






在数据科学前行的道路上,爬虫是一门必杀技,本文就爬虫所需具备的基础知识库进行了梳理。
1. 爬虫是什么?
网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或脚本。
2. 爬虫所需的基础知识库
2.1 Python基础学习
在python的基础学习中,有很多可以参考的教材,本次推荐作者在学习过程中用到的参考书。
PDF下载连接:https://chly.github.io/adjunct/用python做科学计算.pdf
网页链接:http://bigsec.net/b52/scipydoc/#id3
网页链接中有大量的实例代码,可以直接学习实践。
用Python做科学计算
2.2 Python urllib和urllib2库的用法
urllib和urllib2是学习Python爬虫最基本的库,利用这个库我们可以得到网页的内容,并对内容用正则表达式提取分析,得到我们想要的结果。
urllib库介绍
2.3 Python正则表达式
Python正则表达式是一种用来匹配字符串的强有力的武器。
正则表达式是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,就认为匹配成功,否则,该字符串就是不合法的。
这里附上Python官方讲解正则表达式的文档链接:https://docs.python.org/zh-cn/3/library/re.html
如下图所示:
正则表达式操作
2.4 爬虫框架Scrapy
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrapy架构图(绿线是数据流向)如下所示:
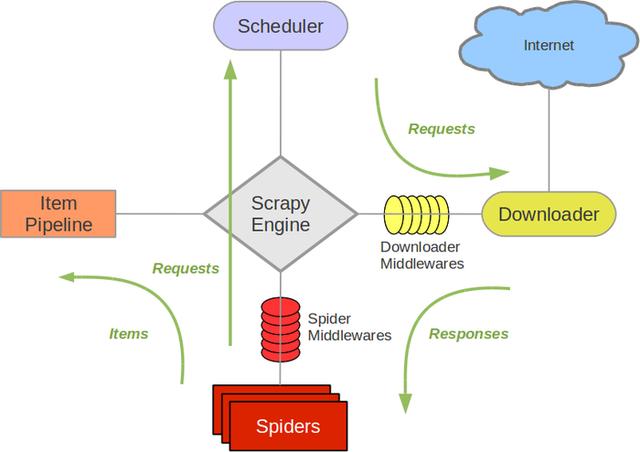
Scrapy架构图
Scrapy入门教程:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Scrapy入门教程

夜空中最靓的仔















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









