





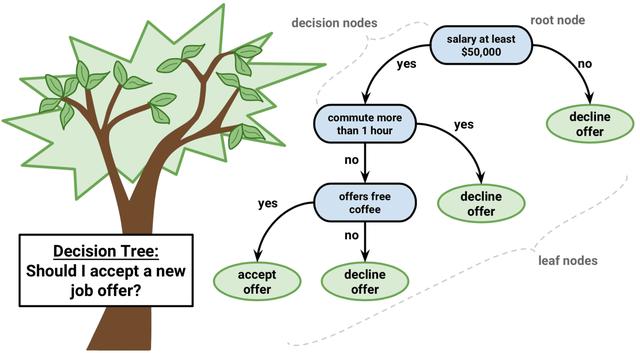
概括
决策树的训练过程是在样本集中,选择当前对样本集最重要的特征并对其进行分割得到子节点的迭代过程,最终生成的树模型将相似样本聚集在一起成为叶子节点,以叶子节点的目标
定义
决策树是一个if-else规则集合,一个实例(样本)进入已训练好的决策树后每次基于一个特征进行划分最终落入一个叶子节点中,该实例的预测结果以该叶子节点结果值为预测值。因此可以将决策树看做特征子空间到预测值的映射关系模型。
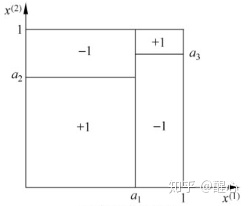
分类问题
决策树一开始是为了解决分类问题,对于决策树的构建有如下两个问题:
- 如何选择最合适的特征
- 选择特征后如何进行划分
ID3
ID3所需基础:信息增益
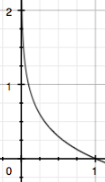
1.信息量:信息量定义了概率为p的事件发生时所产生的信息量大小,表达式如下:
通俗解释:一个发生概率很低的事件发生时产生很大的信息量,反之发生概率很高的时间发生时产生较低的信息量,log(p)函数图像如下:
2.熵:评价某个随机变量的混乱程度,表达式为信息量的期望(log=ln):
通俗解释:如果随机变量的概率分布比较‘极端’如 X=太阳是否升起,p(X=升)=0.99,p(X=不升)=0.01,H(X) = -0.01log(0.01) - 0.99log(0.99) = 0.056。即该随机变量有很小的混乱程度。若X为掷硬币事件,设正反概率均0.5,H(X) = -0.5log(0.5) - 0.5log(0.5) = log(2) = 0.692,随机变量取值若等概率则得到最大熵(随机变量最为混乱)。
3.条件熵:
通俗解释:假设分类问题为依据汽车特征将汽车分类为:Y={轿车、SUV、皮卡、挖掘机},样本特征之一燃油类型为:X={汽油、柴油、EV},条件熵的计算相当于计算每个具体燃油类别下的汽车类别Y的熵 H(Y) 记为,然后求该熵对燃油类型的数学期望。
4.信息增益:
通俗解释:样本集D的目标变量Y的熵 - 目标变量Y在特征X下的条件熵,相当于我用特征X对Y进行切分后,系统的熵的减小幅度(系统混乱程度减小幅度)。
5.信息增益比:
通俗解释:信息增益倾向选择种类多的特征,想象一个训练集有一列index表示样本编号,可将其看做特征,每个index对应一个样本,因此每个index下H(Y)即,因此index条件熵
,信息增益达到最大,但index特征对于样本集毫无用处,因此需要对类别数多的特征进行惩罚,除以该特征的熵(类别数越多,分布越均匀则熵越大越接近log(n)惩罚力度越大)。
第一个问题:如何选择最合适的特征
ID3基于信息增益,每次从可选特征集合中选择信息增益最大的特征然后可选特征集合删除该特征。
第二个问题:如何划分
ID3直接在选定特征下依据特征种类划分为多叉树。
算法的过程为:
1).初始化信息增益的阈值ϵ
2).判断样本是否为同一类输出,如果是则返回单节点树T。标记类别为
![]()
3).备选特征是否为空,如果是则返回单节点树,标记类别为样本实例数最多的类别
![]()
4).计算集中各个特征(一共n个)对目标变量
的信息增益,选择其值最大的特征
![]()
5).若A的信息增益小于阈值ϵ,则返回单节点树,标记类别为样本实例数最多的类别
![]()
6).否则,按特征的不同取值
将
分成不同子集
。每个子节点对应特征值为
,返回增加的节点数T。
7).对于所有的子节点,令,备选特征集-
,递归调用2-6步,得到子树
返回。
ID3分类决策树使用限制与不足:
- 样本特征均为离散特征
- 特征需要无缺失值
- 无正则化项,易过拟合
C4.5
C4.5基本流程和ID3相同,但C4.5是基于信息增益比且可处理连续特征与特征值缺失问题。
1.连续特征处理(切分为两类):假设样本集大小为m,连续特征为A,按特征A从小到大排序样本,以相邻样本均值为切分点,前半部A为
2.缺失值处理:
1).特征信息增益计算问题:假设特征A有40%的缺失率,那么利用无特征A缺失的60%的样本集计算
2).样本划分问题: 假设
3.剪枝:后面统一讨论。
C4.5分类决策树使用限制与不足(同时也是ID3的缺陷):
- 生成的是多叉树,在这些数据量小的切分空间上,统计信息较不准确,树模型复杂易过拟合,泛化性能较差,且多叉树不利于程序优化。
- 只能用于分类。
- 都使用熵模型,对待分化集合每种特征的每种取值计算log值,代价高。
- C4.5的连续值需要排序,每次排序需要O(nlogn),n为待排序集合大小。
CART
CART与ID3、C4.5有较大差别
- CART选定特征后仅分裂为两个子节点而非ID3/C4.5每个特征值分裂一个节点。
- CART可回归。
- 分裂依据为计算更高效的基尼不纯度。
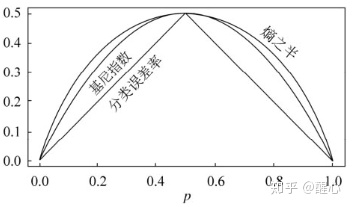
CART分类所需基础:基尼不纯度
1.基尼系数
假设样本集
因此
均等时
取最小值,即样本集类别概率分布越均匀,基尼系数越高,数据整体越‘不纯’越混乱,基尼系数和熵的作用类似,但计算从log变为平方。
2.特征A的条件下,把样本集
通俗解释:根据条件熵的定义,可以将其理解为条件基尼系数,只不过这里只有两部分。
第一个问题:如何选择最合适的特征,第二个问题:如何划分(二切分需搜索最优切分点)
- CART将两个问题合并,1).对于离散特征,不同于ID3/C4.5,CART是二切分,依据特征值枚举所有二切分情况,选择条件基尼系数最小的二切分方式为切分依据。2).对于连续特征,除评判依据变为条件基尼系数外同C4.5,条件基尼系数最小时得到最佳切分点。
- 选择条件基尼系数最小的特征进行二切分。
被选择过的离散特征同样可参与后续的特征选拔,因为CART是二切分,ID3/C4.5是完备切分,除非节点样本集该离散特征取值唯一,否则就还有切分价值,缺失值处理同C4.5。
1).当前节点的数据集为,如果样本个数小于阈值或者没有特征,则返回决策子树。
2).计算样本集的基尼系数,如果基尼系数小于阈值,则返回决策树子树,停止递归。
3).计算当前节点现有的各个特征对数据集依据条件基尼系数计算最优切分点。
4).依据最优特征和特征最优切分方式把数据集划分成左右节点
![]()
。
5).对左右的子节点递归的调用1-4步,生成决策树。
回归问题
CART除了分类也可以回归,建立CART回归树时不再利用基尼指数作为特征选择依据是使用平方误差。
CART回归所需基础:最小平方误差
通俗解释:在某特征下选择最佳二切分策略,使得切分后的两个子集的平方误差(相对于子集各自均值)和最小。然后选出效果最好的特征A。
将CART回归和CART分类看做一种模型,两者区别在于CART回归的划分依据为平方误差,然后回归以叶子节点样本均值为预测结果,分类以样本数最多的label为预测结果,其余相同。
离散特征问题
CART涉及到离散特征最优切分策略查找,单纯枚举所有二切分方式查找其时间复杂度为指数为特征值数量k的指数级复杂度,而且现有sklearn和XGboost均不支持识别离散特征,因此需要对离散特征数值化。
- 离散特征若有序列关系,直接编码即可。
- 如果是做树回归或二分类(可看做label有数值大小关系),可以按照每个类别值对应的label均值(leave-me-out,否则将本身的label算进去相当于数据泄露了)进行排序,相当于利用label均值对离散特征进行数值化处理,然后按照排序的结果依次枚举最优分割点。
- 多分类时,离散特征取值较少时可one-hot,较多且分布均匀时由于one-vs-rest导致切分意义不大。
- 多分类时,离散特征取值较多时可做embedding、自编码、改为one-vs-rest二分类问题。
后剪枝
目标函数
对于不同的树模型,其损失函数的形式是相同的,假设树为
对于ID3/C4.5可以叶子节点数据集熵的加权和为训练误差
通俗解释:熵的加权和越小说明树对训练集拟合效果越好,树模型使得整体数据分布非常有规矩。正则项希望树的节点少一些,增强树的泛化性能。
对于CART分类,训练误差是叶子节点数据集基尼不纯度系数加权和
对于CART回归,训练误差是所有样本平方误差总和
剪枝
当α=0时,即没有正则化,原始的生成的CART树即为最优子树。当α=∞时,即正则化强度最大,此时单节点树为最优子树。对于固定的α,一定存在使损失函数
对于决策
如果将其剪掉,退化为根节点
当α较小时正则强度小,因此不剪枝的整体结构损失值
针对子树
算法流程
对决策树除叶子节点外所有节点代表的子树
- 对所有计算的
排序,
从0起每次取值为最小
值。
- 对上步
对应的节点剪枝得到剪枝树
,剪之后
不变。
- 不断重复至
退化为单节点(此时对应一个很大的α)得到剪枝树集合{
},对应的α为{
}。
- 上步剪枝树集合对应的结构化误差相等,采用交叉验证选择最优子树
。
reference
《统计学习方法》-李航
决策树算法原理(上) - 刘建平Pinard - 博客园
决策树算法原理(下) - 刘建平Pinard - 博客园
一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉_史丹利复合田的博客-CSDN博客
关于sklearn中的决策树是否应该用one-hot编码?
cart树怎么进行剪枝















 4775
4775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









