





EXPLAIN作为MySQL的性能分析神器,读懂其结果是很有必要的,然而我在各种搜索引擎上竟然找不到特别完整的解读。都是只有重点,没有细节(例如type的取值不全、Extra缺乏完整的介绍等)。
所以,我肝了将近一个星期,整理了一下。这应该是全网最全面、最细致的EXPLAIN解读文章了,下面是全文。
EXPLAIN使用
本文基于MySQL 8.0编写,理论支持MySQL 5.0及更高版本。
explain可用来分析SQL的执行计划。格式如下:
{EXPLAIN | DESCRIBE | DESC} tbl_name [col_name | wild]{EXPLAIN | DESCRIBE | DESC} [explain_type] {explainable_stmt | FOR CONNECTION connection_id}{EXPLAIN | DESCRIBE | DESC} ANALYZE select_statement explain_type: { FORMAT = format_name}format_name: { TRADITIONAL | JSON | TREE}explainable_stmt: { SELECT statement | TABLE statement | DELETE statement | INSERT statement | REPLACE statement | UPDATE statement}示例:
EXPLAIN format = TRADITIONAL json SELECT tt.TicketNumber, tt.TimeIn, tt.ProjectReference, tt.EstimatedShipDate, tt.ActualShipDate, tt.ClientID, tt.ServiceCodes, tt.RepetitiveID, tt.CurrentProcess, tt.CurrentDPPerson, tt.RecordVolume, tt.DPPrinted, et.COUNTRY, et_1.COUNTRY, do.CUSTNAME FROM tt, et, et AS et_1, do WHERE tt.SubmitTime IS NULL AND tt.ActualPC = et.EMPLOYID AND tt.AssignedPC = et_1.EMPLOYID AND tt.ClientID = do.CUSTNMBR;结果输出展示:
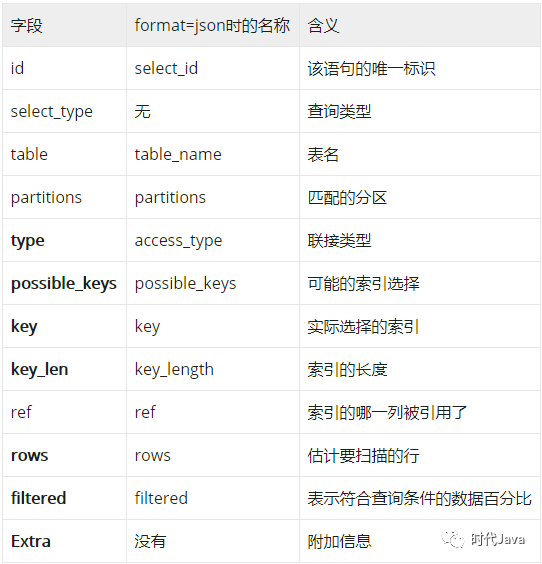
结果解读
id
该语句的唯一标识。如果explain的结果包括多个id值,则数字越大越先执行;而对于相同id的行,则表示从上往下依次执行。
select_type
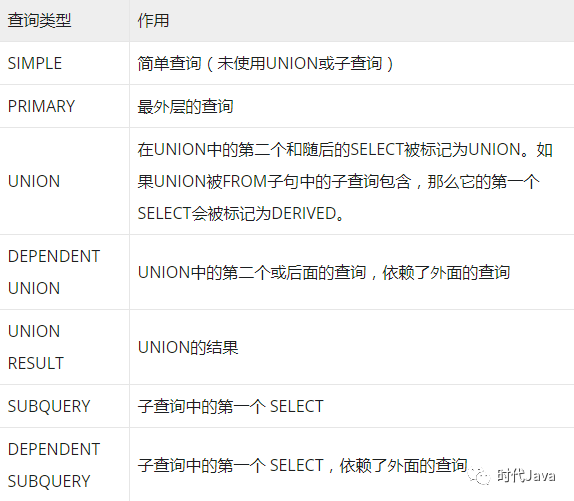
查询类型,有如下几种取值:

table
表示当前这一行正在访问哪张表,如果SQL定义了别名,则展示表的别名
partitions
当前查询匹配记录的分区。对于未分区的表,返回null
type
连接类型,有如下几种取值,性能从好到坏排序 如下:
system:该表只有一行(相当于系统表),system是const类型的特例
const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
eq_ref:当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,性能仅次于system及const。
-- 多表关联查询,单行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;-- 多表关联查询,联合索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;ref:当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。如果使用的索引只会匹配到少量的行,性能也是不错的。
-- 根据索引(非主键,非唯一索引),匹配到多行SELECT * FROM ref_table WHERE key_column=expr;-- 多表关联查询,单个索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;-- 多表关联查询,联合索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;TIPS
最左前缀原则,指的是索引按照最左优先的方式匹配索引。比如创建了一个组合索引(column1, column2, column3),那么,如果查询条件是:
WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 都可以使用该索引;
WHERE column1 = 2、WHERE column1 = 1 AND column3 = 3就无法匹配该索引。
fulltext:全文索引
ref_or_null:该类型类似于ref,但是MySQL会额外搜索哪些行包含了NULL。这种类型常见于解析子查询
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;index_merge:此类型表示使用了索引合并优化,表示一个查询里面用到了多个索引
unique_subquery:该类型和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引。例如:
value IN (SELECT primary_key FROM single_table WHERE some_expr)index_subquery:和unique_subquery类似,只是子查询使用的是非唯一索引
value IN (SELECT key_column FROM single_table WHERE some_expr)range:范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有BETWEEN子句或WHERE子句里有>、>=、、BETWEEN、LIKE、IN()等操作符。
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;SELECT * FROM tbl_name WHERE key_column IN (10,20,30)index:全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
ALL:全表扫描,性能最差。
--
知识分享,时代前行!
~~ 时代Java
还有更多好文章……
请查看历史文章和官网,
↓有分享,有收获~














 9507
9507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









