





我们可以用Jmeter做接口测试,但是呢个人觉得那个有点局限性,用python就灵活很多,
可以按自己的思路来构建比较灵活,下面给大家介绍一个简单的接口测试实例。
一、我们的思路如下:
首先我们要弄清楚我们的整个思路:
1.先把我们的测试数据准备好,即post的数据(当然get方法也可以发送请求数据)
2.然后我们向指定的URL发送请求(post方法)
3获取repones的结果数据,
4.判断repones结果是否有符合预期的数据
二、我这里举一个注册vpn账号的例子:
下面是我们要通过post方法请求的数据

Headers要先申明类型,然后通过requests.post方法向url发送数据请求。
三、请求数据后我们等待服务器响应,并且获取repones的数据
我们通过text方法获取到响应报文的内容,通过stauts_code获取响应的状态码

四、我们对获取到的报文做判断,是否含有预期的数据在里面
对code进行判断,是否为200,有则表示和服务器会话是正常的
对报文的内容进行判断,验证是否含有预期的数据

五、运行看结果

结果是ok的,可以注册成功
好,到这里我们一个简单的接口测试实例就讲完了。
——————————————————————————————————————————————————————————
一个网站登录接口测试环境的练习
1.登录demo环境,爬取登录后画面的代码。
#coding=utf-8
importcsvimportrandomimportiofrom urllib importrequest,parse,errorimporthttp.cookiejarimporturllibimportrefrom bs4 importBeautifulSoupif __name__=="__main__":defGetWebPageSource(url,values):#url = "https://www.incnjp.com/thread-4578658-1-1.html"
data = parse.urlencode(values).encode('utf-8')#header
user_agent = ""#代理-模拟浏览器,这里为空也可以跑通(只是发送给服务器请求),如果服务器有反爬虫,那么这里需要写浏览器相关的代理信息模拟浏览器(即反反爬虫机制)
headers = {'User-Agent': user_agent, 'Connection': 'keep-alive'}#声明cookie 声明opener
cookie_filename = 'cookie.txt'cookie=http.cookiejar.MozillaCookieJar(cookie_filename)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)#声明request
request =urllib.request.Request(url, data, headers)#得到响应
response =opener.open(request)
html= response.read().decode('utf-8')#保存cookie
cookie.save(ignore_discard=True, ignore_expires=True)returnhtml
url= "http://demo.pingnanlearning.com/test/login/index.php"values= {"username": "sasa","password": "123","phone2": ""}
html=GetWebPageSource(url,values)print(html)
运行结果:
1.判断用户是否登录demo环境成功
#coding=utf-8
importcsvimportrandomimportiofrom urllib importrequest,parse,errorimporthttp.cookiejarimporturllibimportrefrom bs4 importBeautifulSoupif __name__=="__main__":defGetWebPageSource(url,values):#url = "https://www.incnjp.com/thread-4578658-1-1.html"
data = parse.urlencode(values).encode('utf-8')#header
user_agent = ""#这里可以为空(但只是发送给服务器请求-服务器没有反爬虫机智前提下可以跑通);如果服务器有反爬虫,那么我们这里需要写浏览器相关的代理信息(即反反爬虫机制)
headers = {'User-Agent': user_agent, 'Connection': 'keep-alive'}#声明cookie 声明opener
cookie_filename = 'cookie.txt'cookie=http.cookiejar.MozillaCookieJar(cookie_filename)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)#声明request
request =urllib.request.Request(url, data, headers)#得到响应
response =opener.open(request)
html= response.read().decode('utf-8')#保存cookie
cookie.save(ignore_discard=True, ignore_expires=True)returnhtml
url= "http://demo.pingnanlearning.com/test/login/index.php"values= {"username": "sasa","password": "123","phone2": ""}
html=GetWebPageSource(url,values)#判断登陆成功与否
isLogin =False
soup= BeautifulSoup(html, "lxml")
hrefList= soup.select('a[target="_blank"]')for m inhrefList:if m.text == "个人中心":
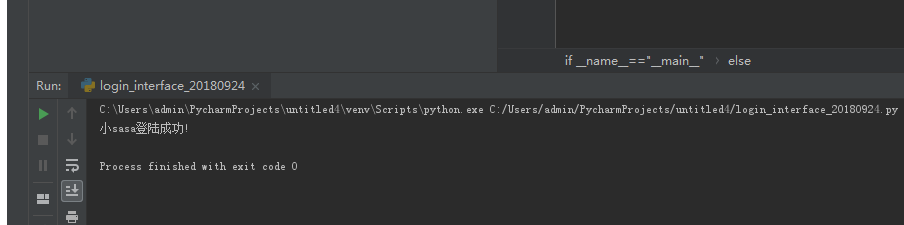
isLogin=TrueifisLogin:print("小sasa登陆成功!")else:print("小sasa登陆失败!")#print(html)
运行效果图:
3.2-面向对象代码优化
#coding=utf-8
importcsvimportrandomimportiofrom urllib importrequest,parse,errorimporthttp.cookiejarimporturllibimportrefrom bs4 importBeautifulSoup#发送请求获得响应
defGetWebPageSource(url, values):
data= parse.urlencode(values).encode('utf-8')#header
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"#这里可以为空(但只是发送给服务器请求-服务器没有反爬虫机智前提下可以跑通);如果服务器有反爬虫,那么我们这里需要写浏览器相关的代理信息(即反反爬虫机制)headers= {'User-Agent': user_agent, 'Connection': 'keep-alive'}#声明cookie 声明opener
cookie_filename = 'cookie.txt'cookie=http.cookiejar.MozillaCookieJar(cookie_filename)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)#声明request
request =urllib.request.Request(url, data, headers)#得到响应
response =opener.open(request)
html= response.read().decode('utf-8')#保存cookie
cookie.save(ignore_discard=True, ignore_expires=True)returnhtml#判断登陆成功与否
defIsResSuccess(html):
isLogin=False
soup= BeautifulSoup(html, "lxml")
hrefList= soup.select('a[target="_blank"]')for m inhrefList:if m.text == "个人中心":
isLogin=Truebreak#退出循环,之后不再循环,继续执行下面的return代码。(continue,当次循环continue下代码不执行,跳出当次循环,继续下一次循环)
returnisLogin#不是每个函数都需要返回值if __name__=="__main__":
url= "http://demo.pingnanlearning.com/test/login/index.php"values= {"username": "sasa","password": "123","phone2": ""}
html=GetWebPageSource(url,values)#判断登陆成功与否
ifIsResSuccess(html):print("小sasa登陆成功!")else:print("小sasa登陆失败!")















 2037
2037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









