





作者:蓬蒿
2013 - 2016: 杭州某信息安全院安全研发部负责人,承担Web网站安全监测服务平台( Web 漏洞、敏感词、挂马、暗链等)的架构、设计与实现,熟悉常见 Web 漏洞的基本原理与渗透方式。2016 - Present: 中国互联网某最大财税平台的架构师,负责安全中台、业务风控(规则引擎)、API Gateway 、配置中心、分布式链路追踪日志系统等架构与研发,熟悉常见 Dubbo 、HSF、Spring Cloud 等分布式服务架构设计与与实现。Blog: http://www.geek-make.com
原文链接:https://gitbook.cn/gitchat/activity/5f79e597dc0d2e0f38b4526e
由于 Java 程序会通过编译成 ByteCode,同样的 ByteCode 使用不同的 JVM 参数运行,尤其运行在高并发系统上表现就会有巨大的差异。为使应用能够获得最优性能,因此需要根据实际业务情况选择合适的 JVM 参数运行 Java 应用程序。
在本场 Chat 中,会讲到如下内容:
Java 内存模型
与内存相关的 JVM 参数
JVM 各个版本常见的垃圾回收器
JVM 参数调优案例
Java 内存模型
Java 内存模型是 Java 应用运行的内存基础。根据《Java 虚拟机规范》规定,Java 内存模型的基本结构如下:
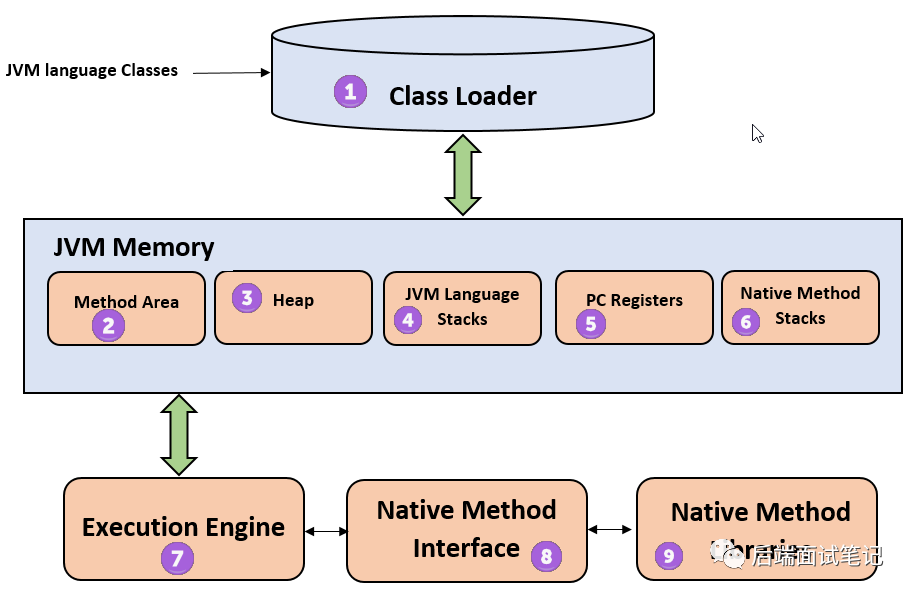
Java 的内存分栈内存、堆内存、本地方法栈(native)、方法区、PC 寄存器,JVM 通过类加载器加载 class 文件内容到内存,类、常量、方法会放到内存中。
类加载器 ClassLoader
JVM 启动时或者在类运行时将需要的 class 加载到 JVM 中,类在加载过程中抓哟包含:加载、连接、初始化等过程。
方法区 Method Area
方法区存放要加载的类 or 接口的信息(名称、修饰符等)、类的 static 变量、final 常量、Field 信息、方法(元数据)信息。
堆内存 Heap
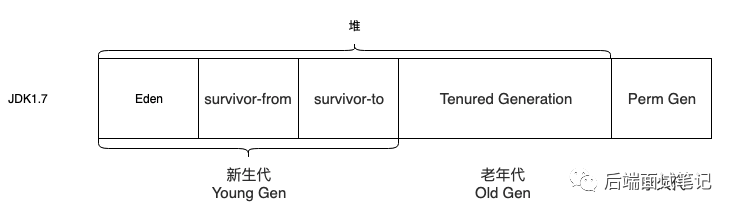
Java 中的堆是 JVM 所管理的最大的一块内存空间,用于存放各种类的实例对象以及关联的实例变量、数组等,并且 Java 堆内存对所有的线程都是共享的。在 Java 中,堆被划分成两个不同的区域:新生代(Young Generation)、老年代(Old Generation)。新生代又被划分为三个区域:Eden、From Survivor、To Survivor。这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
栈内存 JVM language Stacks
Java 栈内存存储局部变量和部分结果。每个线程都有自己的 JVM 堆栈,创建线程时的同时栈内存也会被创建。每当调用方法时,都会创建一个新的栈帧,并在方法调用过程后删除该栈帧。
PC 寄存器 PC Registers
PC 寄存器存储当前正在执行的 Java 虚拟机指令的地址。在 Java 中,每个线程都有自己单独的 PC 寄存器。
本地方法栈 Native Method Stacks
本机方法栈保存本机代码的指令,该指令依赖于本机库,它是用另一种非 Java 语言编写的。
内存相关的 JVM 参数
| GC 算法 | JVM 参数 |
|---|---|
| 公用参数 | 50 |
| Parallel | 6 |
| CMS | 72 |
| G1 | 26 |
| ZGC | 8 |
JVM 大约有 50 个通用的适合所有所有 GC 算法的参数,除了这 50 个参数之外,仅对于 CMS,您还可以传递 72 个额外的参数。如上表所示,此参数比其他任何 GC 算法都要多得多。因此,可想而知,JDK 团队支持所有这些参数所需的编码复杂性。
JVM 垃圾回收器
各个版本 Java 对应的 GC
Java 在 JDK 10 之前提供了四种不同类型的垃圾回收器(Garbage Collector),分别是:
Serial Garbage Collector - S GC
Parallel Garbage Collector - P GC
CMS Garbage Collector - CMS GC
G1 Garbage Collector - G1 GC
2018 年 9 月 Oracle 发布了稳定 release 版本的 JDK 11。JDK 11 众多新增的特性就包括增加了 ZGC 垃圾收集器,ZGC 是一种可伸缩的低延迟垃圾收集器。如果想了解更多 ZGC 的细节,可以访问以下链接:
http://openjdk.java.net/jeps/333
https://www.opsian.com/blog/javas-new-zgc-is-very-exciting/
JDK 11 发布了 ZGC 垃圾收集器后,JDK 12 也马不停蹄地带来了 Shenandoah GC:
https://blog.idrsolutions.com/2019/03/changes-to-garbage-collection-in-java-12/
| Java | Default GC | Supported GC |
|---|---|---|
| Java7(2011/07/28) | PGC | SGC、PGC、CMS |
| Java8(2014/03/18) | PGC | SGC、PGC、CMS、G1 |
| Java9(2017/09/21) | G1GC | SGC、PGC、G1 |
| Java10(2018/03/20) | G1GC | SGC、PGC、G1 |
| Java11(2018/09/25) | G1GC | SGC、PGC、G1、ZGC |
| Java12(2019/03/19) | G1GC | SGC、PGC、G1、ZGC、Shenandoah GC |
| Java13(2019/09/17) | G1GC | SGC、PGC、G1、ZGC、Shenandoah GC |
| Java14(2020/03/17) | G1GC | SGC、PGC、G1、ZGC、Shenandoah GC |
| Java15(2020/09/15) | G1GC | SGC、PGC、G1、ZGC、Shenandoah GC |
从 Java 9 开始,JVM 的默认垃圾回收器就从 Parallel GC 调整为 G1,并且开始全面废除 CMS,参见 JEP248:
http://openjdk.java.net/jeps/248
Limiting GC pause times is, in general, more important than maximizing throughput. Switching to a low-pause collector such as G1 should provide a better overall experience, for most users, than a throughput-oriented collector such as the Parallel GC, which is currently the default.
Many performance improvements were made to G1 in JDK 8 and its update releases, and further improvements are planned for JDK 9. The introduction of concurrent class unloading (JEP 156) in JDK 8u40 made G1 a fully-featured garbage collector, ready to be the default.
限制或者减少 GC 停顿时间相比系统吞吐量而言更加重要,从 PGC 切换至低延迟的 G1 能够为大部分用户带来更好的体验。G1 的性能在 JDK 8 以及后续的 release 版本都得到了极大的优化,G1 是一个具备所有 GC 特性的垃圾回收器,因此将 G1 设置为 JVM 默认的 GC。
根据 JEP-291 中的说明,为了减轻 GC 代码的维护负担以及加速新功能开发,决定在 JDK 9 中废弃 CMS GC。
从 Java 9 开始,如果您使用 -XX:+UseConcMarkSweepGC(激活 CMS GC 算法的参数)参数启动应用程序,则会在下面显示警告消息:
Java HotSpot(TM) 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
如果你想知道当前应用对应的 JVM 版本,你可以使用以下命令进行查询:
$ java -XX:+PrintCommandLineFlags -version

如果你想根据自己需要设置对应类型的 GC,你可以使用如下命令:
$ java -XX:+UseG1GC -XX:+PrintCommandLineFlags -version
Serial GC
Serial GC 传行垃圾回收器在 Java 语言的发展历程中,可以算是一种老古董了。虽然,JDK 11 推出的 ZGC,JDK 12 推出的 Shenandoah GC,应用已经无限接近于 zero STW pause time,但并不影响通过已经过时的 GC 学习垃圾回收器知识。
Serial GC 是一个 CPU 或者一个线程去完成垃圾回收,必须暂停其他所有的工作线程,直到垃圾回收结束。“Stop The World”有 JVM 在后台自动发起和自动完成。
Serial GC 通过参数 -XX:+UseSerialGC 启动,其中新生代 Young gc 采用 Serial GC,老年代 Full GC 采用 Serial Old GC。Serial Old GC 采用的是标记—整理算法,二者在工作时都是串行的。

ParNew 是一个工作在新生代的 GC,它是 Serial GC 的多线程版本,使用 -XX:+UseParNewGC 参数来启用 ParNew 和 Serial Old 收集器组合进行垃圾收集,也可以使用 -XX:ParallelGCThreads=N 参数设置工作时的线程数。与 Serial GC 相比,ParNew 使用多线程的目的就是缩短 GC time,降低用户卡顿的体感。

Parallel GC
Parallel Scavenge 是并行的多线程新生代收集器,使用“复制”算法进行 GC。Parallel Old 收集器是 Parallel Scavenge 的老年代版本,一般选择搭配使用。PGC 的优势是它的 STW 停顿时间短,GC 效率高,具有较高的吞吐量。
Parallel Scavenge 和 Parallel Old 在 GC 时都是由多个 GC 线程并行执行,并暂停一切用户线程,使用“标记—整理”GC 算法。
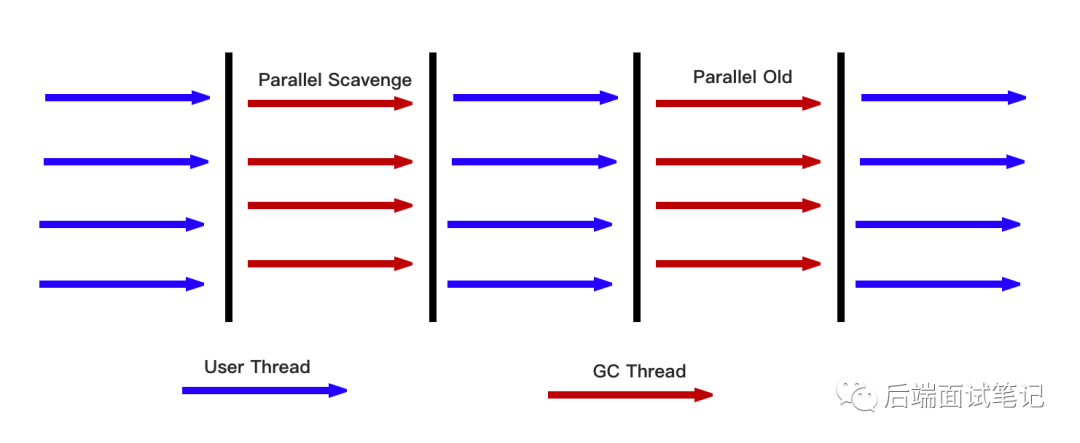
GC 可配置的线程数量可以进行配置:
$ -XX:ParallelGCThreads=N
GC 最大的 pause time 可以按如下配置:
$ XX:MaxGCPauseMillis=N
CMS GC
Java 专家设计并实现 CMS(Concurrent Mark Sweep)垃圾回收器的目标是为了实现最短回收 STW 时间。从名字(Mark Sweep)可以看出,CMS 收集器就是“标记—清除”算法实现的。CMS 分为六个步骤:
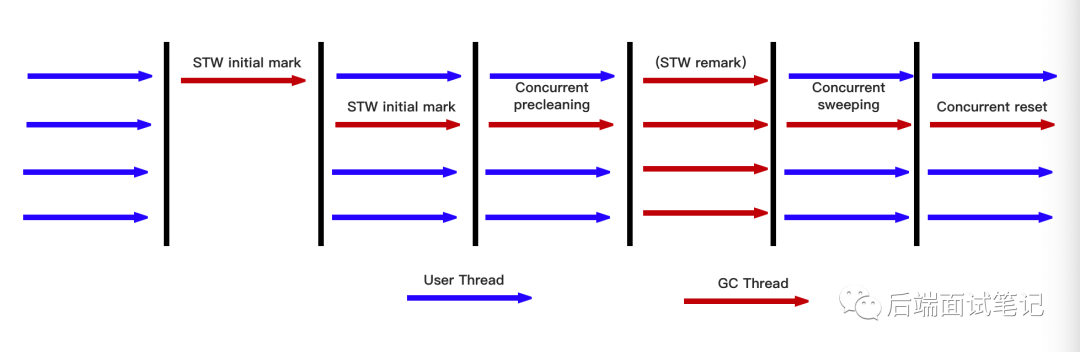
初始标记(STW initial mark):这个阶段 JVM 需要停顿(STW)正在执行的任务。从 GC 的根对戏那个开始,只扫描到能够和“根对象”直接关联的对象,并作标记。虽然这个过程发生了 STW,但是 pause time 非常短,用户几乎是无感的。
并发标记(Concurrent marking):在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,用户不会感受到停顿。
并发预清理(Concurrent precleaning):JVM 查找在执行上个阶段“并发标记阶段”新进入老年代的对象(可能会有一些对象从新生代晋升到老年代,或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段“重新标记”的工作,因为下一个阶段会 STW。
重新标记(STW remark):这个阶段 JVM 也需要 STW,收集器线程扫描在 CMS 堆中剩余的对象。扫描从“跟对象”开始向下追溯,并处理对象关联。
并发清理(Concurrent sweeping):GC 线程和 User 线程并发清理垃圾对象。
并发重置(Concurrent reset):重置 CMS 收集器的数据结构,等待下一次 GC。
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。在启动 JVM 参数加上 -XX:+UseConcMarkSweepGC,这个参数表示对于老年代的回收采用 CMS。
G1 GC
G1(Garbage-First)垃圾回收器(简称 G1 GC)是 JDK 7 中 Java HotSpot JVM 新引入的垃圾回收器。设计 G1 GC 长期的目标是用于替代 HotSpot 低延迟的并行 CMS 垃圾回收器。
G1 GC 专门用于以下业务场景:
Can operate concurrently with applications threads like the CMS collector.
Compact free space without lengthy GC induced pause times.
Need more predictable GC pause durations.
Do not want to sacrifice a lot of throughput performance.
Do not require a much larger Java heap.
和其它 HotSpot GC 相比,G1 采用了一个非常不同的堆栈内存结构,在 G1 中,年轻代和年老代之间没有物理隔离,它们是一个连续的堆栈。年轻代和年老代被分成大小一样的区域(Region),年轻代可能是一套非连续的区域,年老代也一样,这就允许 G1 在年轻代和年老代之间灵活地移动资源。
我们可以使用以下参数启动 G1 GC:
$ -XX:+UseG1GC
传统的 HotSpot CMS 将堆内存结构划分为三个固定部分:Young Generation、Old Generation、Permanent Generation。

G1 却采用了一个完全不同的堆栈内存结构:
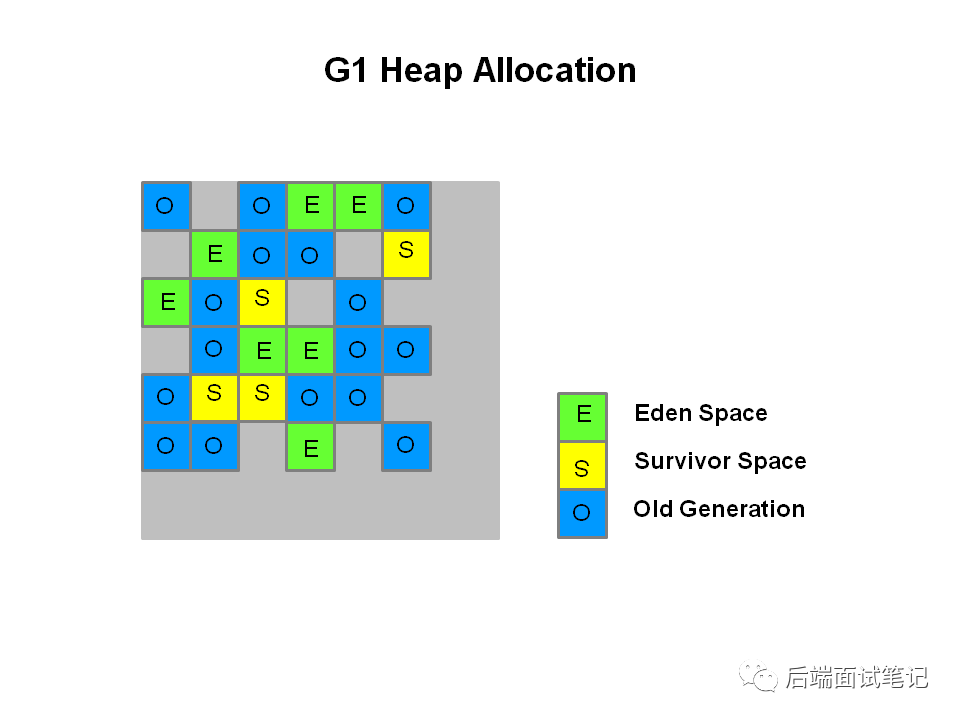
G1 中 Heap 内存被划分成一块块大小相等的 Region,这些 Region 在逻辑上是连续的。每块 Region 都会被打唯一的分代标志(Eden、Survivor、Old)。在逻辑上,Eden Regions 构成 Eden 空间,Survivor Regions 构成 Survivor 空间,Old Regions 构成了 old 空间。
G1 中每个 Region 大小是固定相等的,Region 的大小可以通过参数 -XX:G1HeapRegionSize 设定,取值范围从 1M 到 32M,且是 2 的指数。如果不设定,那么 G1 会根据 Heap 大小自动决定。
JDK 8 中 Region 划分的源码如下:
//允许的最小的 REGION_SIZE,即 1M,不可能比 1M 还小;
#define MIN_REGION_SIZE ( 1024 * 1024 )
// 允许的最大的 REGION_SIZE,即 32M,不可能比 32M 更大;限制最大 REGION_SIZE 是为了考虑 GC 时的清理效果;
#define MAX_REGION_SIZE ( 32 * 1024 * 1024 )
// JVM 对堆期望划分的 REGION 数量
#define TARGET_REGION_NUMBER 2048
size_t HeapRegion::max_region_size() {
return (size_t)MAX_REGION_SIZE;
}
// 这个方法是计算 region 的核心实现
void HeapRegion::setup_heap_region_size(size_t initial_heap_size, size_t max_heap_size) {
uintx region_size = G1HeapRegionSize;
// 是否设置了 G1HeapRegionSize 参数,如果没有配置,那么按照下面的方法计算;如果设置了 G1HeapRegionSize 就按照设置的值计算
if (FLAG_IS_DEFAULT(G1HeapRegionSize)) {
// average_heap_size 即平均堆的大小,(初始化堆的大小即 Xms+最大堆的大小即 Xmx)/2
size_t average_heap_size = (initial_heap_size + max_heap_size) / 2;
// average_heap_size 除以期望的 REGION 数量得到每个 REGION 的 SIZE,与 MIN_REGION_SIZE 取两者中的更大值就是实际的 REGION_SIZE;从这个计算公式可知,默认情况下如果 JVM 堆在 2G(TARGET_REGION_NUMBER*MIN_REGION_SIZE)以下,那么每个 REGION_SIZE 都是 1M;
region_size = MAX2(average_heap_size / TARGET_REGION_NUMBER, (uintx) MIN_REGION_SIZE);
}
// region_size 的对数值
int region_size_log = log2_long((jlong) region_size);
// 重新计算 region_size,确保它是最大的小于或等于 region_size 的 2 的 N 次方的数值,例如重新计算前 region_size=33,那么重新计算后 region_size=32;重新计算前 region_size=16,那么重新计算后 region_size=16;
// Recalculate the region size to make sure it's a power of
// 2. This means that region_size is the largest power of 2 that's
// <= what we've calculated so far.
region_size = ((uintx)1 << region_size_log);
// 确保计算出来的 region_size 不能比 MIN_REGION_SIZE 更小,也不能比 MAX_REGION_SIZE 更大
// Now make sure that we don't go over or under our limits.
if (region_size < MIN_REGION_SIZE) {
region_size = MIN_REGION_SIZE;
} else if (region_size > MAX_REGION_SIZE) {
region_size = MAX_REGION_SIZE;
}
// 与 MIN_REGION_SIZE 和 MAX_REGION_SIZE 比较后,再次重新计算 region_size
// And recalculate the log.
region_size_log = log2_long((jlong) region_size);
... ...
}
G1 保留了 YGC 并加上了一种全新的 MIXGC 用于收集老年代。G1 中没有 Full GC,G1 中的 Full GC 是采用 Serial Old Full GC。
YGC
当 Eden 空间被占满之后,就会触发 YGC。在 G1 中 YGC 依然采用复制存活对象到 Survivor 空间的方式,当对象的存活年龄满足晋升条件时,把对象提升到 Old Generation Regions(老年代)。
G1 控制 YGC 开销的手段是动态改变 Young Region 的个数,YGC 的过程中依然会 STW(stop the world 应用停顿),并采用多线程并发复制对象,减少 GC 停顿时间。

MIXGC
G1 保留了 YGC 并加上了一种全新的 MIXGC 用于收集老年代。G1 中没有 Full GC,G1 中的 Full GC 是采用 Serial Old Full GC。
G1 中的 MIXGC 选定所有新生代里的 Region,外加根据 Global Concurrent Marking 统计得出收集收益高的若干老年代 Region,在用户指定的开销目标范围内尽可能选择收益高的老年代 Region 进行回收。所以 MIXGC 回收的内存区域是新生代 + 老年代。
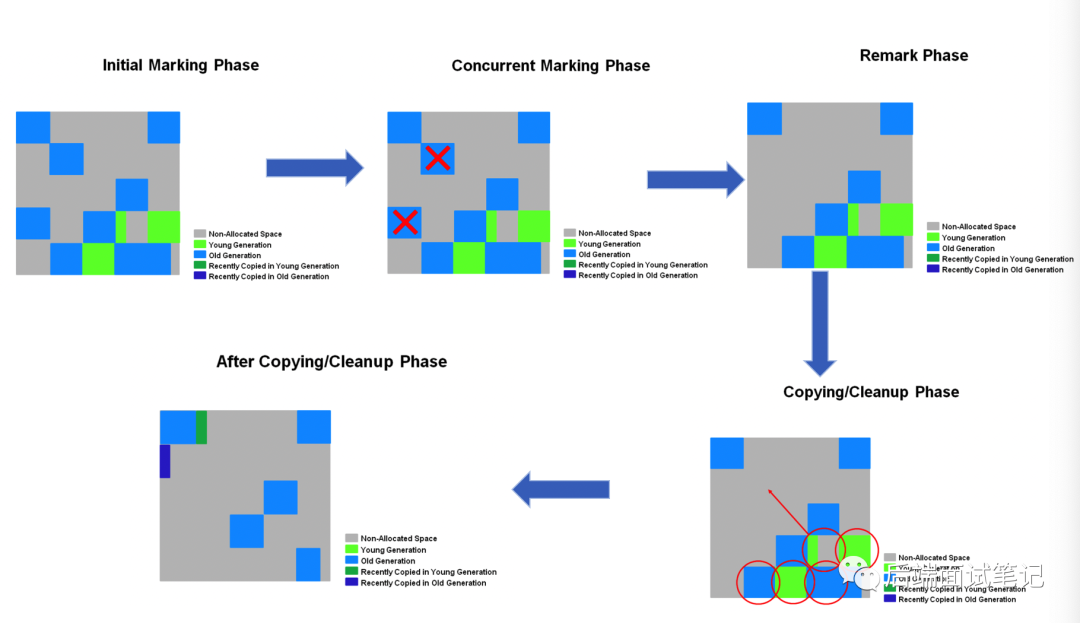
全局并发标记
Global Concurrent Marking 分为五个阶段
Nitial Mark 初始标记 STW
Root Region Scanning 根区域扫描
Concurrent Marking 并发标记
Remark 最终标记 STW
Cleanup 清除 STW AND Concurrent
JVM 参数调优案例
案例
环境:Tomcat 8 + JDK 7
GC 算法:CMS
最近一段时间,经常收到 GC 告警(大于 3 秒的长 GC 告警)邮件消息。
2020-10-10T15:38:01.216+0800: 1967385.551: [GC (Allocation Failure) 2020-10-10T15:38:01.216+0800: 1967385.552: [ParNew: 1120980K->1918K(1258304K), 0.0144511 secs] 2518802K->1400131K(4054528K), 0.0147703 secs] [Times: user=0.04 sys=0.01, real=0.02 secs]
2020-10-10T15:38:01.233+0800: 1967385.568: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1398213K(2796224K)] 1402257K(4054528K), 0.0128933 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
2020-10-10T15:38:01.246+0800: 1967385.581: [CMS-concurrent-mark-start]
2020-10-10T15:38:01.421+0800: 1967385.756: [CMS-concurrent-mark: 0.175/0.175 secs] [Times: user=0.24 sys=0.03, real=0.18 secs]
2020-10-10T15:38:01.421+0800: 1967385.757: [CMS-concurrent-preclean-start]
2020-10-10T15:38:01.429+0800: 1967385.764: [CMS-concurrent-preclean: 0.007/0.007 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2020-10-10T15:38:01.429+0800: 1967385.764: [CMS-concurrent-abortable-preclean-start]
2020-10-10T15:38:06.222+0800: 1967390.557: [CMS-concurrent-abortable-preclean: 1.787/4.793 secs] [Times: user=3.32 sys=0.27, real=4.80 secs]
2020-10-10T15:38:06.224+0800: 1967390.559: [GC (CMS Final Remark) [YG occupancy: 564683 K (1258304 K)]2020-10-10T15:38:06.224+0800: 1967390.559: [Rescan (parallel) , 0.0894104 secs]2020-10-10T15:38:06.314+0800: 1967390.649: [weak refs processing, 0.0767754 secs]2020-10-10T15:38:06.390+0800: 1967390.726: [class unloading, 0.0527649 secs]2020-10-10T15:38:06.443+0800: 1967390.778: [scrub symbol table, 0.0158940 secs]2020-10-10T15:38:06.459+0800: 1967390.794: [scrub string table, 0.0020345 secs][1 CMS-remark: 1398213K(2796224K)] 1962897K(4054528K), 0.2655631 secs] [Times: user=0.53 sys=0.00, real=0.27 secs]
2020-10-10T15:38:06.490+0800: 1967390.825: [CMS-concurrent-sweep-start]
2020-10-10T15:38:06.803+0800: 1967391.138: [CMS-concurrent-sweep: 0.289/0.313 secs] [Times: user=0.55 sys=0.03, real=0.31 secs]
2020-10-10T15:38:06.803+0800: 1967391.138: [CMS-concurrent-reset-start]
2020-10-10T15:38:06.828+0800: 1967391.163: [CMS-concurrent-reset: 0.025/0.025 secs] [Times: user=0.01 sys=0.03, real=0.02 secs]
2020-10-10T15:38:11.544+0800: 1967395.880: [GC (Allocation Failure) 2020-10-10T15:38:11.545+0800: 1967395.880: [ParNew: 1120446K->2592K(1258304K), 0.0132710 secs] 1533842K->415996K(4054528K), 0.0135585 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
我们先观察下 GC 日志,观察长时间的 GC 到底发生了什么,长时间的 GC 发生在 CMS 的 concurrent-abortable-preclean 并发可中止的预清理阶段。

第一个箭头显示 abortable-preclean 阶段耗时 4.80 秒。第二个箭头显示的是 remark 阶段,耗时 0.28 秒。
concurrent-abortable-preclean 阶段用户线程和 gc 线程是并发的,虽然不优化也没有什么问题,但是经常看到邮件报警非常不爽。优化的目的是降低 concurrent-abortable-preclean 的 GC 时间,并且也可以降低 remark 的耗时。
调优过程如下。
步骤一:CMSMaxAbortablePrecleanTime=5000 和 CMSScheduleRemarkEdenPenetration=50,-XX:CMSMaxAbortablePrecleanTime 它的默认值是 5000ms,作用是设置 abortable-preclean 阶段所需的时间;-XX:CMSScheduleRemarkEdenPenetration 默认值是 50%,表示 eden space 超过 50% 则进入 remark STW 阶段。调整这两个参数:
-XX:CMSMaxAbortablePrecleanTime=1000
-XX:CMSScheduleRemarkEdenPenetration=10
步骤二:-XX:+CMSScavengeBeforeRemark 在 remark 阶段之前对年轻代对象进行一次 Minor GC,这样年轻代的对象数量相比 GC 之前下降很多,生育被当作“GC Roots”对象数量就会减少,因此 remark 的工作量会少很多,remark 的耗时也会减少。当然 remark 耗时减少和 Minor GC 的时间需要做一个 trade-off,根据实际情况来确定是否开启 CMSScavengeBeforeRemark:
-XX:+CMSScavengeBeforeRemark
经过以上参数的调整,abortable-preclean 阶段耗时下降至 860ms。第二个箭头显示的是 remark 阶段,耗时 100ms,达到优化目标。
abortable_preclean 阶段 JDK C++ 源码片段:
// Try and schedule the remark such that young gen
// occupancy is CMSScheduleRemarkEdenPenetration %.
void CMSCollector::abortable_preclean() {
if (get_eden_used() > CMSScheduleRemarkEdenSizeThreshold) {
// One, admittedly dumb, strategy is to give up
// after a certain number of abortable precleaning loops
// or after a certain maximum time. We want to make
// this smarter in the next iteration.
// XXX FIX ME!!! YSR
size_t loops = 0, workdone = 0, cumworkdone = 0, waited = 0;
//should_abort_preclean 会检查上面说的_abort_preclean 是否为 true
while (!(should_abort_preclean() ||
ConcurrentMarkSweepThread::should_terminate())) {
workdone = preclean_work(CMSPrecleanRefLists2, CMSPrecleanSurvivors2);
cumworkdone += workdone;
loops++;
// 主动停止执行
if ((CMSMaxAbortablePrecleanLoops != 0) &&
loops >= CMSMaxAbortablePrecleanLoops) {
if (PrintGCDetails) {
gclog_or_tty->print(" CMS: abort preclean due to loops ");
}
break;
}
if (pa.wallclock_millis() > CMSMaxAbortablePrecleanTime) {
if (PrintGCDetails) {
gclog_or_tty->print(" CMS: abort preclean due to time ");
}
break;
}
if (workdone < CMSAbortablePrecleanMinWorkPerIteration) {
// Sleep for some time, waiting for work to accumulate
stopTimer();
cmsThread()->wait_on_cms_lock(CMSAbortablePrecleanWaitMillis);
startTimer();
waited++;
}
}
if (PrintCMSStatistics > 0) {
gclog_or_tty->print(" [%d iterations, %d waits, %d cards)] ",
loops, waited, cumworkdone);
}
}
return;
}














 2774
2774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









