





一、设计思想
shell排序,有的中文被翻译为“希尔排序”,我们姑且这么叫。希尔排序又称为"缩小增量排序",它是对直接插入排序方法的改进
希尔排序的基本思想是:先将待排序的记录序列分割成若干个子序列,然后分别进行直接插入排序,待整个排序的记录基本有序时,在对全体记录进行一次直接插入排序。具体做法是:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组,即将所有距离为d1倍数序号的记录放在同一个组中,在各个组内进行直接插入排序;然后取第二个增量d2(d2
二、算法实现
例如,有10个数据,可使增量为5,序号1、5为一个子序列,2、6为一个子序列。。。。对这些子序列排序后再缩小增量,重新划分子序列进行排序,直到增量为1时结束排序过程
下面以一组待排序的数据演示希尔排序过程,假设有8个需要排序的数据序列如下:
69 、 65 、 90 、 37 、 92、 6、28 、54
使用希尔排序过程如下:
(1)首先使用元素总量的一半(4)作为增量,将数据划分4个子序列。对这4个子序列分别进行排序,其中第2、6和第3、7子序列需要进行数据交换。交换后得到第1遍排序的结
1 2 3 4 5
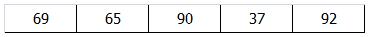
2 3 4 5 6

3 4 5 6 7
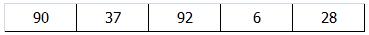
4 5 6 7 8

65和6交换;90和28交换
第一趟的结果: 69 、6、 28、 37、 92、 65、 90、 54
(2)接着将增量缩小一半(值为2)重新划分子序列,得到2个子序列。对这2个子序列分别进行排序,得到第2遍排序后的结果
69和28交换;92和90交换;65和54交换
第一趟排序的结果: 28 、6、 69 、37 、90 、54 、92 、65
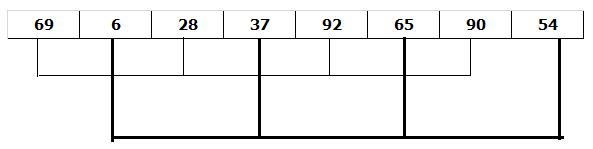
(3)再次缩小增量(值为1),此时所有数据构成1个序列,对该序列使用直接插入排序,得到最后排序结果
6 28 37 54 65 69 90 92
Java代码如下(C/C++代码类似大家自行修改):
public static void main(String[] args) {
int a[]= {69,65,90,37,92,6,28,54};
int n = 8 , d=0 , i =0 , j = 0 , x = 0;
d= n /2;//计算第1次的增量
while( d >= 1)//循环至增量为1时结束
{
for( i = d ; i < n ; i++)
{
x = a[i];//获取序列中的下一个数据
j = i - d;//序列中前一个数据的序号
//下一个数大于前一个数
while(j>=0 && a[j] > x)
{
//将后一个数向前移动
a[j + d] =a[j];
//修改序号,继续向前比较
j = j -d;
}
a[j + d] = x;//保存数据
}
d/=2;//缩小增量
}
for(int k=0;k<8;k++)
{
System.out.print(a[k]+" ");
}
}















 7264
7264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









