








一、乱码问题的出现
就以爬取51job网站举例,讲讲为何会出现“乱码”问题,如何解决它以及其背后的机制。
代码示例:
import requestsurl = "http://search.51job.com"res = requests.get(url)print(res.text)显示结果:
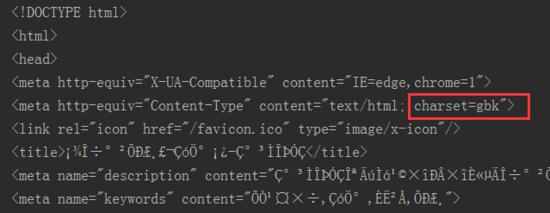
打印res.text时,发现了什么?中文乱码!!!不过发现,网页的字符集类型采用的gbk编码格式。
我们知道Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding 属性来改变它。
接下来,我们一起通过resquests的一些用法,来看看Requests 会基于 HTTP 头部对响应的编码方式。
print(res.encodi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









