





作者:黄天元,复旦大学博士在读,热爱数据科学与开源工具(R),致力于利用数据科学迅速积累行业经验优势和科学知识发现,涉猎内容包括但不限于信息计量、机器学习、数据可视化、应用统计建模、知识图谱等,著有《R语言数据高效处理指南》(《R语言数据高效处理指南》(黄天元)【摘要 书评 试读】- 京东图书)。知乎专栏:R语言数据挖掘。邮箱:huang.tian-yuan@qq.com.欢迎合作交流。
如果做了一个模型,要知道它是不是有效怎么办?没有比较就没有伤害,因此要通过不同模型的相互比较,来看谁比谁好。那么究竟要跟谁比较呢?这是个问题,其实目前有一系列的基准,下面一一列出:
1、序列平均值:基本假设是该时间序列就是以均值为中心上下波动的序列,那么用其均值就是最好的预测;
2、序列最终值:因为很多指标具有短期不变性,因此用最终值就能够最好地预测短期的状态。如果假设后面的情况就不会再改变,这种方法就会很靠谱;
3、季节最终值:如果序列具有明显的季节性特征,比如今年的春夏秋冬温度,不能都参照均值或最终值,而应该参考上一年春夏秋冬的温度。这种用上一期周期中的数值作为本期的预测方法,叫季节简单预测方法;
4、趋势预测:基于现有的序列构建简单线性回归模型(只取起始点和最终点构建线性模型),然后获得一条笔直的直线。
在教程中(3.1 Some simple forecasting methods | Forecasting: Principles and Practice),上面四种方法分别称为Average method/Naive method/Seasonal naive method/Drift method,在R中实现的函数分别为:meanf/naive/snaive/rwf(drift = T)。下面用一个例子说明所有的情况:
library(fpp2)
# 提取一个时间序列
beer2 <- window(ausbeer,start=1992,end=c(2007,4))
# 绘制4种不同的基线模型
autoplot(beer2) +
autolayer(meanf(beer2, h=11),
series="Mean", PI=FALSE) +
autolayer(naive(beer2, h=11),
series="Naïve", PI=FALSE) +
autolayer(snaive(beer2, h=11),
series="Seasonal naïve", PI=F) +
autolayer(rwf(beer2, drift = T,h=11),
series="Drift", PI=F) +
ggtitle("Forecasts for quarterly beer production") +
xlab("Year") + ylab("Megalitres") +
guides(colour=guide_legend(title="Forecast"))
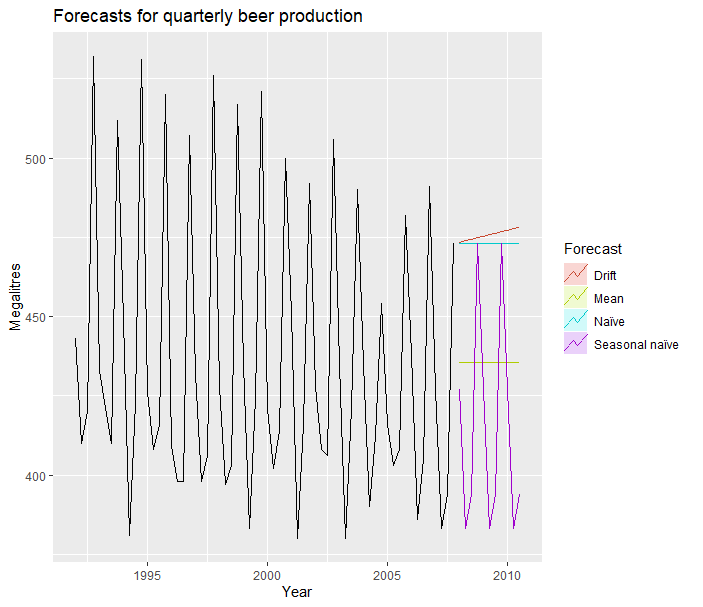
一些解释:1、h是指我们要预测后面多少个时间单位的数值;2、PI如果等于TRUE,那么会有置信区间的阴影波动范围,默认值应为80%-95%。
后面我们会接触到很多新的时间序列预测模型,如果得到的结果都没有比这些基线模型好,那么还不如简单地用这些基线模型进行预测。因此,基线是衡量模型效果的重要概念。














 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









