







近年来,随着在数百万个网页上训练的大型transformer-based语言模型的兴起,人们对开放式语言生成的兴趣越来越浓厚。
条件开放式语言生成的成果令人印象深刻,除了改进的transformer架构和大量的无监督训练数据,好的解码方法也起到了重要的作用。
这篇博客文章简要概述了不同的解码策略,更重要的是展示了如何轻松使用流行的transformer 库实现它们!
原文如下:
自回归语言生成基于一个假设,即一个单词序列的概率分布可以分解为条件下一个单词分布的乘积:
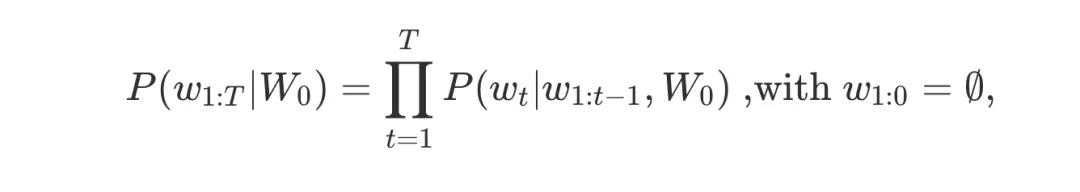
W0W0 是初始上下文字序列。单词序列的长度TT通常是即时确定的,并且与时间步长t=T对应,EOS令牌是根据P(wt∣w1:t−1,W0)生成的。
在PyTorch和Tensorflow >= 2.0中,GPT2、XLNet、OpenAi-GPT、CTRL、TransfoXL、XLM、Bart、T5都可以使用自回归语言生成!
我们将介绍目前最著名的解码方法,主要有贪心搜索(greedy search)、集束搜索(beam search)、Top-K采样和Top-p采样。
快速安装transformers 并加载模型。我们将在Tensorflow 2.1中使用GPT2进行演示,但是PyTorch的API是1对1的。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
importtensorflow astf
fromtransformers importTFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model=TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
Greedy Search(贪心搜索)
贪心搜索只是在每个timestep t中选择概率最高的单词作为下一个单词: wt = argmaxwP(w∣w1:t-1)。下面的示意图展示了贪心搜索:
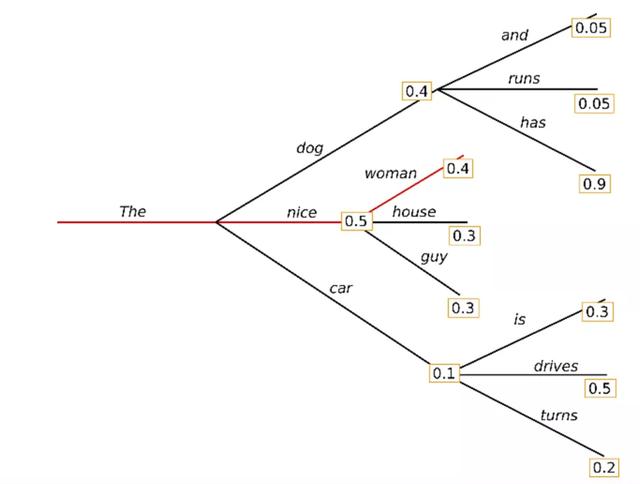
算法从单词“the”开始,选择概率最高的下一个单词“nice”,以此类推,最终生成的单词序列是“the”、“nice”、“woman”,总体概率为0.5×0.4=0.2
接下来,我们将在上下文中使用GPT2生成单词序列(“I”、“enjoy”、“walking”、“with”、“my”、“cute”、“dog”)。来看看贪心搜索是如何在transformers中使用的:
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf') # generate text until the output length (which includes the context length) reaches 50greedy_output = model.generate(input_ids, max_length=50) print("Output:" + 100 * '-')print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll
我们使用GPT2生成了第一个简短文本。根据上下文生成的单词是合理的,但是模型很快就会开始重复!一般来说,这是语言生成中一个非常普遍的问题,在贪心和波束搜索中似乎更是如此。
贪心搜索的主要缺点是,它错过了隐藏在低概率单词后面的高概率单词。
如上图所示:单词“has”的条件概率高达0.9,隐藏在单词“dog”后面,而“dog”的条件概率仅次于“dog”,因此贪婪搜索会漏掉单词序列“The”、“dog”、“has”。
还好,我们有了集束搜索(beam search)来缓解这个问题!
beam search(集束搜索)
集束搜索通过在每个time step保留最可能的num_beams ,并最终选择总体概率最高的假设,从而降低了丢失隐藏的高概率单词序列的风险。
让我们用num_beams = 2进行说明:
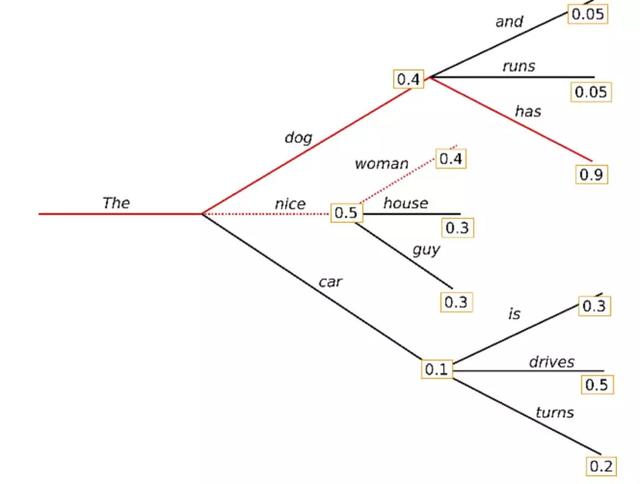
在time step 11,除了最可能的假设“ The”,“ woman”之外,集束搜索还跟踪第二个最可能的假设“ The”、“ dog”。在time step 22,集束搜索发现单词序列"The", "dog", "has"的概率比“ The”,“ nice”,“ woman”(0.2)高0.36。很好,它发现了示例中最可能的单词序列!
集束搜索将始终找到比贪心搜索具有更高概率的输出序列,但不能保证找到最有可能的输出。
让我们看看如何在transformers中使用集束搜索。我们设置num_beam > 1和early_stop =True,这样当所有集束假设到达EOS令牌时,生成就完成了。
# activate beam search and early_stoppingbeam_output = model.generate( input_ids, max_length=50, num_beams= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









