






 RK3399六核人工智能主板集成了高性能Cortex-A72架构处理器和NPU,提供5.6 Tops的峰值算力,支持PyTorch和Caffe框架。独特的APiM架构提升了运算速度和能效。配备模型训练工具PLAI,简化了AI模型开发,并提供多种网络训练模型,适用于边缘计算和多种AI应用场景。
RK3399六核人工智能主板集成了高性能Cortex-A72架构处理器和NPU,提供5.6 Tops的峰值算力,支持PyTorch和Caffe框架。独特的APiM架构提升了运算速度和能效。配备模型训练工具PLAI,简化了AI模型开发,并提供多种网络训练模型,适用于边缘计算和多种AI应用场景。
RK3399(AI)六核人工智能开源主板,采用Rockchip六核高性能处理器,板载模块化深度神经网络学习加速器NPU,无需外部缓存,拥有强劲算力与超高效能,支持 PyTorch , Caffe 深度学习框架,提供完整易用的模型训练工具、网络训练模型实例,可快速应用在移动边缘计算、智能家居、人脸检测识别、人工智能服务器等领域。

64位高性能核心
搭载ARM全新Cortex-A72架构、六核64位高性能处理器,主频高达1.8GHz,集成四核Mali-T860 GPU,支持H.265 HEVC和VP9、H.264编码、4K HDR,拥有强大的硬解码能力,最大可支持4K硬解。

人工智能处理器NPU
板载AI嵌入式神经网络处理器NPU,峰值算力高达5.6 Tops,典型算力2.8 Tops,效率能耗比高达9.3 Tops/W,在拥有超强的算力同时保持了极低的能耗,让其应用在终端设备的边缘计算领域中极具优势。
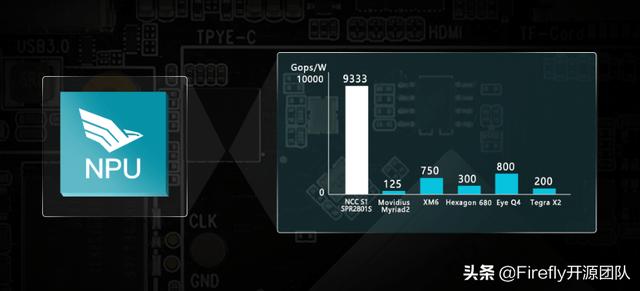
独特AI架构APiM
采用AI专用的MPE矩阵引擎和APiM(AI processing in Memory,存储中的AI处理)架构,存储计算融合一体的本地并行AI运算,一次升级网络预加载,无需指令、总线,无需外部DDR缓存,处理速度远远超过了其他传统架构的处理器,同时也大大降低了处理能耗。

配套模型训练工具
提供基于PyTorch完整易用的模型训练工具PLAI(People Learn AI), 可在Windows 10与Ubuntu 16.04系统上开发,更简单快捷地添加自定义网络模型,大大降低了使用AI的技术门槛,让更多人能更容易打开AI的大门。

提供网络训练模型
支持基于 VGG的GNet1,GNet18和GNetfc三种网络训练模型实例,后续会持续增加网络实例,轻松在设备上测试大量深度学习应用。

工业级应用性能
主板配置工业级金属外壳,外型小巧,无风扇高效散热设计,防尘抗干扰,多种安装方式,能快捷灵活地嵌入到各种智能设备。

丰富的外部接口
AIO-3399C(AI)可采用POE+(802.3 AT,输出功率 30W)增强型以太网供电,拥有RS232、RS485以及2路TTL等外部扩展接口,方便连接各种工业设备,轻松实现产品应用。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









