







-
散列表(Hash table,也叫哈希表),是根据 关键码值(Key value) 而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数H(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数H(key)为哈希(Hash) 函数。
即地址index=H(key)(参考百度百科) -
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
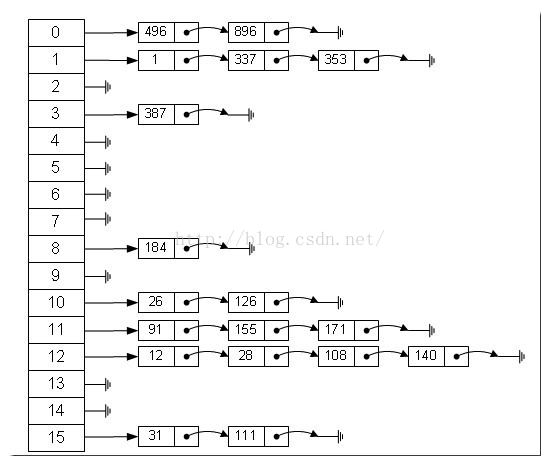
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可 以理解为“链表的数组”,如图:对key值做某种算法再对表长度取余,放在对应的链表后面。
(参考:https://blog.csdn.net/duan19920101/article/details/51579136) -
哈希函数的构造方法有多种,直接定制法、数字分析法、平方取中法、折叠法、除留余数法(常用)等,不展开说明了。
-
哈希表的应用:
- 安全加密;
- 查找:哈希表查找效率极高。故在海量数据处理中有很大作用;
-
C++ STL中的哈希表hash_map
- 原理:
C++11 中加入了<unordered_map>容器,就提供key-value的存储和查找功能。 其原理大概如下介绍:采用分散的桶结构,首先分配一大片内存,形成许多桶,桶节点保存一个单链表。利用hash函数,对key进行映射到不同区域(桶)进行保存。
unordered_map的效率优于hash_map,更优于map;而空间复杂度方面,hash_map最低,unordered_map次之,map最大。并且hash_map不在标准库中,所以学习unordered_map。
插入过程:
得到key
通过hash函数得到hash值
得到桶号(一般都为hash值对桶数求模)
存放key和value在桶内。
取值过程:
得到key
通过hash函数得到hash值
得到桶号(一般都为hash值对桶数求模)
比较桶的内部元素是否与key相等,若都不相等,则没有找到。
取出相等的记录的value。 - unordered_map的使用
#include <unordered_map> #include <string> #include <iostream> using namespace std; int _tmain(int argc, _TCHAR - 原理:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1080
1080
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









