





经常看博客的同志知道,博客园每个栏目下面有200页,多了的数据他就不显示了,最多显示4000篇博客如何尽可能多的得到博客数据,是这篇文章研究的一点点核心内容,能√get到多少就看你的了~
单纯的从每个栏目去爬取是不显示的,转换一下思路,看到搜索页面,有时间~,有时间!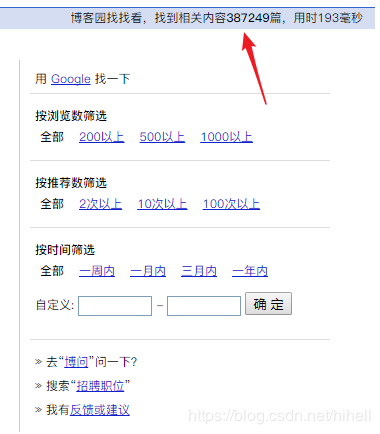
注意看URL链接
https://zzk.cnblogs.com/s/blogpost?Keywords=python&datetimerange=Customer&from=2019-01-01&to=2019-01-01
这个链接得到之后,其实用一个比较简单的思路就可以获取到所有python相关的文章了,迭代时间。
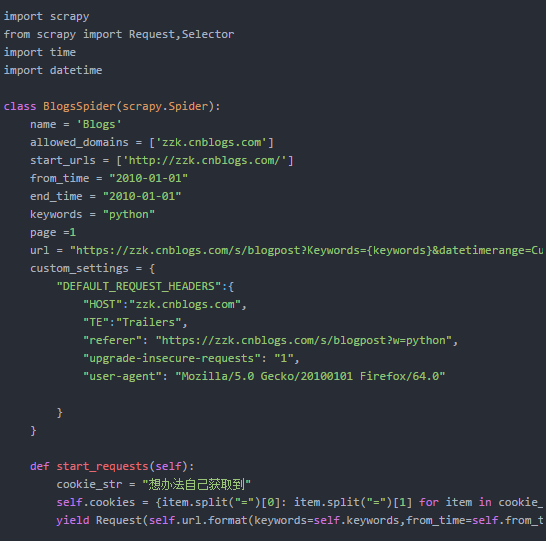
下面编写核心代码,比较重要的几个点,我单独提炼出来。页面搜索的时候因为加了验证,所以你必须要获取到你本地的cookie,这个你很容易得到
字典生成器的语法是时候去复习一下了
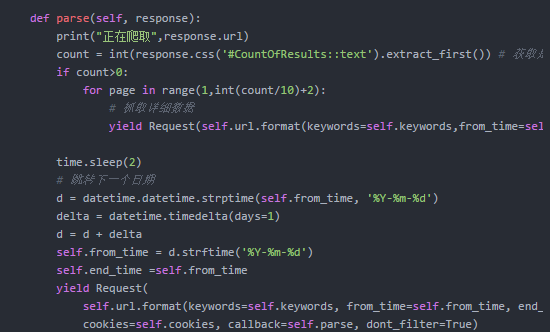
页面爬取完毕之后,需要进行解析,获取翻页页码,同时将时间+1天,下面的代码重点看时间叠加部分的操作。
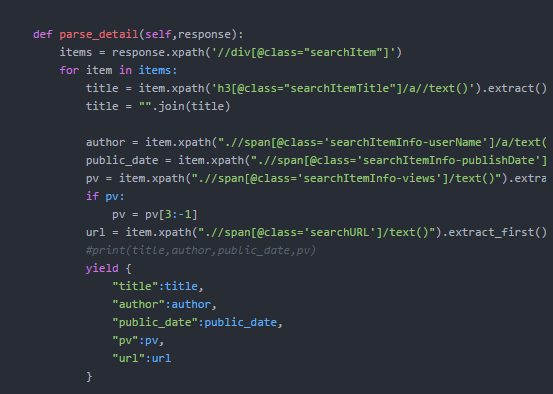
页面解析入库
本部分操作逻辑没有复杂点,只需要按照流程编写即可,运行代码,跑起来,在mongodb等待一些时间
db.getCollection('dict').count({})
返回
数据入库
一顿操作猛如虎,数据就到手了~后面可以做一些简单的数据分析,那篇博客再见啦@















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









