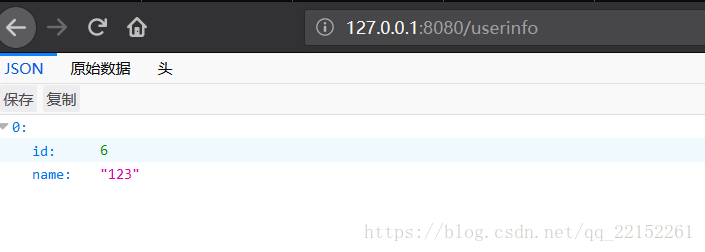
可以发现上面写操作验证中写入的数据能够被正常读取出来了,此时再调保存数据操作
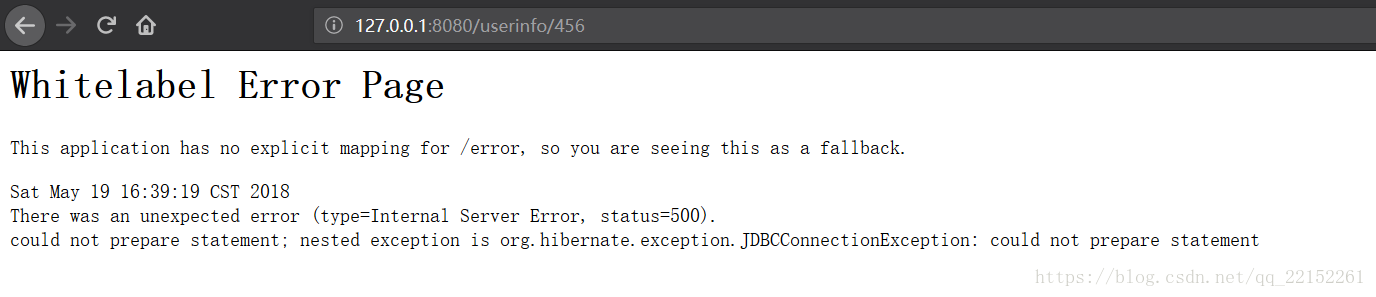
可以发现保存失败了,证明读操作都是走的主库。此步验证通过。
即时数据读写验证
我在控制器中设计了一个接口,该接口是保存用户信息后,立刻再查询此用户信息,而Sharding-JDBC为了避免读到脏数据,此时会强制把查询请求放到主库中,那么我再将从库关闭,主库开启,进行验证。

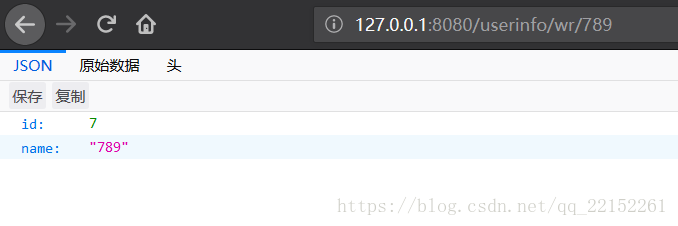
此时发现数据能够正常被保存以及查询出来,证明此时读写操作均走了主库,验证通过。
七、写在最后
Sharding-JDBC的功能不仅仅如此,它也可以支持更为复杂的分库分表操作,后续有机会我也写一篇文章来阐述。总的来说,这个工具还是十分好用,起码可以在不影响原有业务逻辑的前提下快速完成读写分离,且无需引入第三方的中间件服务器。但我觉得还有提升的空间,如当主从库任何一个库出现异常时,若此时能够将读写操作自动路由到其它正常的库,那就更完美了。
八、附录















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









