





本文翻译自Scheduling In Go : Part I - OS Scheduler
Prelude 序
This is the first post in a three part series that will provide an understanding of the mechanics and semantics behind the scheduler in Go. This post focuses on the operating system scheduler.
本系列包含三篇文章,会循序渐进的讲述Go调度程序内部的机制和原理。本文是第一篇,专注于操作系统调度程序。
Index of the three part series:
1) Scheduling In Go : Part I - OS Scheduler
2) Scheduling In Go : Part II - Go Scheduler
3) Scheduling In Go : Part III - Concurrency
Introduction 介绍
The design and behavior of the Go scheduler allows your multithreaded Go programs to be more efficient and performant. This is thanks to the mechanical sympathies the Go scheduler has for the operating system (OS) scheduler. However, if the design and behavior of your multithreaded Go software is not mechanically sympathetic with how the schedulers work, none of this will matter. It's important to have a general and representative understanding of how both the OS and Go schedulers work to design your multithreaded software correctly.
Go调度器的设计和行为,允许你的多线程Go程序,能够被更加有效和更加高效地执行。这要归功于Go调度程序对操作系统(OS)调度程序的协调机制。但是,如果你的程序设计和行为不能与OS调度程序协调一致,那一切将是徒劳。所以,了解OS和Go调度程序的工作原理,对于设计出正确的多线程软件是至关重要的。
This multi-part article will focus on the higher-level mechanics and semantics of the schedulers. I will provide enough details to allow you to visualize how things work so you can make better engineering decisions. Even though there is a lot that goes into the engineering decisions you need to make for multithreaded applications, the mechanics and semantics form a critical part of the foundational knowledge you need.
本系列文章将专注于高级别的调度程序机制和原理。我会提供足够的细节,使你可以有形象的感受,并作出更好的工程决策。虽然,对多线程程序做出工程决策,涉及到方方面面,但其机制和原理,仍是你所需基础知识的关键部分。
OS Scheduler 操作系统调度器
Operating-system schedulers are complex pieces of software. They have to take into account the layout and setup of the hardware they run on. This includes but is not limited to the existence of multiple processors and cores, CPU caches and NUMA. Without this knowledge, the scheduler can't be as efficient as possible. What's great is you can still develop a good mental model of how the OS scheduler works without going deep into these topics.
那些操作系统调度程序,都是复杂的软件。它们必须考虑运行它们的硬件的布局和设置。这包括但不限于多处理器和多内核,CPU缓存以及NUMA。没有这些知识,调度程序将无法尽可能高效。好在,你仍然可以在不深入探讨这些主题的情况下,为操作OS调度程序的工作方式建立良好的思维模型。
Your program is just a series of machine instructions that need to be executed one after the other sequentially. To make that happen, the operating system uses the concept of a Thread. It's the job of the Thread to account for and sequentially execute the set of instructions it's assigned. Execution continues until there are no more instructions for the Thread to execute. This is why I call a Thread, “a path of execution”.
你的程序是一系列需要依次执行的机器指令,为此,操作系统引入线程的概念。线程的工作,就是负责并顺序执行分配给它的指令集。线程中的指令会被一致执行下去,直到没有更多指令可执行为止。 这就是为什么我将线程称为“执行路径”。
Every program you run creates a Process and each Process is given an initial Thread. Threads have the ability to create more Threads. All these different Threads run independently of each other and scheduling decisions are made at the Thread level, not at the Process level. Threads can run concurrently (each taking a turn on an individual core), or in parallel (each running at the same time on different cores). Threads also maintain their own state to allow for the safe, local, and independent execution of their instructions.
你运行的每个程序都会创建一个进程,并且每个进程会分配一个初始线程。线程可以创建更多的线程。所有这些不同的线程彼此独立运行,并且调度决策是在线程级别,而不是在进程级别做出的。线程可以并发运行(每个线程打开一个内核),也可以并行运行(每个线程在不同内核上同时运行)。线程还维护自己的状态,以允许安全的、在自己内部、独立的执行其指令。
The OS scheduler is responsible for making sure cores are not idle if there are Threads that can be executing. It must also create the illusion that all the Threads that can execute are executing at the same time. In the process of creating this illusion, the scheduler needs to run Threads with a higher priority over lower priority Threads. However, Threads with a lower priority can't be starved of execution time. The scheduler also needs to minimize scheduling latencies as much as possible by making quick and smart decisions.
如果有正在执行的线程,OS调度程序负责确保内核不处于空闲状态。它还必须产生一种错觉,即所有可以执行的线程正在同时执行。在创建这种错觉的过程中,调度程序执行高优先级的线程,而不是低优先级的线程,但是,低优先级的线程也不至于饿死。调度程序还需要通过做出快速而明智的决策,来最大程度地减少调度延迟。
A lot goes into the algorithms to make this happen, but luckily there are decades of work and experience the industry is able to leverage. To understand all of this better, it's good to describe and define a few concepts that are important.
实现这一目标的算法很多,但是幸运的是,这个行业已经拥有数十年的工作和经验。为了更好地理解所有这些,我们需要描述和定义一些重要的概念。
Executing Instructions 执行指令
The program counter (PC), which is sometimes called the instruction pointer (IP), is what allows the Thread to keep track of the next instruction to execute. In most processors, the PC points to the next instruction and not the current instruction.
程序计数器(PC)有时也称为指令指针(IP),它使线程可以跟踪要执行的下一条指令。在大多数处理器中,PC指向下一条指令,而不是当前指令。
Figure 1 图1

https://www.slideshare.net/JohnCutajar/assembly-language-8086-intermediate
If you have ever seen a stack trace from a Go program, you might have noticed these small hexadecimal numbers at the end of each line. Look for +0x39 and +0x72 in Listing 1.
如果你看过Go程序的堆栈跟踪,你可能已经注意到每行末尾都有这些小的十六进制数字。在列表1中查找+0x39和+0x72。
Listing 1 列表1
goroutine 1 [running]:
main.example(0xc000042748, 0x2, 0x4, 0x106abae, 0x5, 0xa)
stack_trace/example1/example1.go:13 +0x39 <- LOOK HERE
main.main()
stack_trace/example1/example1.go:8 +0x72 <- LOOK HEREThose numbers represent the PC value offset from the top of the respective function. The +0x39 PC offset value represents the next instruction the Thread would have executed inside the example function if the program hadn't panicked. The +0x72 PC offset value is the next instruction inside the main function if control happened to go back to that function. More important, the instruction prior to that pointer tells you what instruction was executing.
这些数字代表PC值从相应函数的顶部偏移。PC偏移值+0x39表示如果程序未被终止,则线程将在example函数内执行的下一条指令。如果example函数返回,则PC偏移值+0x72代表主函数中的下一条指令。更重要的是,该指针之前的指令告诉你正在执行什么指令。
Look at the program below in Listing 2 which caused the stack trace from Listing 1.
参照下面列表2的代码,这些代码生成了列表1的堆栈跟踪。
Listing 2 列表2
https://github.com/ardanlabs/gotraining/blob/master/topics/go/profiling/stack_trace/example1/example1.go
07 func main() {
08 example(make([]string, 2, 4), "hello", 10)
09 }
12 func example(slice []string, str string, i int) {
13 panic("Want stack trace")
14 }The hex number +0x39 represents the PC offset for an instruction inside the example function which is 57 (base 10) bytes below the starting instruction for the function. In Listing 3 below, you can see an objdump of the example function from the binary. Find the 12th instruction, which is listed at the bottom. Notice the line of code above that instruction is the call to panic.
十六进制数字+0x39代表example函数内一条指令的PC偏移量,该偏移量比该函数的起始指令低57(0x39的十进制)字节。在下面的列表3中,你可以从二进制文件中看到example函数的objdump。 请注意最底部的第12条指令,该指令上方的代码行是对panic的调用。
Listing 3 列表3
$ go tool objdump -S -s "main.example" ./example1
TEXT main.example(SB) stack_trace/example1/example1.go
func example(slice []string, str string, i int) {
0x104dfa0 65488b0c2530000000 MOVQ GS:0x30, CX
0x104dfa9 483b6110 CMPQ 0x10(CX), SP
0x104dfad 762c JBE 0x104dfdb
0x104dfaf 4883ec18 SUBQ $0x18, SP
0x104dfb3 48896c2410 MOVQ BP, 0x10(SP)
0x104dfb8 488d6c2410 LEAQ 0x10(SP), BP
panic("Want stack trace")
0x104dfbd 488d059ca20000 LEAQ runtime.types+41504(SB), AX
0x104dfc4 48890424 MOVQ AX, 0(SP)
0x104dfc8 488d05a1870200 LEAQ main.statictmp_0(SB), AX
0x104dfcf 4889442408 MOVQ AX, 0x8(SP)
0x104dfd4 e8c735fdff CALL runtime.gopanic(SB)
0x104dfd9 0f0b UD2 <--- LOOK HERE PC(+0x39)Remember: the PC is the next instruction, not the current one. Listing 3 is a good example of the amd64 based instructions that the Thread for this Go program is in charge of executing sequentially.
请记住:PC是下一条指令,而不是当前的指令。列表3是基于amd64指令的一个很好的示例,该Go程序的线程负责按顺序执行。
Thread States 线程状态
Another important concept is Thread state, which dictates the role the scheduler takes with the Thread. A Thread can be in one of three states: Waiting, Runnable or Executing.
另一个重要的概念使线程状态,它规定了调度程序在线程中扮演的角色。线程可以处于以下三种状态之一:等待,可执行和执行中。
Waiting: This means the Thread is stopped and waiting for something in order to continue. This could be for reasons like, waiting for the hardware (disk, network), the operating system (system calls) or synchronization calls (atomic, mutexes). These types of latencies are a root cause for bad performance.
Waiting:意味着线程已停止并等待某些东西才能继续。这可能是由于诸如等待硬件(磁盘,网络),操作系统(系统调用)或同步调用(原子性,互斥性)之类的原因。这些类型的延迟是导致性能下降的根本原因。
Runnable: This means the Thread wants time on a core so it can execute its assigned machine instructions. If you have a lot of Threads that want time, then Threads have to wait longer to get time. Also, the individual amount of time any given Thread gets is shortened, as more Threads compete for time. This type of scheduling latency can also be a cause of bad performance.
Runnable:意味着线程需要获得内核上的时间,因此它可以执行其分配的机器指令。 如果你有很多需要时间的线程,则线程必须等待更长的时间才能获得时间。而且,随着更多线程争夺时间,任何给定线程获得的时间都将缩短。这种类型的调度等待时间,也会成为性能下降的原因。
Executing: This means the Thread has been placed on a core and is executing its machine instructions. The work related to the application is getting done. This is what everyone wants.
Executing:意味着线程已放置在内核上并正在执行其机器指令。与应用程序相关的工作已经完成。 这就是每个人都想要的。
Types Of Work 工作类型
There are two types of work a Thread can do. The first is called CPU-Bound and the second is called IO-Bound.
线程可以执行两种类型的工作。 第一个称为CPU-Bound,第二个称为IO-Bound。
CPU-Bound: This is work that never creates a situation where the Thread may be placed in Waiting states. This is work that is constantly making calculations. A Thread calculating Pi to the Nth digit would be CPU-Bound.
CPU-Bound:这种工作永远不会导致线程变为等待状态,这是不断进行计算的工作。例如,计算Pi到第N位的线程就是CPU绑定的。
IO-Bound: This is work that causes Threads to enter into Waiting states. This is work that consists in requesting access to a resource over the network or making system calls into the operating system. A Thread that needs to access a database would be IO-Bound. I would include synchronization events (mutexes, atomic), that cause the Thread to wait as part of this category.
IO-Bound:这种工作会使线程进入等待状态。这种工作包括请求网络资源,或对操作系统进行系统调用。访问数据库的线程也是IO-Bound。我还认为同步事件(互斥性,原子性)也属于这一范畴,因为这些事件会导致线程等待。
Context Switching 上下文切换
If you are running on Linux, Mac or Windows, you are running on an OS that has a preemptive scheduler. This means a few important things. First, it means the scheduler is unpredictable when it comes to what Threads will be chosen to run at any given time. Thread priorities together with events, (like receiving data on the network) make it impossible to determine what the scheduler will choose to do and when.
如果你在Linux,Mac或Windows上运行,则在具有抢占式调度程序的OS上运行。 这意味着一些重要的事情:首先,这意味着在任何给定时间选择要运行的线程时,调度程序都是不可预测的。线程优先级与事件(例如在网络上接收数据)一起作用,使我们无法确定,调度程序将执行什么,以及何时执行。
Second, it means you must never write code based on some perceived behavior that you have been lucky to experience but is not guaranteed to take place every time. It is easy to allow yourself to think, because I've seen this happen the same way 1000 times, this is guaranteed behavior. You must control the synchronization and orchestration of Threads if you need determinism in your application.
其次,这意味着你绝不能基于自己的过往经验来编写代码,这些经验可能只是幸运的经历,而无法确保每次都会发生。一个很容易发生的错误就是:我已经看到某种情况,以相同的方式发生了1000次,则简单认为这是有保证的行为。 如果需要在应用程序中具有确定性,则必须控制线程的同步和编排。
The physical act of swapping Threads on a core is called a context switch. A context switch happens when the scheduler pulls an Executing thread off a core and replaces it with a Runnable Thread. The Thread that was selected from the run queue moves into an Executing state. The Thread that was pulled can move back into a Runnable state (if it still has the ability to run), or into a Waiting state (if was replaced because of an IO-Bound type of request).
在内核上交换线程的物理行为称为上下文切换。当调度程序从内核中取出一个Executing线程,并将其替换为Runnable线程时,就会发生上下文切换。 从运行队列中选择的线程将进入Executing状态。 被取出的线程可以移回Runnable状态(如果它仍具有执行的能力)或Waiting状态(如果由于IO-Bound类型的请求而被替换)。
Context switches are considered to be expensive because it takes times to swap Threads on and off a core. The amount of latency incurrent during a context switch depends on different factors but it's not unreasonable for it to take between ~1000 and ~1500 nanoseconds. Considering the hardware should be able to reasonably execute (on average) 12 instructions per nanosecond per core, a context switch can cost you ~12k to ~18k instructions of latency. In essence, your program is losing the ability to execute a large number of instructions during a context switch.
上下文切换是昂贵的,因为在核心上和在核心外交换线程都需要时间。上下文切换期间的延迟取决于不同的因素,但花费约1000到1500纳秒,并非空穴来风。考虑到硬件应该能够合理地(平均)每核每纳秒执行12条指令,上下文切换可能会花费大约12k至18k的延迟指令。本质上,你的程序在上下文切换期间,将失去执行大量指令的能力。
If you have a program that is focused on IO-Bound work, then context switches are going to be an advantage. Once a Thread moves into a Waiting state, another Thread in a Runnable state is there to take its place. This allows the core to always be doing work. This is one of the most important aspects of scheduling. Don't allow a core to go idle if there is work (Threads in a Runnable state) to be done.
如果你有一个专注于IO-Bound工作的程序,那么上下文切换将是一个优势。一旦一个线程进入等待状态,另一个处于Runnable状态的线程就会代替它。这使核心始终可以工作。这是调度的最重要方面之一:如果有工作(线程处于Runnable状态)要完成,则不要让内核闲置。
If your program is focused on CPU-Bound work, then context switches are going to be a performance nightmare. Since the Thead always has work to do, the context switch is stopping that work from progressing. This situation is in stark contrast with what happens with an IO-Bound workload.
如果你的程序专注于CPU-Bound的工作,那么上下文切换将成为性能的噩梦。由于线程总是有工作要做,因此上下文切换将阻止该工作的进行。这种情况与IO-Bound工作负载形成鲜明对比。
Less Is More 少即是多
In the early days when processors had only one core, scheduling wasn't overly complicated. Because you had a single processor with a single core, only one Thread could execute at any given time. The idea was to define a scheduler period and attempt to execute all the Runnable Threads within that period of time. No problem: take the scheduling period and divide it by the number of Threads that need to execute.
在处理器只有一个内核的早期,调度并不过于复杂。因为你只有一个具有单个内核的处理器,所以在任何给定时间只能执行一个线程。定义一个调度程序周期,并尝试在该时间周期内执行所有Runnable线程。没问题:占用调度时间,然后将其除以需要执行的线程数。
As an example, if you define your scheduler period to be 1000ms (1 second) and you have 10 Threads, then each thread gets 100ms each. If you have 100 Threads, each Thread gets 10ms each. However, what happens when you have 1000 Threads? Giving each Thread a time slice of 1ms doesn't work because the percentage of time you're spending in context switches will be significant related to the amount of time you're spending on application work.
例如,如果你将调度程序周期定义为1000ms(1秒),并且你有10个线程,那么每个线程将获得100ms。如果你有100个线程,则每个线程将获得10ms。但是,当你有1000个线程时会发生什么? 为每个线程分配1ms的时间片是行不通的,因为你在上下文切换中花费的时间的比例,将与你在应用程序工作上花费的时间密切相关。
What you need is to set a limit on how small a given time slice can be. In the last scenario, if the minimum time slice was 10ms and you have 1000 Threads, the scheduler period needs to increase to 10000ms (10 seconds). What if there were 10,000 Threads, now you are looking at a scheduler period of 100000ms (100 seconds). At 10,000 threads, with a minimal time slice of 10ms, it takes 100 seconds for all the Threads to run once in this simple example if each Thread uses its full time slice.
你需要做的,就是为时间片设置一个限制。在上述最后一种情况下,如果最小时间片为10ms,并且你有1000个线程,则调度周期需要增加到10000ms(10秒)。 如果有10,000个线程怎么办,现在你需要100000ms(100秒)的调度周期。在这个简单的示例中,如果每个线程使用其完整的时间片,则在10,000个线程上,最少的时间片为10毫秒,所有线程运行一次将花费100秒。
Be aware this is a very simple view of the world. There are more things that need to be considered and handled by the scheduler when making scheduling decisions. You control the number of Threads you use in your application. When there are more Threads to consider, and IO-Bound work happening, there is more chaos and nondeterministic behavior. Things take longer to schedule and execute.
要知道,这不过是一个非常简单的例子。制定调度决策时,调度程序还需要考虑和处理更多的事情。你可以控制在应用程序中使用的线程数。当要考虑的线程更多,并且发生IO-Bound工作时,就会出现更多的混乱和不确定性行为。事情需要更长的时间来调度和执行。
This is why the rule of the game is “Less is More”. Less Threads in a Runnable state means less scheduling overhead and more time each Thread gets over time. More Threads in a Runnable state mean less time each Thread gets over time. That means less of your work is getting done over time as well.
这就是为什么游戏规则是“少即是多”的原因。处于Runnable状态的线程越少,意味着调度时间越少,并且每个线程可以拥有更多的时间。 更多线程处于Runnable状态意味着每个线程拥有的时间更少。 这意味着在时间流中,你完成的工作也更少了。
Find The Balance 找到平衡
There is a balance you need to find between the number of cores you have and the number of Threads you need to get the best throughput for your application. When it comes to managing this balance, Thread pools were a great answer. I will show you in part II that this is no longer necessary with Go. I think this is one of the nice things Go did to make multithreaded application development easier.
你需要在 拥有的内核数量 与 为应用程序获得最佳吞吐量所需的线程数量 之间找到平衡。在管理这种平衡时,线程池是一个很好的答案。我将在第二部分中向你展示,Go不再需要这么做。我认为这是Go简化多线程应用程序开发的一件好事。
Prior to coding in Go, I wrote code in C++ and C# on NT. On that operating system, the use of IOCP (IO Completion Ports) thread pools were critical to writing multithreaded software. As an engineer, you needed to figure out how many Thread pools you needed and the max number of Threads for any given pool to maximize throughput for the number of cores that you were given.
在使用Go编码之前,我在NT上用C++和C#编写代码。在该操作系统上,使用IOCP(IO完成端口)线程池对于编写多线程软件至关重要。作为工程师,你需要确定所需的线程池数以及任何给定池的最大线程数,以最大程度地提高所给定内核数的吞吐量。
When writing web services that talked to a database, the magic number of 3 Threads per core seemed to always give the best throughput on NT. In other words, 3 Threads per core minimized the latency costs of context switching while maximizing execution time on the cores. When creating an IOCP Thread pool, I knew to start with a minimum of 1 Thread and a maximum of 3 Threads for every core I identified on the host machine.
当编写与数据库通信的Web服务时,每个内核3线程的神奇数目似乎总是在NT上提供最佳吞吐量。换句话说,每个内核3个线程可以最大程度地减少上下文切换的延迟消耗,同时可以最大程度地延长内核的执行时间。创建IOCP线程池时,我知道对于主机上标识的每个内核,最少要有1个线程,最多要有3个线程。
If I used 2 Threads per core, it took longer to get all the work done, because I had idle time when I could have been getting work done. If I used 4 Threads per core, it also took longer, because I had more latency in context switches. The balance of 3 Threads per core, for whatever reason, always seemed to be the magic number on NT.
如果我每个内核使用2个线程,那么完成所有工作的时间会更长,因为我本来可以完成工作的时间很空闲。如果我每个内核使用4个线程,则还需要花费更长的时间,因为我在上下文切换中有更多的延迟。无论出于何种原因,每个内核3个线程的平衡似乎始终是NT上的神奇数字。
What if your service is doing a lot of different types of work? That could create different and inconsistent latencies. Maybe it also creates a lot of different system-level events that need to be handled. It might not be possible to find a magic number that works all the time for all the different work loads. When it comes to using Thread pools to tune the performance of a service, it can get very complicated to find the right consistent configuration.
如果你的服务正在执行许多不同类型的工作该怎么办? 这可能会产生不同且不一致的延迟。也许它还会创建许多需要处理的不同的系统级事件。不可能找到一个在所有不同工作负荷下始终有效的神奇数字。当涉及到使用线程池来调整服务的性能时,找到正确一致的配置会变得非常复杂。
Cache Lines 缓存块
Accessing data from main memory has such a high latency cost (~100 to ~300 clock cycles) that processors and cores have local caches to keep data close to the hardware threads that need it. Accessing data from caches have a much lower cost (~3 to ~40 clock cycles) depending on the cache being accessed. Today, one aspect of performance is about how efficiently you can get data into the processor to reduce these data-access latencies. Writing multithreaded applications that mutate state need to consider the mechanics of the caching system.
访问主内存中的数据,会有很高的延迟(约100至300个时钟周期),因此处理器和内核具有本地缓存,以使数据被保存在需要它的硬件线程附近。从缓存访问数据的成本要低得多(约3至40个时钟周期),具体取决于要访问的缓存。今天,性能的一个方面是关于:如何有效地将数据输入处理器,以减少这些数据访问延迟。编写改变状态的多线程应用程序,需要考虑缓存系统的机制。
Figure 2 图2

Data is exchanged between the processor and main memory using cache lines. A cache line is a 64-byte chunk of memory that is exchanged between main memory and the caching system. Each core is given its own copy of any cache line it needs, which means the hardware uses value semantics. This is why mutations to memory in multithreaded applications can create performance nightmares.
数据在处理器和主内存之间交换时,使用缓存块。缓存块是在主内存和缓存系统之间交换的64字节内存块。每个内核都会获得所需的任何缓存块的副本,这意味着硬件使用值语义。 这就是为什么多线程应用程序中的内存突变,会造成性能噩梦的原因。
When multiple Threads running in parallel are accessing the same data value or even data values near one another, they will be accessing data on the same cache line. Any Thread running on any core will get its own copy of that same cache line.
当多个并行运行的线程正在访问同一数据值,或彼此接近的数据值时,它们将在同一缓存块上访问数据。在任何内核上运行的任何线程都将获得该同一缓存块的副本。
Figure 3 图3
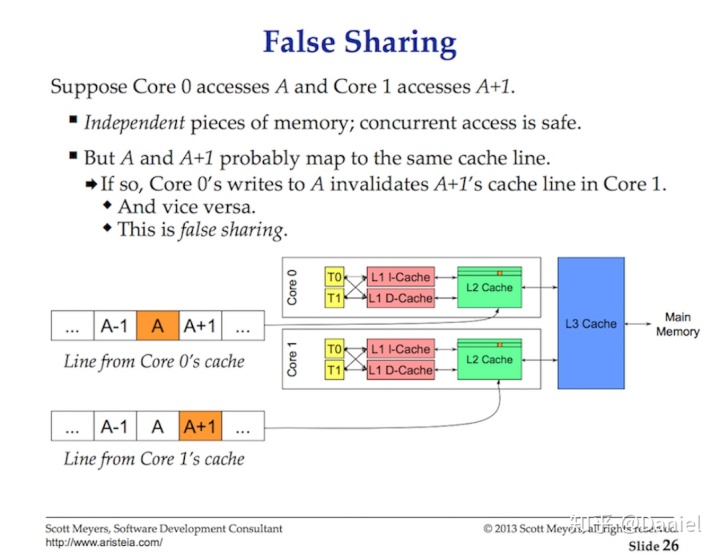
If one Thread on a given core makes a change to its copy of the cache line, then through the magic of hardware, all other copies of the same cache line have to be marked dirty. When a Thread attempts read or write access to a dirty cache line, main memory access (~100 to ~300 clock cycles) is required to get a new copy of the cache line.
如果给定核心上的一个线程更改了其缓存行的副本,则必须借助硬件,将同一缓存块的所有其他副本标记为脏缓存。当线程尝试对脏缓存行进行读写访问时,需要访问主内存(约100至300个时钟周期)才能获取缓存块的新副本。
Maybe on a 2-core processor this isn't a big deal, but what about a 32-core processor running 32 threads in parallel all accessing and mutating data on the same cache line? What about a system with two physical processors with 16 cores each? This is going to be worse because of the added latency for processor-to-processor communication. The application is going to be thrashing through memory and the performance is going to be horrible and, most likely, you will have no understanding why.
也许在2核处理器上这没什么大不了的,但是如果32核处理器并行运行32个线程,所有访问和变异数据都在同一缓存块上呢? 如果两处理器16核的系统呢? 由于增加了处理器间通信的延迟,因此情况将变得更糟。应用程序将被驱赶着访问内存,性能会非常糟糕,而此时的你,却依然不明白为什么。
This is called the cache-coherency problem and also introduces problems like false sharing. When writing multithreaded applications that will be mutating shared state, the caching systems have to be taken into account.
这称为缓存一致性问题,而且还引出了错误共享之类的问题。在编写多线程应用程序时,如果改变共享状态,则必须考虑缓存系统。
Scheduling Decision Scenario 调度决策方案
Imagine I've asked you to write the OS scheduler based on the high-level information I've given you. Think about this one scenario that you have to consider. Remember, this is one of many interesting things the scheduler has to consider when making a scheduling decision.
想象一下,我要求你编写一个基于高级信息的OS调度程序,思考一下你必须考虑的情况。 请记住,这是调度程序在做出调度决策时必须考虑的许多有趣的事情之一。
You start your application and the main Thread is created and is executing on core 1. As the Thread starts executing its instructions, cache lines are being retrieved because data is required. The Thread now decides to create a new Thread for some concurrent processing. Here is the question.
你启动你的应用程序,并在核心1上创建并执行主线程。随着线程开始执行其指令,由于需要数据,因此缓存块被检索。线程现在决定为某个并发处理创建一个新线程,但是问题来了。
Once the Thread is created and ready to go, should the scheduler:
- Context-switch the main Thread off of core 1? Doing this could help performance, as the chances that this new Thread needs the same data that is already cached is pretty good. But the main Thread does not get its full time slice.
- Have the Thread wait for core 1 to become available pending the completion of the main Thread's time slice? The Thread is not running but latency on fetching data will be eliminated once it starts.
- Have the Thread wait for the next available core? This would mean cache lines for the selected core would be flushed, retrieved, and duplicated, causing latency. However, the Thread would start more quickly and the main Thread could finish its time slice.
当线程被创建并准备就绪后,调度程序应该:
- 在核心1中对主线程进行上下文切换? 这样做可以提高性能,因为可以利用一个好机会:已经缓存的数据恰好时这个新线程需要的。但是主线程却无法获得其全部时间片。
- 新线程等待 核心1完成主线程的时间片之后 变得可用? 这个线程未运行,但一旦启动,将在等待获取数据的时候被消除。
- 新线程等待下一个可用内核? 这意味着将清除,检索和复制所选核心的缓存行,从而导致延迟。但是,线程将启动得更快,并且主线程可以完成其时间片。
Having fun yet? These are interesting questions that the OS scheduler needs to take into account when making scheduling decisions. Luckily for everyone, I'm not the one making them. All I can tell you is that, if there is an idle core, it's going to be used. You want Threads running when they can be running.
很有趣吧? 这些有趣的问题,是OS调度程序在制定计划决策时,需要考虑的问题。幸运的是,对于每个人来说,并不需要处理。我所能告诉你的就是,如果有一个空闲的内核,它将被使用。线程能被执行的时候,就会被执行。
Conclusion 结论
This first part of the post provides insights into what you have to consider regarding Threads and the OS scheduler when writing multithreaded applications. These are the things the Go scheduler takes into consideration as well. In the next post, I will described the semantics of the Go scheduler and how they related back to this information. Then finally, you will see all of this in action by running a couple programs.
此系列的第一部分,提供了有关线程和OS调度程序的见解,在编写多线程应用程序时,它们必须被考虑。 这些也是Go调度程序要考虑的事项。 在下一篇文章中,我将描述Go调度程序的原理以及它们如何与该信息相关。最后,通过运行几个程序,你将看到所有这些操作。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









