





Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和Java 编写。Kafka 是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像 Hadoop 一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。
kafka 单机吞吐量为 10 万级别,topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源。
Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
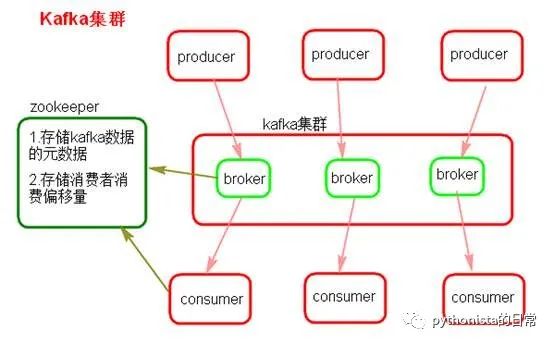
Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower,那么就要 care 数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了,因为如果某个 broker 宕机了,没事儿,那个 broker 上面的 partition 在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
在项目中使用 kafka-python 操作 kafka
1.创建 topic
from kafka.admin import KafkaAdminClient, NewTopic# kafka 集群信息bootstrap_servers = '127.0.0.1:9092'# topic 名称jrtt_topic_name = "T100117_jrtt_grade_advertiser_public_info"admin_client = KafkaAdminClient(bootstrap_servers=bootstrap_servers, client_id='T100117_gdt_grade_advertiser_get')topic_list = []# 6个分区,2个副本topic_list.append(NewTopic(name=jrtt_topic_name, num_partitions=6, replication_factor=2))res = admin_client.create_topics(new_topics=topic_list, validate_only=False)2.查看 kafka 的所有 topic
from kafka import KafkaProducer, KafkaConsumer# kafka 集群信息bootstrap_servers = '127.0.0.1:9092'consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers, )all_topic = consumer.topics()print(all_topic)3.kafka 生产者代码
from kafka import KafkaClient, KafkaProducer# kafka 集群信息bootstrap_servers = '127.0.0.1:9092'jrtt_value = {"dev_app_type": 2, "date": "20201111", "agent_id": "1648892709542919", "tenant_alias": "T100117", "data": {"first_industry_name": "\\u6559\\u80b2\\u57f9\\u8bad", "second_industry_name": "\\u4e2d\\u5c0f\\u5b66\\u6559\\u80b2", "company": "\\u7f51\\u6613\\u6709\\u9053\\u4fe1\\u606f\\u6280\\u672f\\uff08\\u5317\\u4eac\\uff09\\u6709\\u9650\\u516c\\u53f8\\u676d\\u5dde\\u5206\\u516c\\u53f8", "id": 1683030511810573, "name": "ZS-\\u7f51\\u6613\\u4e50\\u8bfb-001"}, "timestamp": time.time()}producer = KafkaProducer(bootstrap_servers=bootstrap_servers,value_serializer=lambda v: json.dumps(v).encode('utf-8'))# 将 json 格式的 jrtt_value 发送到 kafka 中producer.send(topic_name, value=jrtt_value)4.kafka 消费者
from kafka import KafkaProducer, KafkaConsumerbootstrap_servers = '127.0.0.1:9092'# 接收某个topic的生产者产生的消息内容consumer = KafkaConsumer(topic_name, bootstrap_servers=bootstrap_servers, )for index, msg in enumerate(consumer): # print("%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value))














 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









