







随机森林简介
随机森林是一种通用的机器学习方法,能够处理回归和分类问题。它还负责数据降维、缺失值处理、离群值处理以及数据分析的其他步骤。它是一种集成学习方法,将一组一般的模型组合成一个强大的模型
工作原理
我们通过适用随机的方式从数据中抽取样本和特征值,训练多个不同的决策树,形成森林。为了根据属性对新对象进行分类,每个数都给出自己的分类意见,称为“投票”。在分类问题下,森林选择票数最多的分类;在回归问题下则适用平均值的方法。
随机森林是基于Bagging方法的集成模型,Bagging的示例如下:
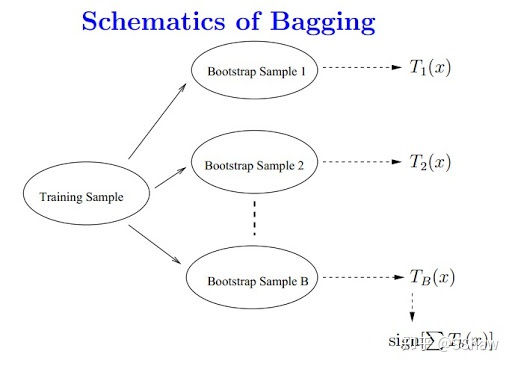
若每个分类模型都是决策树,那就构成了随机森林。Bagging方法通过抽样的方式获得多份不同的训练样本,在不同的训练杨版本上训练决策树,从而降低了决策树之间的相关性。同时还通过特征的随机选取,特征阈值的随机选取两种方式产生随机性,进一步降低决策树之间的相关性。
随机森林优缺点
优点:
- 能够处理更高维度的大数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7975
7975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









