






日前,参加了蚂蚁数据研发专家的面试,被问到了一个非常细节的问题,即Python中list的排序问题,场景如下:有一个学生成绩表,学生成绩以json方式存储,包括学生学号、姓名、成绩、班级等信息,学生成绩表以list方式存储。
#创建一个学生成绩表list,存储学生成绩,包括学生学号、姓名、成绩、班级import pandas as pdlist_ex = [ {'id':2,'name':'张三','score':96,'class':'三班'}, {'id':1,'name':'李四','score':96,'class':'四班'}, {'id':3,'name':'王五','score':95,'class':'四班'}, {'id':4,'name':'赵六','score':100,'class':'五班'}, {'id':5,'name':'田七','score':90,'class':'六班'}]print(type(list_ex))list_ex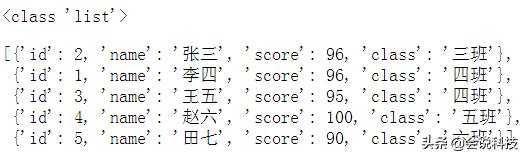
学生成绩表
那么,如何按照不同的信息对学生成绩表list进行排序呢?
想了下,有两种方法可以做,一种是直接用list的sort函数,一种是将list转换为dataframe,然后使用dataframe的sort_values函数。
list:sort()
列表list自带sort函数,有key和reverse两个参数,其中key参数是callback类型,即需要传入一个函数,可以是def显示定义的函数,也可以是lambda表达式。
#按成绩score排列,key中传入lambda表达式list_ex.sort(key=lambda x:x['score'])list_ex
按成绩升序
从上面的结果可以看出sort默认是升序排列的,sort函数的reverse参数可以控制排序方向,默认为False升序,reverse=True意味着降序。
#使用reverse控制排序方向list_ex.sort(key=lambda x:x['score'],reverse=True)list_ex
降序排列
这样就实现了成绩的降序排列,分数越高的排名越靠前。
在上面排序中,张三和李四都是96分,张三排在李四前面,因为原始成绩表中张三排在李四前面。然而,在实际业务中应该是学号小的排在前面,因此需要按照成绩、学号共同排序,使得成绩降序、学号升序。
sort函数的key参数也是一个函数,其中也可以传入多个参数,从而实现多维度的排序。
#key中传入sore和id两个参数,实现多维度排序list_ex.sort(key=lambda x:(x['score'],x['id']),reverse=True)list_ex
实现对两个字段的排序
sort函数中只有一个reverse参数,实现的是整体的排序方向控制,因此成绩和学号都是降序,与业务不相符。
下面通过两步操作来实现不同的方向控制,即成绩降序、学号升序:
#两步操作list_ex.sort(key=lambda x:(x['id'])) #先按照第二字段Id升序list_ex.sort(key=lambda x:(x['score']),reverse=True)#再按照第一字段Score降序排列list_ex
控制多字段的排序方向
这样就实现了业务想要的排序操作,排过序的列表按照成绩降序,同分的学生按学号由小到大排序。
DataFrame:sort_values
除了list自带的sort函数,还可以把list转换成dataframe,然后使用datafram的sort_values函数。
#把list转换为dataframedf_ex = pd.DataFrame(list_ex)print(type(df_ex))df_ex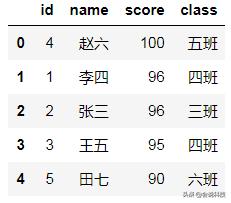
dataframe
#按照成绩score降序,ascending控制排序方向,True为升序,False为降序df_ex.sort_values(by='score',ascending=False)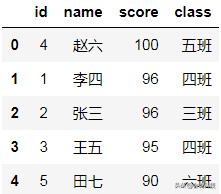
按成绩降序
#两步法,先按照第二字段ID升序,再按照第一字段score降序df_ex.sort_values(by='id',ascending=True)df_ex.sort_values(by='score',ascending=False)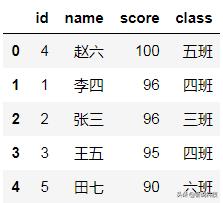
按成绩、学号排序
这样这实现了对包含json数据的list排序,您还有其他高效方法吗?欢迎评论区留言,一起交流交流。
我是会说科技,关注我,一起聊聊数据、科技、IT、安全、金融那些琐事。















 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









