





一. csv/json/pickle基本概念
csv:CSV(Comma Separated Values)格式是电子表格和数据库最常见的导入和导出格式。用文本文件形式储存的表格数据,可以使用excel打开,易于阅读,
json:数据交换格式。用于提升网络传输效率,可以字符串和python之间的转换,可用于网页上这种数据传输,支持跨语言
pickle:pickle模块实现了用于对Python对象结构进行序列化和反序列化的二进制协议,人类无法识别
在pickle协议和JSON(JavaScript对象表示法)之间存在根本区别:
- JSON是一种文本序列化格式(它输出unicode文本,虽然大多数时候它被编码为utf-8),而pickle是一个二进制序列化格式;
- JSON是人类可读的,而pickle不是;
- JSON是可互操作的,并且在Python生态系统之外广泛使用,而pickle是特定于Python的;
默认情况下,JSON只能表示Python内建类型的一个子集,并且没有自定义类; pickle可以代表极大数量的Python类型
其中许多是通过巧妙地使用Python内省功能自动实现的;复杂的情况可以通过实现specific object APIs来解决。
二 csv/json/pickle基本使用方法
1. csv
(1. csv模块API说明
csv模块的reader和writer对象读取和写入序列。程序员还可以使用DictReader和DictWriter类以字典形式读取和写入数据。
csv模块定义以下函数:1.csv.reader(csvfile, dialect='excel', * * fmtparams)
- 返回一个读取器对象,它将在给定的csvfile中迭代。csvfile可以是任何支持iterator协议的对象,并且每次调用 __ next __ ()方法时返回一个字符串 - file objects和列表对象都是合适的。
- 如果csvfile是文件对象,则应使用newline=''打开它。如果没有使用newline="",写到文件中会在每行结束加个t换行符2.csv.writer(csvfile, dialect='excel', * * fmtparams)
返回一个writer对象,可以使用writerow(data),writerows(datas)
csv模块定义以下类:
(1.class csv.DictReader(csvfile, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, * *kwds)
创建一个对象,其操作类似于普通读取器,但将读取的信息映射到一个dict中,其中的键由可选的fieldnames参数给出。
fieldnames参数是一个sequence,其元素按顺序与输入数据的字段相关联。这些元素成为结果字典的键。
(2.class csv.DictWriter(csvfile, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, * *kwds)
创建一个操作类似于常规writer的对象,但将字典映射到输出行。
fieldnames参数是一个sequence,用于标识传递给writerow()方法的字典中的值被写入csvfile。
如果传递给writerow()方法的字典包含fieldnames中未找到的键,则可选的extrasaction参数指示要执行的操作。
(2.csv具体代码示例
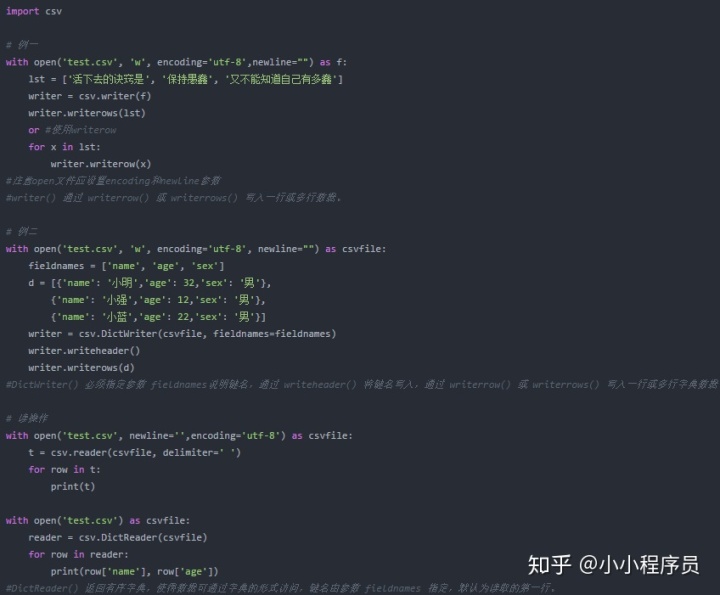
2. json简单使用介绍
(1. json模块API说明
python转换json

1.将obj序列化为fp,json模块总是产生str对象,而不是bytes对象。因此,fp.write()必须支持str输入。
2.如果 skipkeys 的值为 true (默认为: False), 那么不是基本类型 (str, int, float, bool, None)的字典键将会被跳过, 而不是引发一个 TypeError 异常.
3.如果indent是非负整数或字符串,缩进
4.separator = (item_separator, key_separator),默认(',',':')
5.sort_keys为真(默认值:False),则字典的输出将按键排序。
6.遇见复杂的python无法转换时使用default参数,覆盖default()方法以序列化其他类型

同上用法
json转换python

1.object_hook是一个可选的函数,它将被任何对象字面值解码(dict)的结果调用。
2.parse_float(如果指定)将使用要解码的每个JSON浮点的字符串进行调用。

同上用法
对于复杂的结构我们可以自定义解码和编码

(2. json具体使用示例
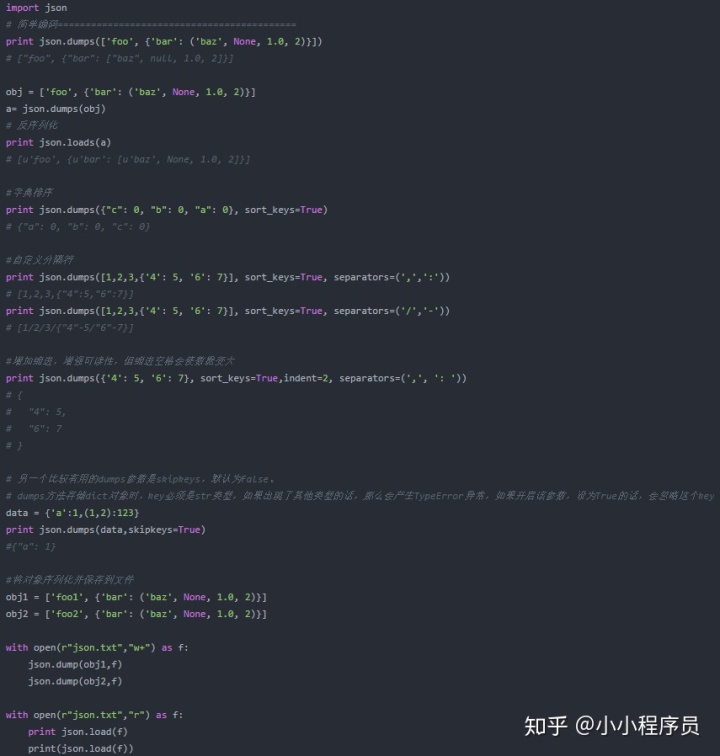
3.pickle使用
(1.pickle模块API说明
pickle模块实现了用于对Python对象结构进行序列化和反序列化的二进制协议
1.pickle.dump(obj, file, protocol=None, *, fix_imports=True)
将obj的腌制表示写入打开的file object 文件。这相当于Pickler(文件, 协议).dump(obj)。
2.pickle.dumps(obj, protocol=None, *, fix_imports=True)
将对象的腌制表示作为bytes对象返回,而不是将其写入文件。
3.pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict")
从打开的文件对象file读取pickled对象表示形式,并返回其中重新构建的对象层次结构。它等同于Unpickler(file).load()。
4.pickle.loads(bytes_object, *, fix_imports=True, encoding="ASCII", errors="strict")
从bytes对象读取腌制对象层次结构,并返回其中指定的重构对象层次结构。
(2.pickle具体示例
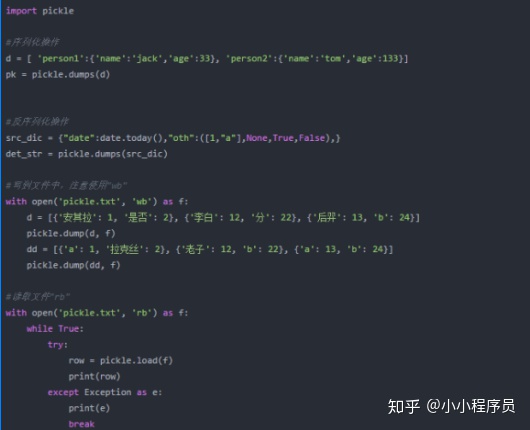
三.使用场景
1.pickle主要用于存储计算过数据,保存下来下次使用直接获取,特点是他的读写效率高于一般文件,存储大小也更小
2.json主要用于网络直接传递数据,存储一些结构化数据
3.CSV 通常用于在电子表格软件和纯文本之间交互数据。实际上,CSV 都不算是一个真正的结构化数据,CSV 文件内容仅仅是一些用逗号分隔的原始字符串值。














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









