







 本文介绍了CART算法,一种用于构建决策树的方法。CART通过选择最优特征和切分点来生成二叉树,适用于回归和分类问题。在回归问题中,它基于误差平方和准则;在分类问题中,使用基尼系数。文章详细阐述了CART的生成算法,并提及了最小二乘回归树的生成步骤。最后,提到了Python实现CART算法的流程。
本文介绍了CART算法,一种用于构建决策树的方法。CART通过选择最优特征和切分点来生成二叉树,适用于回归和分类问题。在回归问题中,它基于误差平方和准则;在分类问题中,使用基尼系数。文章详细阐述了CART的生成算法,并提及了最小二乘回归树的生成步骤。最后,提到了Python实现CART算法的流程。
1 CART算法
CART 是在给定输入X条件下输出随机变量Y的条件概率分布的学习方法。CART二分每个特征(包括标签特征以及连续特征),经过最优二分特征及其最优二分特征值的选择、切分,二叉树生成,剪枝来实现CART算法。对于回归CART树选择误差平方和准则、对于分类CART树选择基尼系数准则进行特征选择,并递归调用构建二叉树过程生成CART树。
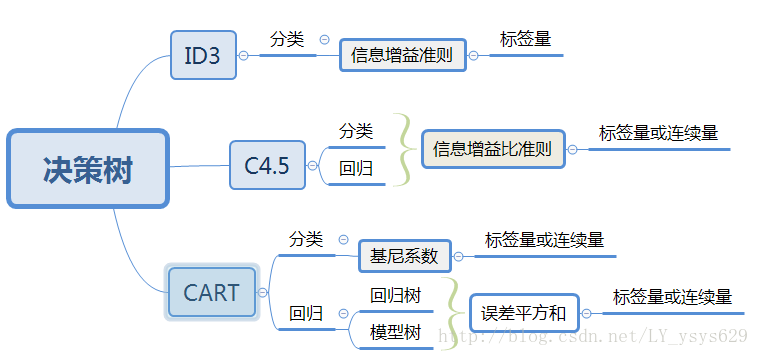
决策树的经典算法包括ID3、C4.5、CART算法,其应用领域及所使用的准则,如下图所示。
2 CART生成算法
- 最小二乘回归树生成算法
之所以称为最小二乘回归树,是因为,回归树以误差平方和为准则选择最优二分切点,该生成算法在训练数据集上所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域的输出值,在这里分为两种情况,一是输出值为子区域输出值的均值该种情况下为回归树,二是输出值为子区域输入与输出的线性回归,输出值为回归系数,该种情况下为模型树。
算法实现步骤:
1)选择最优切分特征J与切分点s,按照如下原则:
minj,s[minc1∑(yi−c1)+minc2∑(yi−c2)]
c1,c2分别为左右子区域输出的均值(模型树时是输出变量的回归值),可通过遍历每个变量的每个可能取值来切分数据集找出最优切分点。
2)用切分点划分区域并决定相应的输出值
3)递归调用1)2)直到满足停止条件
4)利用字典,递归调用创建二叉树,生成决策树 - CART生成算法(分类树)
在这里需要提一下基尼系数:
在分类问题中,假设有K类,样本点属于第k 类的概率为p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











