





引言
为了克服递归网络(RNN)学习长期依赖的困难,长短期记忆(LSTM)网络于1997年被提出并后续在应用方面取得了重大进展。大量论文证实了LSTM的实用性并试图分析其性质。而“RNN和LSTM是否具有长期记忆?”这个问题依然缺少答案。本论文从统计学的角度回答了这一问题,证明了RNN和LSTM在做时间序列的预测时不具备统计意义上的长期记忆。统计学已有的对于长期记忆的定义并不适用于神经网络,于是我们提出了一个对于神经网络适用的新定义,并利用新定义再次分析了RNN和LSTM的理论性质。为了验证我们的理论,我们对RNN和LSTM进行了最小程度的修改,将他们转换为长期记忆神经网络,并且在具备长期记忆性质的数据集上验证了它们的优越性。
相关背景
尽管在深度学习领域,长期记忆这个词经常在LSTM的应用中被提到,但是并没有严格的定义。而在统计领域,对于长期记忆的严格定义很早就有了。对于一个二阶平稳的一维时间序列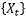 ,记它的自协方差函数为
,记它的自协方差函数为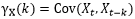
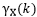 不可和,则
不可和,则
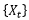 具有长期记忆;如果
具有长期记忆;如果
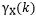 可和,则
可和,则
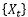 具有短期记忆。除了自协方差函数之外,还可以等价地用谱密度函数来定义长期或短期记忆。更严谨的表述见下图中定义一。
具有短期记忆。除了自协方差函数之外,还可以等价地用谱密度函数来定义长期或短期记忆。更严谨的表述见下图中定义一。

符合长期记忆定义的一种最常见的时间序列模型就是分数差分过程(fractionally integrated process)。在时间序列分析中,时间序列的简写一般会使用后移运算符(backshift operator)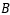 。当作用于时间序列中的一个随机变量
。当作用于时间序列中的一个随机变量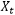 时,会获得前一时刻的随机变量
时,会获得前一时刻的随机变量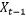 ,即
,即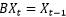 。后移运算符的运算与一个代数变量的运算非常相似,例如
。后移运算符的运算与一个代数变量的运算非常相似,例如
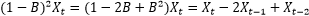 。利用后移运算符,一个分数差分过程
。利用后移运算符,一个分数差分过程
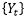 可以很方便地写作
可以很方便地写作
 是Gamma函数,
是Gamma函数,
 是分数差分模型的记忆参数。一般
是分数差分模型的记忆参数。一般
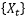 会被选取为一个自回归滑动平均模型(Autoregressive moving-average model,简称ARMA模型),此时
会被选取为一个自回归滑动平均模型(Autoregressive moving-average model,简称ARMA模型),此时
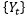 服从分数差分整合移动平均自回归模型(Autoregressive fractionally-integrated moving-average model,简称ARFIMA模型)。一个ARFIMA模型中的ARMA部分负责对短期记忆的规律进行建模,而分数差分的参数
服从分数差分整合移动平均自回归模型(Autoregressive fractionally-integrated moving-average model,简称ARFIMA模型)。一个ARFIMA模型中的ARMA部分负责对短期记忆的规律进行建模,而分数差分的参数
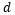 则负责对长期记忆的规律进行建模。
长期记忆对于多维度的时间序列来说并没有唯一的定义。我们选择了一种简单直接的方式来定义多维时间序列的长期记忆,那就是检查时间序列的各个维度是否具有长期记忆,忽略不同维度之间的长期相关性。每个维度
则负责对长期记忆的规律进行建模。
长期记忆对于多维度的时间序列来说并没有唯一的定义。我们选择了一种简单直接的方式来定义多维时间序列的长期记忆,那就是检查时间序列的各个维度是否具有长期记忆,忽略不同维度之间的长期相关性。每个维度
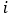 都有一个记忆参数
都有一个记忆参数
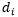 来对该维度进行建模。多维度时模型的简写见(4)式。
来对该维度进行建模。多维度时模型的简写见(4)式。
ARFIMA模型是本文的重要灵感来源之一。它的一些重要性质包括:
 在-0.5到0.5之间时,模型是平稳的,大于0.5时,模型非平稳;
在-0.5到0.5之间时,模型是平稳的,大于0.5时,模型非平稳;
对于平稳模型来说,
小于0时模型具有短期记忆,而大于0时,模型具有长期记忆,且的值越大,记忆效果越长;(3)式中的系数,随
 的增大,以多项式速率衰减,即
的增大,以多项式速率衰减,即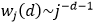 ;
;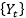 的自协方差函数以多项式速率衰减。
的自协方差函数以多项式速率衰减。
在证明模型的自协方差函数衰减速率时,我们借助了几何遍历性这一性质来辅助证明,具体定义见下图。一个具有几何遍历性的马尔科夫链在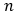 步后的条件分布
步后的条件分布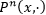 ,随着的增大以指数速率收敛向平稳分布
,随着的增大以指数速率收敛向平稳分布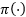 。这意味着马尔科夫链“现在处在
。这意味着马尔科夫链“现在处在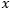 状态”的这个信息以指数速率丢失了。几何遍历性意味着自协方差函数以指数速率收敛为0,意味着随机过程不具有长期记忆。
状态”的这个信息以指数速率丢失了。几何遍历性意味着自协方差函数以指数速率收敛为0,意味着随机过程不具有长期记忆。

递归网格的记忆性质
假设一个递归网络的输入为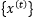 ,输出为
,输出为
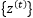 ,以及目标序列为
,以及目标序列为
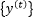 。其中,
。其中,
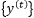 来自模型
来自模型
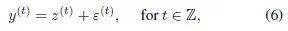
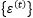 是独立一致分布的白噪声。这一节的理论结果建立在无外生变量的时间序列预测的条件下,即
是独立一致分布的白噪声。这一节的理论结果建立在无外生变量的时间序列预测的条件下,即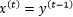 。考虑一个泛指的隐层状态
。考虑一个泛指的隐层状态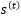 ,那么一个递归网络可以写成马尔科夫链的形式,见(7)式。
,那么一个递归网络可以写成马尔科夫链的形式,见(7)式。
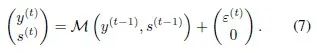
如果转移函数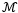 是线性的,那么(7)式成为一个线性马尔科夫链
是线性的,那么(7)式成为一个线性马尔科夫链
(7)式所表达的马尔科夫链其实包含了RNN或者LSTM。
例如,最基本的RNN,使用2-范数损失函数时,模型的前馈计算如(9)式
其中 是输出函数,
是输出函数, 是激活函数。这个RNN可以写成(7)式中的马尔科夫链的形式
是激活函数。这个RNN可以写成(7)式中的马尔科夫链的形式
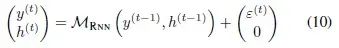
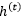 就是RNN原本的隐藏层单元,以及转移函数的具体形式为
就是RNN原本的隐藏层单元,以及转移函数的具体形式为
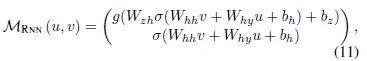
又例如,基本的LSTM网络,前馈过程为
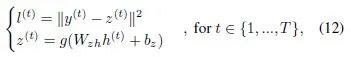
隐藏层单元 的计算涉及如下门运算
的计算涉及如下门运算
 是输出函数,
是输出函数,
 是sigmoid激活函数,tanh是双曲正切激活函数。这个LSTM过程也可以写成(7)式的形式
是sigmoid激活函数,tanh是双曲正切激活函数。这个LSTM过程也可以写成(7)式的形式
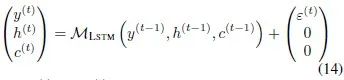
不过在LSTM中,隐藏层单元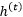 和单元状态
和单元状态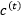 一起对应(7)中的泛指隐层单元
一起对应(7)中的泛指隐层单元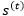 。转移函数
。转移函数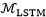 的形式较为复杂,就不在这里展示了。
的形式较为复杂,就不在这里展示了。

定理一还比较抽象,转移函数上的条件,并不能直观地转换成在网络里的权重和激活函数上的条件。于是我们又进一步提出了推理一和推理二。推理一证明了,只要RNN的输出和激活函数是连续且有界的,那么RNN就具有短期记忆,如下图。

而推理二提出了LSTM具有短期记忆的充分条件。一个是输出函数上的条件,目前常用的线性、ReLU、sigmoid或者tanh等输出函数均满足要求;另一个是要求遗忘门的输出严格小于1。推理二从侧面反映了LSTM的遗忘门是LSTM的记忆性质的关键。

以上理论结果建立在无外生变量的前提下,而神经网络在具体应用中是可以带有外部变量进行运算的。外部变量若本身就带有长期记忆性质,会干扰我们对于神经网络记忆性质的分析,所以有外部变量时无法使用现有的统计学上对于长期记忆性质的定义。为了填补这一缺口,我们提出了一种对于神经网络适用的新的长期记忆的定义。假设神经网络可以写成(或近似成)下列形式
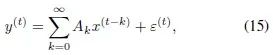
那么如果系数矩阵存在一个维度以多项式速率衰减,则认为网络具有长期记忆。具体表述见定义三。
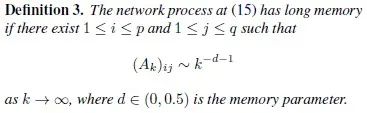
长期记忆递归网格及其性质
根据上述理论成果,我们想对RNN和LSTM做出最小程度的修改,使其获得对长期相关性建模的能力。类似于ARFIMA模型中的结构,我们给RNN和LSTM在不同位置添加了一个长期记忆滤波器,分别得到记忆增强RNN(Memory-augmented RNN,简称MRNN模型)和记忆增强LSTM模型(Memory-augmented LSTM,简称MLSTM模型)。
长期记忆滤波器的具体形式为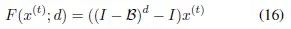
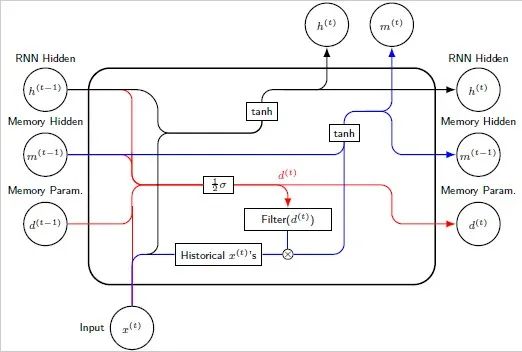
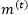 是与普通隐层单元
是与普通隐层单元
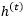 并列运作的新隐层单元,
并列运作的新隐层单元,
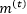 负责捕捉长期记忆的信息,而
负责捕捉长期记忆的信息,而
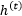 负责对短期的信息进行建模。
负责对短期的信息进行建模。
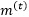 的具体计算如下
的具体计算如下
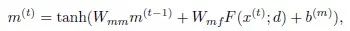
而MRNN整体的向前传输过程可以写作
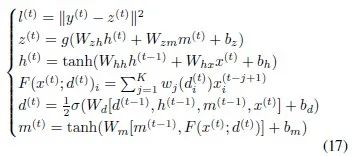
为了分析理论性质,我们需要对模型进行一定的化简。我们把固定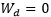 的模型称为MRNNF模型,其中的记忆参数
的模型称为MRNNF模型,其中的记忆参数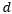 是不随时间变化的。那么对于MRNNF模型,我们分析得到了如下的性质,即MRNNF满足定义三,具有长期记忆,而RNN依然不具有长期记忆。
是不随时间变化的。那么对于MRNNF模型,我们分析得到了如下的性质,即MRNNF满足定义三,具有长期记忆,而RNN依然不具有长期记忆。

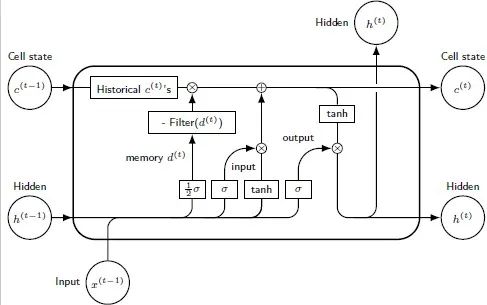
对LSTM的修改,我们将长期记忆滤波器加在了单元状态上,因为LSTM原本的单元状态服从一个动态系数AR(1)模型
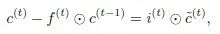
所以我们很自然地把这里的状态更新加上了长期记忆滤波器,得到
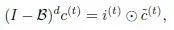
MSLTM网络结构的图例为
向前传播过程为
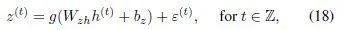
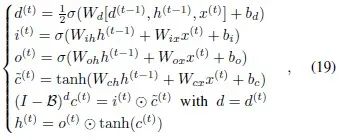
实验结果
我们做了三个实验,一是在具有长期记忆性质的数据集上验证新提出的模型的优势,二是验证新提出的模型在只具有短期记忆性质的数据集上表现不会劣化,三是探究长期记忆滤波长度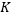 这一超参数对模型表现的影响。
这一超参数对模型表现的影响。
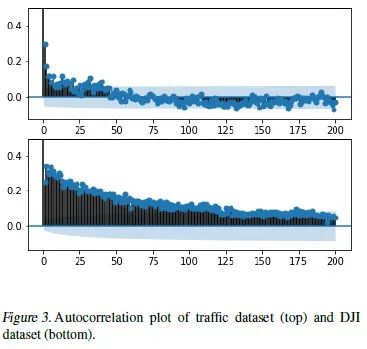
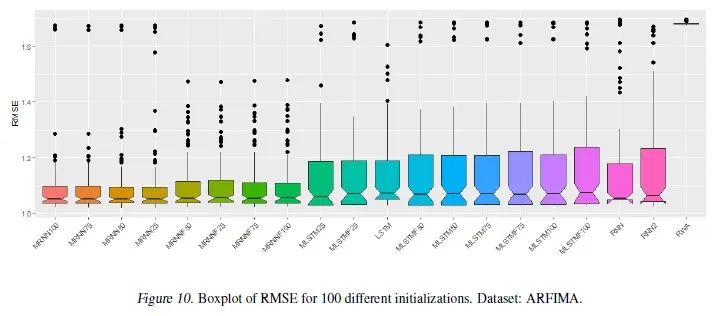
我们首先选用了四个具有长期记忆性质的数据集用于时间序列预测任务:由ARFIMA模型生成的序列,道琼斯股指的收益,明尼阿波利斯的地铁人流量数据,以及树的年轮宽度数据。这些数据集的长期记忆性质可以通过画样本的自相关函数来判断,比如下图中的自相关函数有很长的趋势,与白噪声序列明显不同,直观说明了数据带有长期记忆。
1. 原始RNN,lookback = 1;
2. 双轨RNN(类似MRNN),但是滤波器部分不加限制,有 个自由权重;
个自由权重;
3. Recurrent weighted average network (RWA);
4. MRNNF,即记忆参数 不随时间变化;
不随时间变化;
5. MRNN,即记忆参数随时间变化;
6. 原始LSTM;
7. MLSTMF,即记忆参数不随时间变化;
随时间变化。
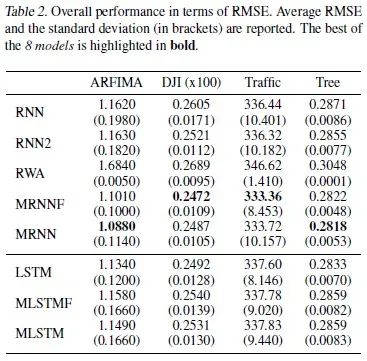
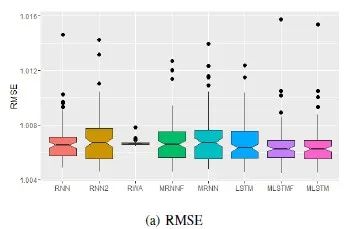
由于这些网络的训练是非凸问题,我们用不同的种子初始化模型会学到不同的模型,所以我们使用了100个不同的种子,并报告时间序列预测任务的误差度量的均值,标准差,以及最小值。
误差的均值和标准差见表2,最小值见表3。
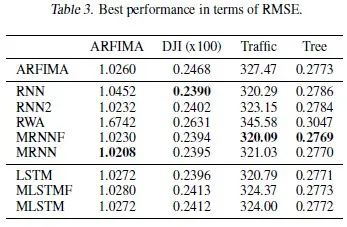
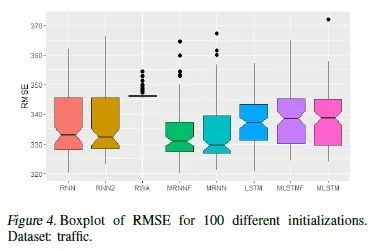
我们将100个随机数种子学出来的100个模型的表现画了boxplot,例子见图4。用两样本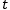 -检验对比MRNN和RNN / LSTM的表现,结论显示MRNN的优势是显著的。
-检验对比MRNN和RNN / LSTM的表现,结论显示MRNN的优势是显著的。
此外,我们还在西班牙语论文评议数据集上测试了我们提出的长期记忆模块在多层神经网络中的应用。为了提升效率,我们固定了记忆参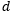 不随时间变化,设置滤波长度
不随时间变化,设置滤波长度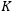 为50,且只在第一层使用带滤波器的结构。网络的第二层统一为LSTM单元,对比结果如下。虽然MLSTM和MLSTMF在时间序列预测数据集上优势不明显,但是在这个自然语言处理的分类任务上,优势则很明显了。用两样本-检验对比MLSTMF和RNN/LSTM的准确率,p-value均小于0.05。
为50,且只在第一层使用带滤波器的结构。网络的第二层统一为LSTM单元,对比结果如下。虽然MLSTM和MLSTMF在时间序列预测数据集上优势不明显,但是在这个自然语言处理的分类任务上,优势则很明显了。用两样本-检验对比MLSTMF和RNN/LSTM的准确率,p-value均小于0.05。

第二个实验,我们用RNN生成了数据,并用8个模型去做预测,结果如下图。除了新模型方差略微变大之外,并没有明显劣势。说明我们的新模型也适用于长短期记忆混合的数据集。
 对于模型表现的影响。实验选取了
对于模型表现的影响。实验选取了
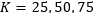 和100四种情况进行对比。结论是MRNN在
和100四种情况进行对比。结论是MRNN在
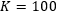 时表现最好,而MLSTM在
时表现最好,而MLSTM在
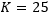 时表现最好,我们推测可能是由于MLSTM模型较大难以训练造成的。
时表现最好,我们推测可能是由于MLSTM模型较大难以训练造成的。
结语
本文首先从时间序列的角度证明RNN和LSTM没有长期记忆。通过使用分数整合过程中的滤波器结构,我们对RNN和LSTM做出了相应的修改,使得它们可以处理带有远程依赖的数据。在时间序列预测任务中,MRNN和MRNNF在各个数据集上都展现出了优势,而MLSTM和MLSTMF的性能与原始LSTM相当,并受到滤波长度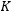 的影响。而在论文评议分类任务中,MLSTMF搭配LSTM的双层网络的表现显著好于两层LSTM的网络。
在将来的工作中,我们可以继续探究类似的滤波器是否可以为其他递归网络或前馈网络带来类似的优势。此外,与其他模型相比,具有动态
的影响。而在论文评议分类任务中,MLSTMF搭配LSTM的双层网络的表现显著好于两层LSTM的网络。
在将来的工作中,我们可以继续探究类似的滤波器是否可以为其他递归网络或前馈网络带来类似的优势。此外,与其他模型相比,具有动态
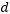 的MRNN和MLSTM计算开销较大,将来可以探究模型的进一步化简,和探索更快的优化方法。最后,根据定义3,我们还可以尝试许多其他信息衰减模式来对长期记忆序列进行建模。例如,我们可以直接让滤波器的权重
的MRNN和MLSTM计算开销较大,将来可以探究模型的进一步化简,和探索更快的优化方法。最后,根据定义3,我们还可以尝试许多其他信息衰减模式来对长期记忆序列进行建模。例如,我们可以直接让滤波器的权重
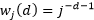 。
。
— 完 —
欢迎有才华的您与我们一起,迎接人工智能的大航海时代!
诺亚方舟实验室(Noah's Ark Lab) 是华为公司从事人工智能基础研究的实验室,致力于推动人工智能领域的技术创新和发展,并为华为公司的产品和服务提供支撑。
简历投递:请发送简历至Noahlab@huawei.com,邮件标题“应聘职位+姓名”
— Welcome Aboard!—















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









