






前言
我想很多人对正则不是很了解,一个原因是受限于应用场景,另一个可能太依赖百度,总归一个词「 懒 」。
今天的笔记将会介绍正则捕获、零宽断言等知识点,希望你有收获。如果有不足的地方,可以留言补充。
基础
正则的基础可以分两类来学习,一个重点是 元字符 ,另一个是 修饰符 。元字符
如果把所有元字符列出来,不是很容易记忆,那么我们就分类:

「 表示相对 」
它们区别只是大小写,却表示相反的含义。| \w 表示数字字母下划线,例:a3_ | \W 表示非数字字母下划线 |
| \d 表示数字 | \D 表示非数字 |
| \s 表示空白符 | \S 表示非空白符 |
| \b 匹配单词边界 | \B 匹配非单词边界 |
\b,还有限定起始^和限定结尾的$。
//以Hello为左边界
/\bHello/.test("Hello World"); //true
//以ld为右边界
/ld\b/.test("Hello World"); //true
//3d、_d、ed都是true,必须以数字、字母、下划线开始,以d结尾
/^\wd$/.test("ed");
「 表示次数 」
字面量创建的正则,里面的每个元素都表示元字符,如果后面不加如下量词,只能匹配到一个。| + 表示一到多次 |
| * 表示零到多次 |
| ? 表示零到一次 |
| {n} 表示匹配n个 |
| {n , m} 表示匹配n到m个 |
| {n,} 表示匹配n个以上 |
//匹配一到多个
/\w+/.test("Hello"); //true
//匹配0到1个
/ed?/.test("e"); //true
//匹配0到多个
/ed*/.test("eddd"); //true
//匹配3个数字
/\d{3}/.test("234"); //true
看起来很简单,但往往会造成错觉,在没有边界限定的情况下,正则匹配到就会返回true,不信你看下边:
/ed*/.test("r reddd"); //true
/^ed*$/.test("ed"); //true
/^ed*$/.test("e"); //true
/^ed*$/.test("r reddd"); //false
test
方法,匹配到就为
true
。
「 表示或 」
表示或的元字符常用的有两个
|
和
[]
。中括号内的每个元字符表示字符串内可能存在。
/3|4/.test("3rr"); //true
/3|4/.test("w4"); //true
/3|4/.test("w"); //false
/[3,4]/.test("we4c"); //true
/[3,4]/.test("we3c"); //true
/[3,4]/.test("wec"); //false
()
。
//不能这么写
/^3|4$/.test("33333333333334"); //true
/^(3|4)$/.test("3"); //true
/^(3|4)$/.test("4"); //true
/^(3|4)$/.test("34"); //false
\d,我们还可以用[0-9]表示,同样2到7,我们也可以用[2-7]来表示。[A-Z]表示从大写字母A到Z;[a-z]表示从小写字母a到z。
同样我们可以表示反向,比如
[^abc]表示匹配除了abc之外的任意字符。
/^[0-9A-Za-z_]+$/
相当于
/^\w+$/
/^[^\s]+$/
相当于
/^\S+$/
「 不常用的特殊元字符 」
| . | 表示除\n(换行符)之外的任意字符 |
| \n | 查找换行符 |
| \f | 查找换页符 |
| \r | 查找回车符 |
| \t | 查找制表符 |
| \v | 查找垂直 |
| \xxx | 查找以八进制数 xxx 规定的字符。 |
| \xdd | 查找以十六进制数 dd 规定的字符。 |
| \uxxxx | 查找以十六进制数 xxxx 规定的 Unicode 字符。 |
修饰符比较简单,也只有三个:
i 表示忽略大小写;
g 表示全局匹配;
m 表示执行多行匹配;
"Visit W3School".match(/w3school/i);//["W3School"]
"\nIs th\nis it?".match(/^is/m);//["is"]
"Is this all there is?".match(/is/g);//["is", "is"]
正则捕获
实现正则捕获的方式有两种:
一种 是正则RegExp.prototype上的方法,有exec、test ; 一种是字符串方法,有match、split、replace等等 。在了解捕获之前,先了解一下正则对象有哪些常用的方法:
1、compile
主要用于改变和重新编译正则,大多数用于转变规则,但其实很鸡肋,对我们没什么用处,如下
let str="Every man in the world! Every woman on earth!";
let patt=/man/g;
let str2=str.replace(patt,"person");
console.log(str2)
//"Every person in the world! Every woperson on earth!"
patt=/(wo)?man/g;
//加不加,其实都一样
patt.compile(patt);
str2=str.replace(patt,"son");
console.log(str2)
//"Every son in the world! Every son on earth!"
exec
用于检索字符串中的正则表达式的匹配。匹配成功有值的话返回一个数组,里头存放匹配的结果,如果没找到匹配项则返回null。
let str = "Every man in the world! Every woman on earth!";
let res =/\w/g.exec(str);
console.log(res);
// res = [
// 0: E,
// index: 0,
// input: "Every man in the world! Every woman on earth!",
// groups: undefined,
// length: 1
// ];
res=/\d/g.exec(str);
//null
test
用于检测一个字符串是否匹配某个模式,如果字符串中含有匹配的文本,则返回 true,否则返回 false。
实现正则捕获的前提是:「当前正则要与字符串匹配,如果不匹配捕获到的结果为null」。
基于 exec实现正则 的捕获:数组的第一项是捕获到的内容;
其余项是分组单独捕获的内容;
index是当前捕获内容在字符串中的起始索引;
input是原始字符串;
lastIndex
属性,表示当前正则下一次匹配的起始索引位置。但是这个属性不可以手动修改,只能通过一次次调用来自动修改。
当全部捕获后,再次捕获的结果是
null
,
lastIndex
的值就会回归初始值0,再一次循环
。
还有一点需要注意:「
在匹配过程中,如果再使用正则的其他方法(如:test)匹配,lastIndex也会改变
」。
我们就可以编写一个方法execAll来实现捕获所有匹配到的结果:
~(function() {
function execAll(str = "") {
//验证当前是否全局匹配,防止死循环
if (!this.global) return this.exec(str);
let ary = [],
res = this.exec(str);
//通过每次捕获的结果是否存在
while (res) {
ary.push(res[0]);
res = this.exec(str);
}
return ary.length === 0 ?null:ary;
}
RegExp.prototype.execAll = execAll;
})();
let reg =/\d+/g;
reg.execAll("weew234sssfdf34fd90");
//["234", "34", "90"]
exec
来实现字符串捕获,像
execAll
的方法,其实在字符串中已经提供。
基于
字符串match
的捕获
"weew234sssfdf34fd90".match(/\d+/g);
//["234", "34", "90"]
「分组捕获」
在正则中添加小括号,可以实现分组捕获。 例如: 我们对身份证的捕获let str="14222619960711072X";
let reg=/^(\d{6})(\d{4})(\d{2})(\d{2})(\d{2})(\d)(\d|X)$/;
str.match(reg);
// [
// "14222619960711072X",
// "142226", //区号
// "1996", //出生年
// "07", //月
// "11", //日
// "07",
// "2", //奇数为男,偶数为女
// "X",
// index: 0,
// input: "14222619960711072X",
// groups: undefined
// ]
(?: pattern)
来设置
/^(\d{6})(\d{4})(\d{2})(\d{2})(\d{2})(\d)(?:\d|X)$/)
match的局限性
利用macth可以直接匹配到所有正则匹配到的内容,但是多次匹配的情况下,match无法获取到小分组的信息。 例如: 匹配 {2020}年{04}月{01}日,我们的需求是匹配到大括号中的数字 。 如果使用match,我们匹配的是["{2020}", "{04}", "{01}"]
。
let str="{2020}年{04}月{01}日";
let reg=/\{(\d+)\}/g;
str.match(reg)
//["{2020}", "{04}", "{01}"]
let str="{2020}年{04}月{01}日";
let reg=/\{(\d+)\}/g;
let arg=[],
result=[],
res=reg.exec(str);
while(res){
let [first,value]=res;
arg.push(first);
result.push(value);
res=reg.exec(str);
}
console.log(arg,result);
//["{2020}", "{04}", "{01}"] ["2020", "04", "01"]
let str = "{2020}年{04}月{01}日";
let reg =/\{(\d+)\}/g;
console.log(reg.test(str))
console.log(RegExp.$1)
//2020
console.log(reg.test(str))
console.log(RegExp.$1)
//04
?
来实现。
let str="book23look90";
let reg=/\d+/g;
str.match(reg);
//["23", "90"]
reg=/\d+?/g;
//["2", "3", "9", "0"]
//简单用法
let str = "we are family";
str.replace(/e/g,'o')
//"wo aro family"
let str = "2020-04-01"
let reg =/^(\d{4})-(\d{1,2})-(\d{1,2})$/;
str.replace(reg, "$1年$2月$3日");
//2020年04月01日"
str.replace(reg,(_,...arg)=>{
//_是匹配到的字符串,但需求是要分组内的元素
let [y,m,d]=arg;
return y+'年'+m+'月'+d+'日'
});
//2020年02月02日"
let str = "we are family"
let reg =/\b([a-zA-Z])[a-zA-Z]*/g;
str.replace(reg,(...arg)=>{
//_是匹配到的字符串,但需求是要分组内的元素
let [content,res]=arg;
res=res.toUpperCase();
content=content.substring(1);
return res+content
});
//"We Are Family"
分组引用
小括号在正则中有三个作用:改变优先级
分组捕获
分组引用
分组引用就是通过()\1来实现一摸一样的字符。需要注意的一点是它不能用来捕获。
let str="book";
let reg=/^[a-zA-Z]([a-zA-Z])\1[a-zA-Z]$/;
reg.test(str);
//true
reg=/^(\d{4})(-\d{1,2})\1$/
reg.test("2020-02-02")
//false
reg=/^\d{4}(-\d{1,2})\1$/
reg.test("2020-02-02")
//true
问号的相关作用
问号在正则中的作用比较多:问号左边是非量词元字符,代表0~1次
问号左边是量词元字符:取消贪婪性
(?:) 只匹配不捕获
(?=) 正向预查
(?!) 负向预查
(?...) 设置别名
//设置别名
let reg =/^(?<con>\d{2,3})$/;
let str = "23"
str = str.replace(reg, "1$4")
//1234
//正向前瞻
str="we are family";
reg=/a(?=m)/gi
str=str.replace(reg,"sss$&")
//"we are fsssamily"
//正向后瞻
str="we are family";
reg=/(?<=m)/gi
str=str.replace(reg,"sss$&")
//"we are famsssily"
//负向前瞻
str="we are family";
reg=/a(?!m)/gi
str=str.replace(reg,"sss$&")
//"we sssare family"
//负向后瞻
str="we are family";
reg=/f(?a)/gi
str=str.replace(reg,"sss$&")
//"we are sssfamily"
场景
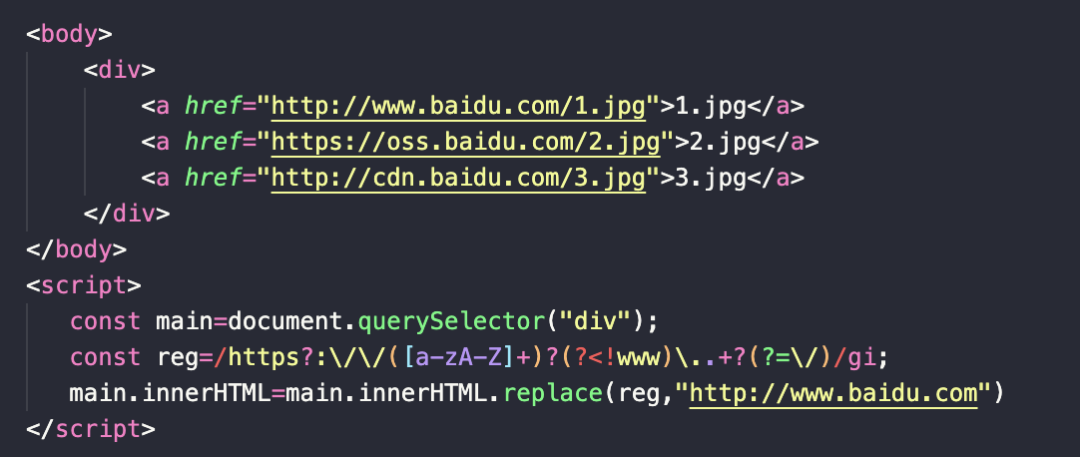
正则在各种场景的应用: 给文字加链接<div>我要去百度div>
let dom=document.querySelector('div');
dom.innerHTML= dom.innerHTML.replace(
/百度/,
`$&`)
let str="白菜:3元 ;苹果:5.6元;香蕉:3元";
let reg=/(\d)(.\d)?(?=元)/gi;
str=str.replace(reg,(_,...arg)=>{
arg[0]=arg[1]?(arg[0]+arg[1]):(arg[0]+'.0');
return arg.splice(0,1).join('')
})
//"白菜:3.0元 ;苹果:5.6元;香蕉:3.0元"
let str="99999999999.02";
str.replace(/\d{1,3}(?=(\d{3})+(\.\d{1,2})?$)/g, '$&,');
//"99,999,999,999.02"
替换域名

最后我们用正则实现一个常见的面试题:字符串中出现字符最多的字符是什么,出现了多少次?
如果不使用正则,我们的思路可能是使用hash来实现,如果使用正则,我们可以这样:
let str = "wesdsrwrfdfdcsdsfdjfurwfunshbchfgys";
const getMax = str => {
if (!str) return 0;
str = [...str].sort((a, b) => a.localeCompare(b)).join('');
let reg =/([a-zA-Z])\1+/g;
let ary = str.match(reg);
ary.sort((a, b) => b.length - a.length);
let arr = [ary[0][0]],
maxLen = ary[0].length,
i = 1;
while (i < ary.length) {
if (ary[i].length !== maxLen) {
break;
}
arr.push(ary[i][0]);
i++
}
return {
res: arr.join(','),
maxLen,
}
}
getMax(str)
//{res: "f,s", maxLen: 6}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









