






输入文件为:

把统计的IP 和每个ip的总数存入到mysql中
1、自定义类,该类实现了从日志记录中判断数据是否合格
public class TextLine {
private String ip;
//标识数据是否合法
private boolean flag = true;
public TextLine(String line){
//检验一行日志数据是否符合要求,如不符合,将其标识为不可用
if(line == null || "".equals(line)){
this.flag = false;
return;
}
String[] strs = line.split(" ");
if(strs.length < 2){
this.flag = false;
return;
}
ip = strs[0];
}
public boolean isRight(){
return flag;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
}
2、自定义输出格式类
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
//向mysql中写入数据
public class TblsWritable implements Writable, DBWritable{
String ip;
int count;
public TblsWritable() {
}
public TblsWritable(String ip, int count) {
this.ip = ip;
this.count = count;
}
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, this.ip);
statement.setInt(2, this.count);
}
public void readFields(ResultSet resultSet) throws SQLException {
this.ip = resultSet.getString(1);
this.count = resultSet.getInt(2);
}
public void write(DataOutput out) throws IOException {
out.writeUTF(ip);
out.writeInt(count);
}
public void readFields(DataInput in) throws IOException {
ip = in.readUTF();
count = in.readInt();
}
}
3、写mapreduce实现类
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
//分析网络服务器上的Apache日志,统计每个IP访问资源的次数,并将结果写入到mysql数据库中。
public class IPCountMR {
public static class IPCountMap extends Mapper{
private IntWritable one = new IntWritable(1);
private Text k = new Text();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//判断该行数据是否合法
TextLine textLine = new TextLine(line);
if (textLine.isRight()) {
k.set(textLine.getIp());
context.write(k, one);
}
}
}
public static class IPCountReducer extends Reducer{
@Override
public void reduce(Text key, Iterablevalues, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(new TblsWritable(key.toString(), sum), null);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",
"jdbc:mysql://192.168.10.1:3306/hadoop", "root", "root");
// 新建一个任务
Job job = Job.getInstance(conf, "ip-count");
// 设置主类
job.setJarByClass(IPCountMR.class);
// 输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// Mapper
job.setMapperClass(IPCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// Reducer
job.setReducerClass(IPCountReducer.class);
job.setOutputKeyClass(TblsWritable.class);
job.setOutputValueClass(TblsWritable.class);
// 输出格式
job.setOutputFormatClass(DBOutputFormat.class);
// 输出到哪些表、字段
DBOutputFormat.setOutput(job, "log", "ip", "count");
// 添加mysql数据库jar
job.addArchiveToClassPath(new Path("/lib/mysql/mysql-connector-java-5.1.18-bin.jar"));
//提交任务
job.waitForCompletion(true);
}
}
其中把mysql的驱动包mysql-connector-java-5.1.18-bin.jar上传到HDFS中
打包上传到服务器运行
[sparkadmin@hadoop4 test]$ hadoop jar ipcount.jar /tom
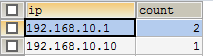
在mysql中查看














 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









