






概述
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统"。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
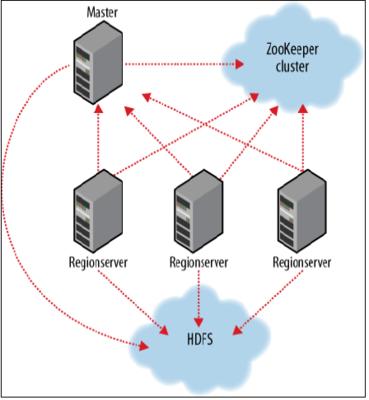
搭建环境
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
l Hadoop:1.1.2
HBase特性
- 强读写一致性:适合高速计数聚合操作
- 自动切分数据:分布式存储数据,随着数据增长进行自动切片
- RegionServer自动失效备援
- 与HDFS集成
- 支持MapReduce执行大规模并行操作
- 提供Java Client API
- 提供Thrift/REST API
- 针对大容量查询优化的块缓存和Bloom Fliter
- 可视化管理界面
劣势
- WAL的重新执行速度缓慢
- 故障恢复缓慢且复杂
- 主压缩会引起 I/O风暴
HBase使用场景
- 互联网搜索问题:爬虫收集网页,存储到BigTable里,MapReduce计算作业扫描全表生成搜索索引,从BigTable中查询搜索结果,展示给用户。
- 抓取增量数据:例如,抓取监控指标,抓取用户交互数据,遥测技术,定向投放广告等
- 内容服务
- 信息交互
HBase Shell命令行交互
启动Shell $ hbase shell
列出所有的表 hbase > list
创建名为mytable的表,含有一个列族hb hbase > create ' mytable' , 'hb'
在‘mytable’表的'first'行中的‘hb:data’列对应的数据单元中插入字节数组‘hello HBase’
hbase > put 'mytable' , 'first' , 'hb:data' , 'hello HBase'
读取mytable表 ‘first’行的内容 hbase > get 'mytable' , 'first'
读取mytable表所有的内容 hbase > scan ‘mytable'

示例
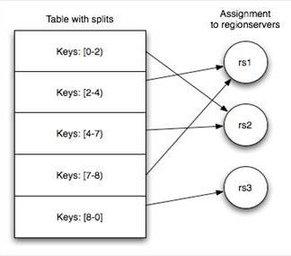
- HBase的RowKey设计
电信公司rowKey设计实例:
0.区域划分:划分100个区域,从00到99
CallerId + 201703 :hashcode % 100 = 00 -99
1.rowKey设计:rno + callerid + calltime[201702011212] + calleeid + duration ,这个地方注意:rno 等于callerid + calltime 的一部分
2.通话记录:
1)创建表:$hbase>create 'ns1:calllogs','f1'
2)创建单元测试。向表中添加数据。

















 6519
6519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









