





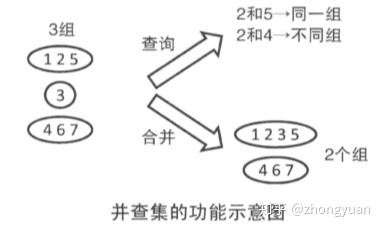
1.并查集是什么
并查集是一种用来管理元素分组情况的数据结构。它虽然可以进行合并操作,但是无法进行分割操作。并查集可以高效地完成如下操作:
- 查询元素a和元素b是否属于同一组
- 合并元素a和元素b所在的组
2.并查集的结构
并查集也是使用树形结构实现的。不过,注意不是二叉树
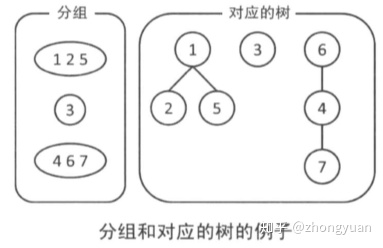
每个元素对应一个结点,每个组对应一棵树。在并查集中,哪个节点是哪个节点的父亲以及树的形状等信息无需多加关注,整体组成一个树形结构才是重要的。
(1)初始化
准备n个节点表示n个元素。最开始时没有边。

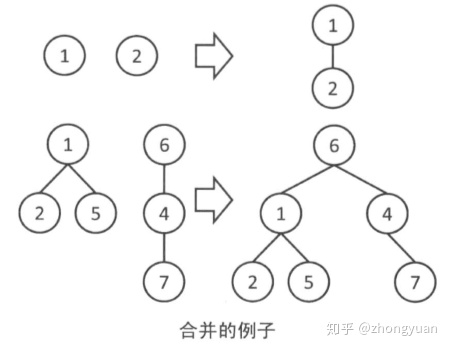
(2)合并
像下图一样,从一个组的根向另一个组的根合并,这样两颗树就变成了一棵树,也就把两个组合并成了一个组。
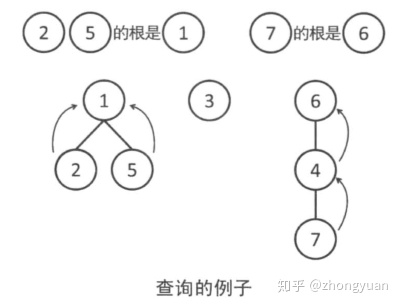
(3)查询
为了查询两个节点是否属于同一组,需要沿着树向上走,来查询包含这个节点的树的根是谁。如果两个节点走到了同一个根,那么就可以知道它们属于同一组。
例如下图中的2和5都走到了1,因此它们是同一组,而7走到了6,因此同2和5属于不同组。
3.并查集实现中的注意点
正如1,2,3,4,5组成的二叉搜索树一样,树形结构会发生退化的情况,复杂度就会变高。为了避免这种退化,并查集中提供了如下方法:
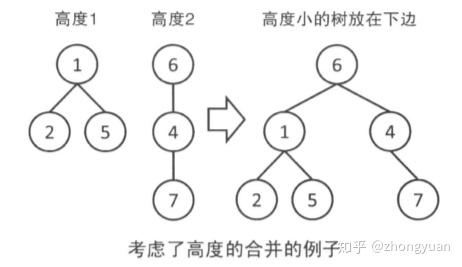
- 对于每棵树,记录这棵树的高度(rank)
- 合并时如果两颗树的rank不同,那么从rank小的向rank大的连边。:造成这种退化的原因是树的高度太高,没有充分利用树形结构一对多的特点,如果将rank大的向rank小的连边,那么树的高度会更高,从而使查并集退化,因此只有将rank小的向rank大的连边,才能尽可能地维持树的高度不再增加。
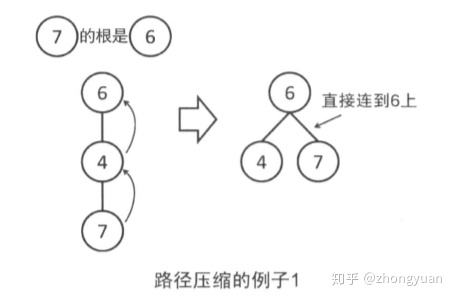
此外,通过路径压缩,可以使得并查集更加高效。对于每个节点,一旦向上走到了一次根节点,就把这个点到父节点的边改成直接连向边。
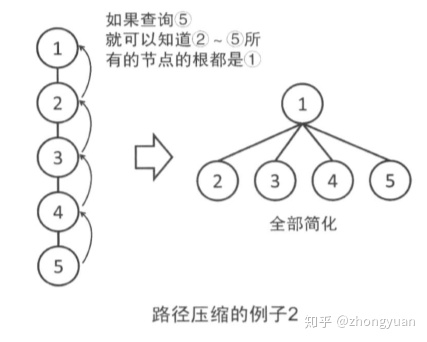
在此之上,不仅仅是所查询的节点,在查询过程中向上经过的所有的节点,都改为直接连到根上。这样再次查询这些节点时,就可以很快知道根是谁了。
注意:在使用这种简化方法时,为了简单起见,即使树的高度发生了变化,我们也不修改rank的值。
4.并查集的复杂度
加入了上面两个优化的查并集,对n个元素的查并集进行一次操作的复杂度使O(a(n)),a(n)是阿克曼(Ackermann)函数的反函数。这比O(log(n))还要快。
不过,这是“均摊复杂度”。也就是说,并不是每一次操作都满足这个复杂度,而是多次操作之后平均每一次的复杂度是O(a(n))的意思。
5.查并集的实现
下面是一个例子,在例子中,用编号代表每个元素。数组par表示的是父亲的编号,par[x]=x,x是所在树的根。
int par[MAX_N];//父亲
int rank[MAX_N];//记录每棵树的高度
//初始化n个元素
void init(int n)
{
for(int i = 0;i < n; i++)
{
par[i] = i;
rank[i] = 0;
}
}
//查询树的根
int find(int x)
{
if(par[x] = x)//前面的的条件:存储的元素等于编号就是树的根
{
return x;
}
else//否则,递归它相应的下标,par存储的是父节点
{
return par[x] = find(par[x]);//继续寻找x的父节点,并且将x到根节点路径上的所有节点与根节点连接
}
}
//合并x和y所属的集合
void unite(int x,int y)
{
x = find(x);//x所属的根
y = find(y);//y所属的根
if(x == y)//根相同,属于同一组
return;
if(rank[x] < rank[y])//高度小的合并到高度大的树上
{
par[x] = y;
}
else
{
par[y] = x;
if(rank[x] == rank[y]) rank[x]++;//高度相同,将其中一个增加1,以区别高度
}
}
//判断x和y是否属于同一集合
bool same(int x,int y)
{
return find(x) == find(y);
}
6.需要用到并查集的问题
直接上例题:


从题目中的限定可以看出,N和K都很大。所以必须高效地维护动物之间的关系,并快速判断是否产生矛盾。并查集是维护“属于同一组”的数据结构,但是这里动物的关系多了类别关系和捕食关系,因此必须重新定义并查集来维护这些关系。
对于每个动物i,因为其只能归属于A,B,C三个类,因此为i创建3个维度即 i-A、i-B、i-C,并用3×N个元素建立并查集。这个并查集维护如下信息:
- i-x表示“i属于物种x(x∈{A,B,C})”
- 并查集里的每一组表示组内所有元素代表的情况都同时发生或不发生。(核心操作且难理解)
例如,如果i-A和j-B在同一个组内,就表示如果i属于A类,则j一定属于B类,如果j属于B类那么i一定属于A类。因此整个并查集中,只有两类关系被维护,即:
- 第一种:x和y属于同一类,那么并查集中合并x-A和y-A、x-B和y-B、x-C和y-C,之所以三个类都合并,是因为在第一种关系中,我们并不关心x和y具体属于哪一类,只关心它们属于同一类就可以了
- 第二种:x吃y,即捕食关系,那么并查集中合并x-A和y-B,x-B和y-C、x-C和y-A。将所有的捕食关系都合并,这同样是因为我们只在乎x和y是捕食关系,而不在乎他们是哪种捕食关系。
但是注意在每种关系合并前,都需要对他们的是否产生矛盾进行判断。例如在第一种关系下,需要检查比如x-A、x-B和x-C是否在同一组。
代码实现
//输入(T是信息的类型,这里只取1或2)
int N,K;
int T[K],X[K],Y[K];//X和Y代表输入
//这里省略了查并集实现的代码,在上面
void solve()
{
//初始化查并集
//元素下x,x+N,x + 2*N,分别代表x-A,x-B,x-C,A=0代表A类,B=N代表B,C=2*N代表C
init(3*N);//建立3*N的查并集
int ans = 0;//记录结果,错误信息数
for(int i = 0; i < K; i++)
{
int t = T[i];//取得当前的信息类型
int x = X[i]-1,y = Y[i]-1;//因为查并集是从0开始的,所以将输入也转移到[0,N-1]的区间
//排除不争取的编号
if(x < 0 || x >= N || y < 0 || y >= N)
{
ans++;//错误信息计数
continue;//结束本次循环
}
if(t == 1)//第一种关系
{
if(same(x,y+N) || same(x,y+2*N));//第一个判断代表,A吃B,B吃C和C吃A的组,第二个判断是A吃C的错误信息
//与第一种同类关系矛盾
ans++;
else
{
unite(x,y);//合并x-A和y-A
unite(x+N,y+N);//合并x-B和y-B
unite(x+2*N,y+2*N);//合并x-C和y-C
}
}
else//第二种关系,x吃y
{
if(same(x,y) || same(x,y+2*N));//第一个判断是x和y同类,第二个判断是A吃C的错误
//与第二种捕食关系矛盾
ans++;
else
{
unite(x,y+N);//合并x-A和y-B
unite(x+N,y+2*N);//合并x-B和y-C
unite(x+2*N,y);//合并x-C和y-A
}
}
printf("%dn",ans);
}














 75
75











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









