







文章来源:拉钩数据分析训练营
1.Padas简介
- Python在数据处理和准备⽅⾯⼀直做得很好,但在数据分析和建模⽅⾯就差⼀些。Pandas帮助填补了这⼀空⽩,使您能够在Python中执⾏整个数据分析⼯作流程,⽽不必切换到更特定于领域的语⾔,如R(R一般应用于生物领域)。
- 与出⾊的 jupyter⼯具包和其他库相结合,Python中⽤于进⾏数据分析的环境在性能、⽣产率和协作能⼒⽅⾯都是卓越的。
- Pandas是 Python 的核⼼数据分析⽀持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas是Python进⾏数据分析的必备⾼级⼯具。
- Pandas的主要数据结构是 Series(⼀维数据)与 DataFrame (⼆维数据),这两种数据结构⾜以处理⾦融、统计、社会科学、⼯程等领域⾥的⼤多数案例。
- 处理数据⼀般分为⼏个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想⼯具。
- Pandas库安装:pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
2.Panas数据结构
Pandas是基于NumPy的升级,想要使用Pandas就必须要安装NumPy,调用时同理
import Numpy as np
import Pandas as pdpandas的数据结构常用的主要有两种:
Series(⼀维数据)与 DataFrame (⼆维数据)
当然Pandas也支持三位数据和四维数据,但是不常用,主要了解一位数据和二维数据。
2.1.Series
pd.series(data,index,dtype,name,copy)
Series是一维的数组,和NumPy数组不一样:Series多了索引
主要有以下几个参数
data:数据
index:定义行索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的个数要相等。
dtype:定义数据类型,参数接收值为str('int','float16','float32'.....),未指定的话会根据我们输入的数据自动识别。
name:定义系列名称(列名),参数接收值为str。
copy:复制输入数据,参数接收值为bool,默认为False。
其中我们经常设置的参数为data,index,以及dtype,
series常用创建方式有三种:
1)只输入data参数不设置索引:
l = np.array([1,2,3,6,9])
s1 = pd.Series(data = l)
display(l,s1)0array([1, 2, 3, 6, 9])
0 1
1 2
2 3
3 6
4 9
dtype: int32
2)按列表指定索引:
s2 = pd.Series(data = l,index = list('ABCDE'),name='a',dtype = 'float64',copy='False')
s2A 1.0
B 2.0
C 3.0
D 6.0
E 9.0
Name: a, dtype: float64
3)按字典键名指定索引
s3 = pd.Series(data = {
'语文':149,'数学':130,'英语':118,'文综':285,'Python':122})
s3语文 149
数学 130
英语 118
文综 285
Python 122
dtype: int64
2.2.DataFrame
pd.DataFrame(
data:数据
index: 定义行索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的第一维度维度尺寸要相等。
columns: 定义列索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的第二维度维度尺寸要相等。
dtype: 定义数据类型,参数接收值为str('int','float16','float32'.....),未指定的话会根据我们输入的数据自动识别。
copy: 复制输入数据,参数接收值为bool,默认为False。
)Series是一维的,功能比较少,DataFrame是二维的,多个Series公用索引(列名),组成了DataFrame,像 Excel一样的结构化关系型数据。
DataFrame的两种创建方式
1)列表定义列索引:
df1 = pd.DataFrame(data = np.random.randint(0,151,size = (10,3)),
index = list('ABCDEFHIJK'), # 行索引
columns=['Python','Math','En'],dtype=np.float16) # 列索引
df1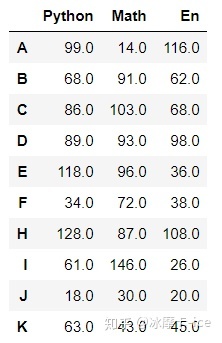
2)按字典键名指定列索引
df2 = pd.DataFrame(data = {
'Python':[66,99,128],'Math':[88,65,137],'En':[100,121,45]})
df2 # 字典,key作为列索引,不指定index默认从0开始索引,自动索引一样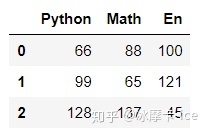
3.Pandas数据查看
常用的数据查看方法:
# 查看其属性、概览和统计信息
df.head(10) # 显示头部10⾏,默认5个
df.tail(10) # 显示末尾10⾏,默认5个
df.shape # 查看形状,⾏数和列数
df.dtypes # 查看数据类型
df.index # ⾏索引
df.columns # 列索引
df.values # 对象值,⼆维ndarray数组
df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值 http:// df.info() # 查看列索引、数据类型、⾮空计数和内存信息
import Numpy as np
import Pandas as pd
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
df
df.shape # 查看DataFrame形状(100, 3)
df.head(n = 3) # 显示前N个,默认N = 5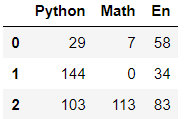
df.tail(3) # 显示后n个,默认N=5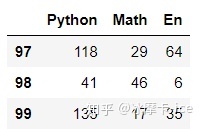
df.dtypes # 数据类型Python int32
Math int32
En int32
dtype: object
df.info() # 比较详细信息<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99 #共有三行,行索引从0到99
Data columns (total 3 columns): #共有三列
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Python 100 non-null int32 #Python列有100个非空值,数据类型为int32
1 Math 100 non-null int32 #Math列有100个非空值,数据类型为int32
2 En 100 non-null int32 #En列有100个非空值,数据类型为int32
dtypes: int32(3)
memory usage: 1.3 KB #占用内存1.3KB
df.describe() # 描述:数据条数、平均值、标准差、中位数、四等分位值、最大值,最小值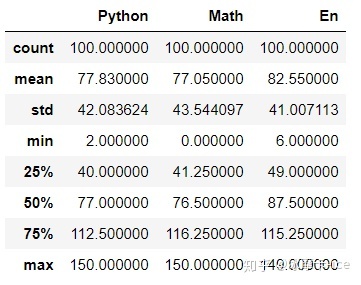
df.values # 查看值,返回的是NumPy数组array([[ 29, 7, 58],
[144, 0, 34],
[103, 113, 83],
.
.
.
[118, 29, 64],
[ 41, 46, 6],
[135, 17, 35]])
df.columns # 查看列索引Index(['Python', 'Math', 'En'], dtype='object')
df.index # 行索引 0 ~ 99RangeIndex(start=0, stop=100, step=1) #起始索引为0,终止所以为100,步长为1
4.Pandas数据输入和输出
Panda常用数据输入和输出有四种类型,csv文件、Excel文件、HDF5以及SQL读写,下面分别介绍:
4.1.CSV
import Numpy as np
import Pandas as pd
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
df # 行索引,列索引4.1.1.csv文件写入
df.to_csv('./data.csv',#输出文件名,注意路径正确,可以用相对路径或者绝对路径
sep = ',', #分隔符,默认是逗号,也尽量用逗号
index = True, # 保存行索引,默认为True,赋值False的话,输出文件不保存行索引
header=True) # 保存列索引,默认为True,赋值False的话,输出文件不保存列索引4.1.2.csv文件加载
pd.read_csv('./data.csv', #要读取的文件名,注意路径正确,可以用相对路径或者绝对路径
index_col=0, #设置读取的行索引,默认为None,不赋值的话会自动添加一列作为行索引
header ='infer') #设置读取的列索引,默认值为'infer',不赋值的话输出会默认把第1行作为列索引展示注意:
1.index_col参数 --设置行索引
- 如果我们的文件没有行索引这一列的话,这个参数尽量不要设置,否则会把数据的第一列作为行索引;
- 而如果我们的文件有行索引这一列的话(一般在第一列),尽量设置这个参数为0,否则会把行索引作为数据的第一列,自动添加一列为行索引;
- 这个也可以赋值其他的索引(如12345..,比如这里赋值2的话,math这一列的值就会成为行索引),赋值哪个列索引,这一列的值就会变成行索引.
2.header参数 --设置列索引
- 如果我们的文件没有列索引这一列的话,一定要设置这个参数为None,否则会把数据的第一行作为列索引。
- 如果我们的文件有行索引这一列的话(一般在第一列),尽量设置这个参数或者设置为'infer',否则会生成一个从0开始的递增数列作为列索引
4.2.Excel
读写Excel之前,需要先安装两个库
读取Excel文件:pip install xlrd -i https:// pypi.tuna.tsinghua.edu.cn /simple
写入Excel文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









