





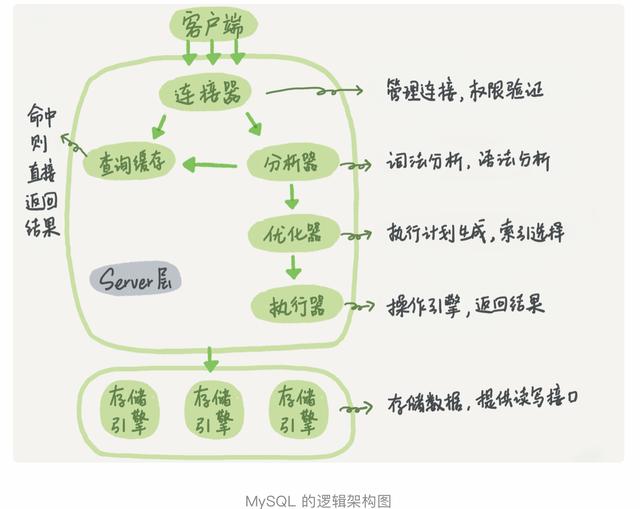
说的sql的锁,很多人都会想到乐观锁和悲观锁。其实这些是我们在使用过程中明确用到的锁,但是,一条简单的sql语句,你了解其中的数据库加锁过程吗?首先,先了解下sql语句的执行过程吧,具体如下图:
了解了MySQL执行逻辑后,学习锁之前,我们需要先了解下MySQL的事务隔离级别:
MySQL的隔离级别
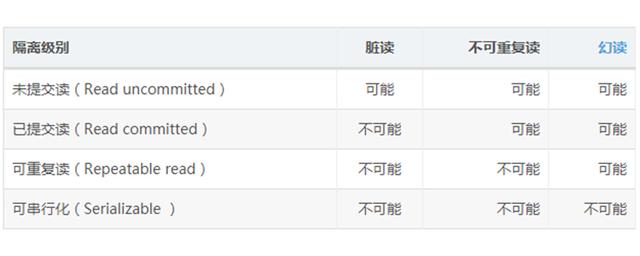
1、Read Uncommitted(读取未提交内容):脏读,所有事务可以看到其他未提交事务的执行结果
2、Read Committed(读取提交内容):不可重复读,大多数系统的默认隔离级别(但不是MySQL的)。所有事务只能看到已提交事务的执行结果(若B事务在A事务执行期间提交事务,对于A来说可见,那么A前后读取的数据可能是不一致;若B未提交事务,则对于A而言不可见)幻读
3、Repeatable Read(可重读):MySQL的默认隔离级别。确保同一事务的多个实例在并发读取数据时,会看到同样的数据行(若有B事务在A事务执行期间操作了数据并提交事务,对于A事务来说未可知,直至A事务提交后,再次读取才能看到B事务的提交)读事务禁止写事务,写事务禁止任何其它事务
* 幻读:幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。MVCC解决幻读(GAP锁)。
4、Serializable(可串行化):最高的隔离级别,强制事务排序,在每个读的数据行上加共享锁,事务只能一个接一个执行,不能并发执行
5、不可重复读发生在update、delete操作中,幻读发生在insert操作中。
离开事务隔离级别谈sql加锁过程是空谈,在上述事务隔离级别前提下,我们通过分析一个简单的sql语句来了解加锁过程吧。
加锁过程分析
* SQL1:select * from t1 where id = 10;
* SQL2:delete from t1 where id = 10;
1、首先需明确前提条件,才能分析加锁情况。(where条件是否为主键?唯一索引?非唯一索引?非索引?数据库隔离级别是什么?执行计划?)
2、分析:(RC、RR隔离级别下)
2.1、SQL1在RC和RR隔离级别下,均不加锁,属于快照读
- delete分析:
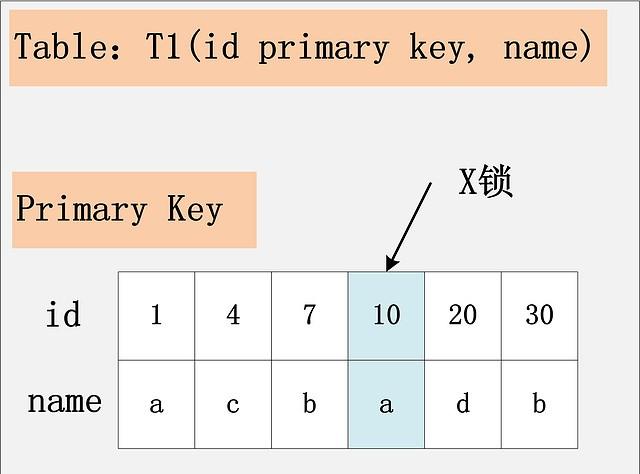
2.2、id主键+RC:id是主键时,此SQL只需要在id=10这条记录上加X锁即可。
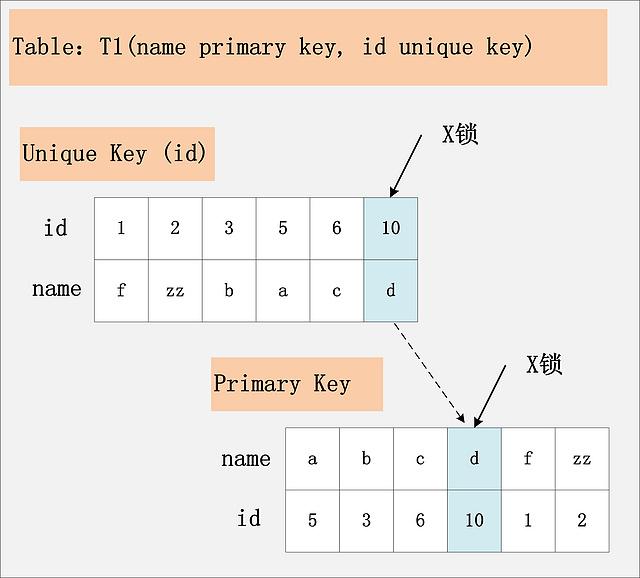
2.3、id唯一索引+RC:SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name='d',id=10]的记录。
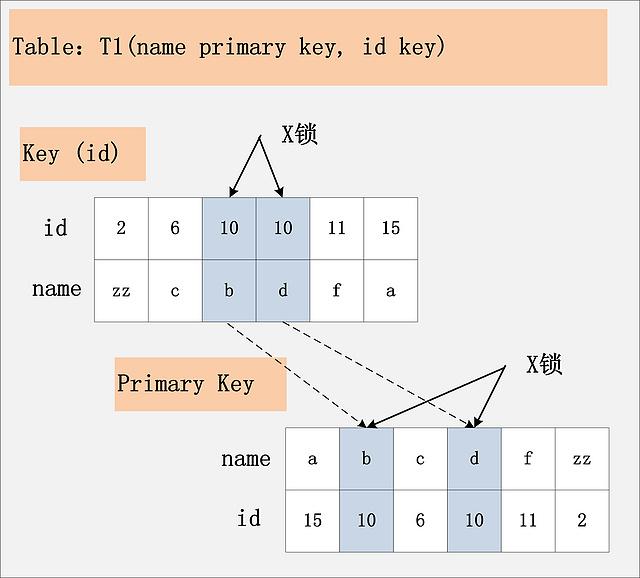
2.4、id非唯一索引+RC:若id列非唯一索引,对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
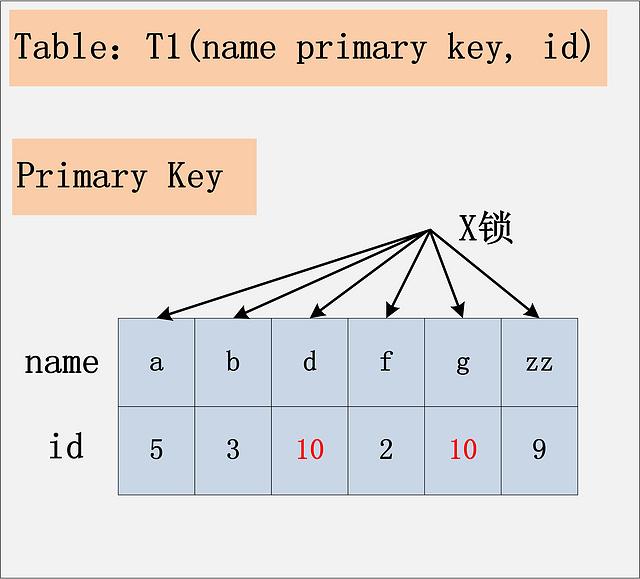
2.5、id非索引+RC:若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
2.6、id主键+RR:只需要在id=10这条记录上加X锁即可。
2.7、id唯一索引+RR:SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name='d',id=10]的记录。
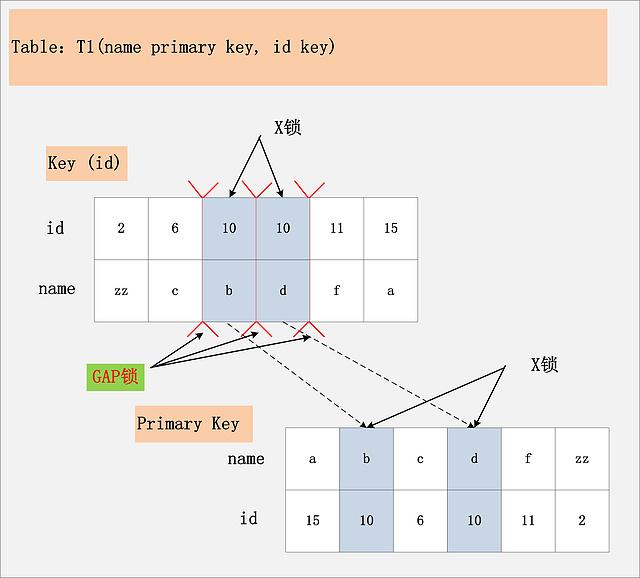
2.8、id非唯一索引+RR:首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
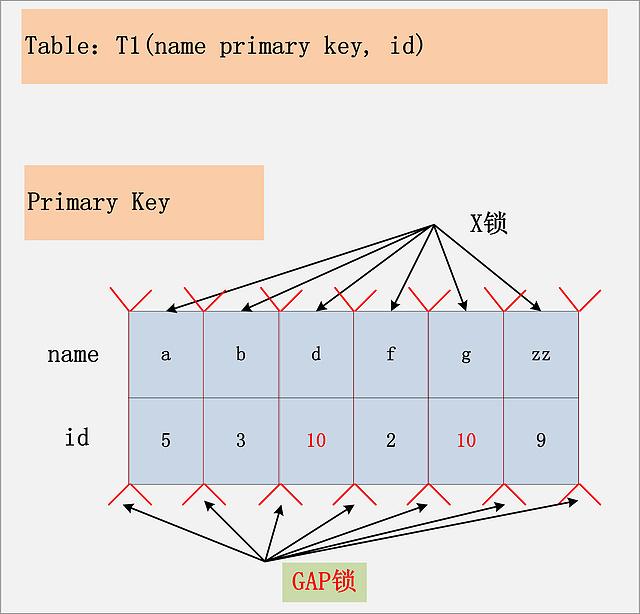
2.9、id非索引+RR:在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。当然,也可以通过触发semi-consistent read,来缓解加锁开销与并发影响,但是semi-consistent read本身也会带来其他问题,不建议使用。
2.10、Serializable:select加读锁,delete与RR隔离级别一致。
总结:
在我们工作中,尽管是一个简单的delete语句,也是多重场景下,加锁过程是不同的,那么我们经常会遇到死锁,其实并不是因为锁的多少,而是session的先后顺序要一直,避免两个线程相互等待资源,造成死锁。另外,在分析锁的过程时要结合隔离级别谈,有了以上这些知识,加上适当的经验,即可全面掌握MySQL的加锁规则的。















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









