






本文只讲述bert文本分类应用,不涉及理论部分。亲测应用很简便,在预训练模型基础上,个人电脑完全可以小规模训练属于自己的模型,而且准确率很高。这里给出英文文本分类应用流程,需要自己准备数据。
文本分类应用:情感分类(正负情绪)、文本类别分类(自定义类别,如文学、科技、体育等)等等
一、环境准备(本实验是mac系统,win系统也类似)
1、安装python3(pycharm可以安装,为了方便)
2、安装TensorFlow(pip install tensorflow)
3、本文加载数据用了pandas,所以需要pip install pandas
4、下载bert程序和模型,https://github.com/google-research/bert
二、程序目录结构
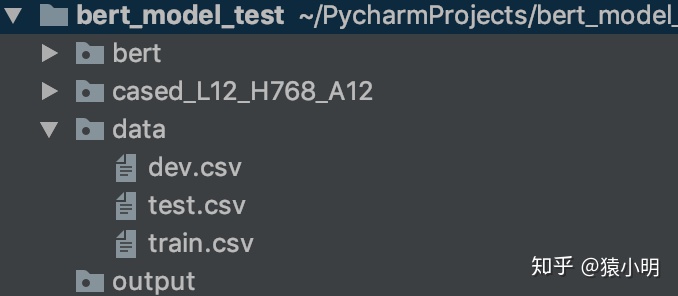
1、bert_model_test文件夹:自建的
2、bert文件夹:github地址下载的bert程序代码,里边是python文件
3、cased_L12_H768_A12文件夹:github地址下载的bert预训练模型
4、data文件夹:存放数据文件,就是图中的3个csv
5、output文件夹:TensorFlow训练模型输出文件夹
三、数据说明(数据格式自定义,这里用csv)
1、文件说明
train.csv:训练数据集,需要有label
dev.csv:开发集,需要有label,模型评估准确性等指标
test.csv:测试集,不需要label,模型评价给出每个数据分类概率
2、csv文件格式说明
第一列是标签1表示正、0表示负例,第二列是文本,例如2行数据:
1,I like this book
0,I dislike this book
四、添加自定义训练程序(加载数据代码)
找到bert文件夹下run_classier.py文件,在该文件里添加如下两段代码
1、添加数据加载代码
注意:如果是自定义文件格式,需要按照自己数据格式修改下面的代码。重点是把训练文本赋值给text_a,把标签赋值给label。也可用上文csv格式,直接copy代码即可。
class 2、在main(_)函数添加MyProcessor
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"my": MyProcessor
}五、训练
打开terminal命令框,cd进入bert_model_test文件夹,输入命令如下
(1)将python工作目录制定到bert
export PYTHONPATH=$PYTHONPATH:pwd:pwd/bert
(2)训练命令(模型将保存到output文件夹,几千条数据1小时左右)
该行命令加载train.csv做训练,用dev.csv做预测结果展示
python bert/run_classifier.py --data_dir=data/ --task_name=my --vocab_file=cased_L12_H768_A12/vocab.txt --bert_config_file=cased_L12_H768_A12/bert_config.json --output_dir=output/ --do_train=true --do_eval=true --init_checkpoint=cased_L12_H768_A12/bert_model.ckpt --max_seq_length=32 --train_batch_size=32 --learning_rate=5e-5 --num_train_epochs=1.0 --save_checkpoints_steps=100 --iterations_per_loop=100参数说明:
data_dir:数据所在目录
task_name:main(_)里边自定义任务名
output_dir:模型训练后保存路径
do_train:是否执行训练
do_eval:是否在dev集评估,可给出准确率
max_seq_length:cell数量(该实验128就很好了)
train_batch_size:每次迭代输入数据量
num_train_epochs:训练数据集训练的轮数
save_checkpoints_steps:每训练多少步存储一次模型(一个batch算一步)
iterations_per_loop:How many steps to make in each estimator call,有待研究,先和save_checkpoints_steps一样,和默认一样。
六、预测
该条命令加载test.csv文件进行预测
python bert/run_classifier.py --data_dir=data/ --task_name=my --vocab_file=cased_L12_H768_A12/vocab.txt --bert_config_file=cased_L12_H768_A12/bert_config.json --output_dir=output/ --do_predict=true --init_checkpoint=output --max_seq_length=32输出一个文件,有若干列(label数量),每列表示一个数据对应分类的概率。
比如2个预测数据、2分类,实例如下:
0.123 0.877
0.933 0.067
七、结论
bert训练有点慢,模型输出大概1.3G,比用tf实现的lstm情感分类,dev数据集准确率可提高4%~5%。自建英文数据集在2000多条,标的还算认真,dev准确率lstm能到89%,bert准确率可到94%
如果您觉得还有价值,欢迎关注 @猿小明,长期更新程序猿酸甜苦辣,干货不断。
如果想随时互动交流获取资料,请关注公众号:迷茫猿小明















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









