





1.字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典是Python中唯一内建的映射类型,字典的每一个元素可以形成(key=>value)对。
实例1:
创建员工信息表时如何将所有员工的工资默认值设置为3000?
>>> aDict = {}.fromkeys(('Wangdachui', 'Niuyun', 'Linling', 'Tianqi'),3000)>>> aDict{'Tianqi': 3000, 'Wangdachui': 3000, 'Niuyun': 3000, 'Linling': 3000}实例2:
已知有姓名列表和工资列表,如何生成字典类型的员工信息表?
>>> names = ['Wangdachui', 'Niuyun', 'Linling', 'Tianqi']>>> salaries = [3000, 2000, 4500, 8000]>>> dict(zip(names,salaries)){'Tianqi': 8000, 'Wangdachui': 3000, 'Niuyun': 2000, 'Linling': 4500}实例3:
对于几个公司的财经数据,如何构造公司代码和股票价格的字典?
pList = [('AXP', 'American Express Company', '78.51'), ('BA', 'The Boeing Company', '184.76'), ('CAT', 'Caterpillar Inc.', '96.39'), ('CSCO', 'Cisco Systems,Inc.', '33.71'), ('CVX', 'Chevron Corporation', '106.09')]aList = []bList = []for i in range(5): aStr = pList[i][0] bStr = pList[i][2] aList.append(aStr) bList.append(bStr)aDict = dict(zip(aList,bList))print(aDict)#输出结果:{'AXP': '78.51', 'BA': '184.76', 'CAT ': '96.39', 'CSCO': '33.71', 'CVX': '106.09'}2,字典的使用字典中有很多简单的运算和方便的函数,一旦掌握可以极速的提高码代码的效率和降低代码量。
1.1 字典的基本操作
字典的基本操作有很多,例如键值查找、更新、添加、成员判断、删除字典成员。
>>> aInfo = {'Wangdachui': 3000, 'Niuyun':2000, 'Linling':4500, 'Tianqi':8000}>>> aInfo['Niuyun']2000>>> aInfo['Niuyun'] = 9999>>> aInfo{'Tianqi': 8000, 'Wangdachui': 3000, 'Linling': 4500, 'Niuyun': 9999}>>> aInfo['Fuyun'] = 1000>>> aInfo{'Tianqi': 8000, 'Fuyun': 1000, 'Wangdachui': 3000, 'Linling': 4500, 'Niuyun': 9999}>>> 'Mayun' in aInfoFalse>>> del aInfo['Fuyun']>>> aInfo{'Tianqi': 8000, 'Wangdachui': 3000, 'Linling': 4500, 'Niuyun': 9999}2.2 字典方法items方法可以把每对键和值组成一个元祖,然后把它们放到一个本质是列表的对象dict_items中返回,可对它进行遍历,输出每一个键和值。
aInfo = {'Wangdachui': 3000, 'Niuyun': 2000, 'Linling': 4500, 'Tianqi': 8000}>>> for k, v in aInfo.items(): print(k, v)更新字典内容,update方法。实例:人事部门有两份人员和工资信息表,第一份是原有信息,第二份是公司中有工资更改人员和新进人员的信息,如何处理可以较快地获得完整的信息表?>>> aInfo = {'Wangdachui': 3000, 'Niuyun': 2000, 'Linling': 4500}>>> bInfo = {'Wangdachui': 4000, 'Niuyun': 9999, 'Wangzi': 6000}>>> aInfo.update(bInfo)>>> aInfo{'Wangzi': 6000, 'Linling': 4500, 'Wangdachui': 4000, 'Niuyun': 9999}使用get 方法查找字典值,如果不存在不会发生异常,不会使程序中止,会返回None(默认值)。>>> stock = {'AXP': 78.51, 'BA': 184.76}>>> stock['AAA']Traceback (most recent call last):File "", line 1, in <module>KeyError: 'AAA'#######################>>> stock = {'AXP': 78.51, 'BA': 184.76}>>> print(stock.get('AAA'))None其他常用方法
字典相关使用小案例
-
JSON格式:json格式是网络上一种非常流行的轻量级的数据交换格式,很多网站都使用这种格式,json格式是由一组一组的名称和值对组成的。
>>> x = {"name":"Niuyun","address": {"city":"Beijing","street":"Chaoyang Road"} }>>> x['address']['street']'Chaoyang Road'可变长关键字参数(字典)>>> def func(args1, *argst, **argsd):print(args1)print(argst)print(argsd)>>> func('Hello,','Wangdachui','Niuyun','Linling',a1= 1,a2=2,a3=3)Hello,('Wangdachui', 'Niuyun', 'Linling'){'a1': 1, 'a3': 3, 'a2': 2}也可以使用这种方式>>> names = ['Wangdachuan', 'Liuyun', 'Linling']>>> info = {'a1' : 1, 'a2' : 2, 'a3' : 3}>>> greeting('Hello,', *names, **info)字典是支持无限极嵌套的,如下面代码:
cities={ '北京':{ '朝阳':['国贸','CBD','天阶','我爱我家','链接地产'], '海淀':['圆明园','苏州街','中关村','北京大学'], '昌平':['沙河','南口','小汤山',], '怀柔':['桃花','梅花','大山'], '密云':['密云A','密云B','密云C'] }, '河北':{ '石家庄':['石家庄A','石家庄B','石家庄C','石家庄D','石家庄E'], '张家口':['张家口A','张家口B','张家口C'], '承德':['承德A','承德B','承德C','承德D'] }}2. 集合
集合是一个无序的不重复元素序列。
特殊使用:删除列表内容重复项
>>> names = ['Wangdachui', 'Niuyun', 'Wangzi', 'Wangdachui', 'Linling', 'Niuyun']>>> namesSet = set(names)>>> namesSet{'Wangzi', 'Wangdachui', 'Niuyun', 'Linling'}可变集合(set):通过set()函数创建可变集合
不可变集合(frozenset):通过forzenset()函数创建不可不变集合。
>>> aSet = set('hello')>>> aSet{'h', 'e', 'l', 'o'}>>> fSet = frozenset('hello')>>> fSetfrozenset({'h', 'e', 'l', 'o'})>>> type(aSet)<class 'set'>>>> type(fSet)<class 'frozenset'>集合可以进行各种关系运算,比如交&,并|,差-,异或^。
>>> aSet = set('sunrise')>>> bSet = set('sunset')>>> aSet & bSet{'u', 's', 'e', 'n'}>>> aSet | bSet{'e', 'i', 'n', 's', 'r', 'u', 't'}>>> aSet - bSet{'i', 'r'}>>> aSet ^ bSet{'i', 'r', 't'}>>> aSet -= set('sun')>>> aSet{'e', 'i', 'r'}内建函数
集合里面的内建函数分成两类:
1:面向所有集合的函数

>>> aSet = set('sunrise')>>> bSet = set('sunset')>>> aSet.issubset(bSet)False>>> aSet.intersection(bSet){'u', 's', 'e', 'n'}>>> aSet.difference(bSet){'i', 'r'}>>> cSet = aSet.copy()>>> cSet{'s', 'r', 'e', 'i', 'u', 'n'}2:面向可变集合的函数
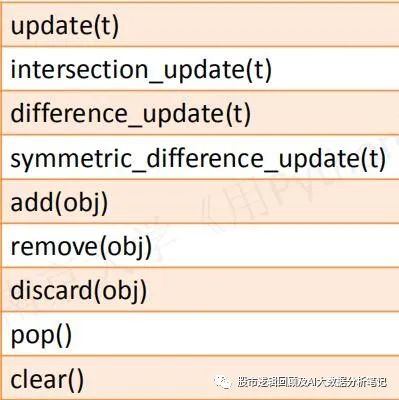
>>> aSet = set('sunrise')>>> aSet.add('!')>>> aSet{'!', 'e', 'i', 'n', 's', 'r', 'u'}>>> aSet.remove('!')>>> aSet{'e', 'i', 'n', 's', 'r', 'u'}>>> aSet.update('Yeah')>>> aSet{'a', 'e', 'i', 'h', 'n', 's', 'r', 'u', 'Y'}>>> aSet.clear()>>> aSetset()到这里为止的Python基础数据结构就介绍完了,我们的例子中也讨论了一些解决问题的方法,关于利用Python基础数据结构解决问题这里来做一个简单的总结。
2.1.利用列表
根据问题的需求选择使用append()或extend()方法,常见形式如:
lst = []for x in 可迭代对象: lst.append(x)要特别提醒的是,有时我们在append数据时不一定是一个简单的变量,也可以是一个元组,或者元素的索引等,例如lst.append((a,b))或lst.append((a, a的index)),选择合适可以对后续问题的解决带来较大的便利。
2.2. 利用字符串
字符串在数据位数不确定的情况下非常有用,常用方式是:
ln = ''for x in 可迭代对象: ln += x2.3. 利用字典
添加字典元素的方式是:
d = {}for x in 可迭代对象: d[item] = x如果值不是一个简单元素而是例如一个列表的话,可用如下方式:
d[item] = [value1]d[item] += [value2, value3, ...]2.4. 利用集合
如果问题中要求去重,那最合适的数据结构就是集合,常用如下形式处理:
Set = {}for x in 可迭代对象: Set.add(x)3.扩展库SciPy
Python现有数据结构已经非常丰富,但对于某些科学和工程问题来说还不够方便,SciPy是一个基于Python的软件生态圈。
SciPy特征:
-
基于Python的软件生态系统
开源
主要为数学、科学和工程服务
六大核心包:Numpy、Scipy library、Matplotlib、Ipython、sympy、pandas
官网scipy.ory
3.1 Scipy 中的数据结构
Scipy 中的数据结构(Python标准数据结构的扩展形式)有:
-
ndarray(N维数组)
Series(变长字典)
DataFrame(数据框)
NumPy:特征
强大的ndarray对象和ufunc函数
精巧的函数
比较适合线性代数和随机数处理等科学计算
有效的通用多维数据,可定义任意数据类型
无缝对接数据库
>>> import numpy as np>>> xArray = np.ones((3,4))Scipy核心库特征:
基于NumPy,是Python中科学计算程序的核心包,与NumPy中的函数有交集,但更丰富,有些功能更强
有效计算numpy矩阵,让numpy和scipy协同工作
致力于科学计算中常见问题的各个工具箱,其不同子模块有不同的应用,如插值、积分、优化和图像处理等
>>> import numpy as np>>> from scipy import linalg>>> arr = np.array([[1,2],[3,4]])>>> linalg.det(arr)-2.0Matplotlib:
基于NumPy
二维绘图库,简单快速地生成曲线图、直方图和散点图等形式的图
常用的pyplot是一个简单提供类似MATLAB接口的模块
pandas:
基于 SciPy 和 NumPy
高效的Series和DataFrame数据结构
强大的可扩展数据操作与分析的Python库
高效处理大数据集的切片等功能
提供优化库功能读写多种文件格式,如CSV、HDF5
4 ndarray
列表和元祖可以当数组使用,但是它们和数组有点不一样,元素组成像列表可以是任意类型,因此列表中保存的是对象的指针。
ndarray是NumPy中的基本数据结构,别名为array(数组),数组中的所有元素都是同一种类型,利于节省内存和提高CPU计算时间,有丰富的函数。
4.1 ndarray基本概念
ndarray数组属性(N维数组)
维度(dimensions)称为轴(axis),轴的个数称为致(rank)
基本属性:
• ndarray.ndim(秩)
• ndarray.shape(维度)
• ndarray.size(元素总个数)
• ndarray.dtype(元素类型)
• ndarray.itemsize(元素字节大小)
>>> import numpy as np>>> x = np.array([(1,2,3),(4,5,6)])>>> xarray([[1, 2, 3], [4, 5, 6]])>>> x.ndim2>>> x.shape(2,3)>>> x.size6ndarray的创建方法
在NumPy中提供了很多ndarray的创建函数,列如:arange 、array、copy、 empty、empty_like 、eye、fromfile 、fromfunction、identity 、linspace、logspace 、mgrid、ogrid 、ones、ones_like 、r、zeros 、zeros_like
>>> import numpy as np>>> aArray = np.array([1,2,3])>>> aArrayarray([1, 2, 3])>>> bArray = np.array([(1,2,3),(4,5,6)])>>> bArrayarray([[1, 2, 3], [4, 5, 6]])>>> np.arange(1,5,0.5)array([ 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5])>>> np.random.random((2,2))array([[ 0.79777004, 0.1468679 ], [ 0.95838379, 0.86106278]])>>> np.linspace(1, 2, 10, endpoint=False)array([ 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9])>>> np.ones([2,3])array([[ 1., 1., 1.], [ 1., 1., 1.]])>>> np.zeros((2,2))array([[ 0., 0.], [ 0., 0.]])>>> np.fromfunction(lambda i,j:(i+1)*(j+1), (9,9))array([[ 1., 2., 3., 4., 5., 6., 7., 8., 9.], [ 2., 4., 6., 8., 10., 12., 14., 16., 18.], [ 3., 6., 9., 12., 15., 18., 21., 24., 27.], [ 4., 8., 12., 16., 20., 24., 28., 32., 36.], [ 5., 10., 15., 20., 25., 30., 35., 40., 45.], [ 6., 12., 18., 24., 30., 36., 42., 48., 54.], [ 7., 14., 21., 28., 35., 42., 49., 56., 63.], [ 8., 16., 24., 32., 40., 48., 56., 64., 72.], [ 9., 18., 27., 36., 45., 54., 63., 72., 81.]])ndarray的操作方法:切片
>>> aArray = np.array([(1,2,3),(4,5,6)])array([[1, 2, 3], [4, 5, 6]])>>> print(aArray[1])[4,5,6]>>> print(aArray[0:2])[[1,2 ,3],[4 ,5 ,6]]>>> print(aArray[:,[0,1]])[[1 ,2],[4 ,5]]>>> print(aArray[1,[0,1]])[4 ,5]>>> for row in aArray: print(row)[1 ,2, 3],[4, 5 ,6]通过函数对ndarray进行操作
>>> aArray = np.array([(1,2,3),(4,5,6)])>>> aArray.shape(2, 3)>>> bArray = aArray.reshape(3,2)>>> bArrayarray([[1, 2], [3, 4], [5, 6]])>>> aArrayarray([[1, 2, 3], [4, 5, 6]])>>> aArray.resize(3,2)>>> aArrayarray([[1, 2], [3, 4], [5, 6]])>>> bArray = np.array([1,3,7])>>> cArray = np.array([3,5,8])>>> np.vstack((bArray, cArray))array([[1, 3, 7], [3, 5, 8]])>>> np.hstack((bArray, cArray))array([1, 3, 7, 3, 5, 8])ndarray的运算
>>> aArray = np.array([(5,5,5),(5,5,5)])>>> bArray = np.array([(2,2,2),(2,2,2)])>>> cArray = aArray * bArray>>> cArrayarray([[10, 10, 10], [10, 10, 10]])>>> aArray += bArray>>> aArrayarray([[7, 7, 7], [7, 7, 7]])>>> a = np.array([1,2,3])>>> b = np.array([[1,2,3],[4,5,6]])>>> a + b #广播机制相加array([[2, 4, 6], [5, 7, 9]])利用基本数组的统计方法进行运算:sum 、mean、std 、var、min 、max、argmin 、argmax、cumsum 、cumprod
>>> aArray = np.array([(1,2,3),(4,5,6)])>>> aArray.sum()21>>> aArray.sum(axis = 0)array([5, 7, 9])>>> aArray.sum(axis = 1)array([ 6, 15])>>> aArray.min() # return value1>>> aArray.argmax() # return index5>>> aArray.mean()3.5>>> aArray.var()2.9166666666666665>>> aArray.std()1.707825127659933ndarray的专门应用——线性代数
dot 矩阵内积
linalg.det 行列式
linalg.inv 逆矩阵
linalg.solve 多元一次方程组求根
linalg.eig 求特征值和特征向量
>>> import numpy as np>>> x = np.array([[1,2], [3,4]])>>> r1 = np.linalg.det(x)>>> print(r1)-2.0>>> r2 = np.linalg.inv(x)>>> print(r2)[[-2. 1. ] [ 1.5 -0.5]]>>> r3 = np.dot(x, x)>>> print(r3)[[ 7 10] [15 22]]ndarray的ufunc函数(通用函数)
ufunc是一种能对数组的每个元素进行操作的函数。Numpy内置的许多ufunc函数都是在C语言级别实现的,计算速度特别快。特别是数据量比较大的时候,使用ufun函数比match库计算更加方便。比例add, all, any, arange, apply_along_axis, argmax, argmin, argsort, average, bincount, ceil, clip, conj, corrcoef, cov, cross, cumprod, cumsum, diff, dot, exp, floor, …
import timeimport mathimport numpy as npx = np.arange(0, 100, 0.01)t_m1 = time.process_time()for i, t in enumerate(x): x[i] = math.pow((math.sin(t)), 2)t_m2 = time.process_time()y = np.arange(0,100,0.01)t_n1 = time.process_time()y = np.power(np.sin(y), 2)t_n2 = time.process_time()print('Running time of math:', t_m2 - t_m1)print('Running time of numpy:', t_n2 - t_n1)5.变长字典Series
Python中字典是一种无序的数据结构,它的key和value之间存在映射关系,但是字典的key和value之间是不独立的。而pandas中的series这样的一种数据结构是不一样,它相当于一个定长有序的字典,它的index和value之间是独立的,所以它在某些应用中比字典更方便。
series基本特征:
-
类似一维数组的对象
有数据和索引组成
>>> import pandas as pd>>> aSer = pd.Series([1,2.0,'a'])>>> aSer0 11 22 adtype: object默认前面的索引,0~n,可以自定义series的index
>>> import pandas as pd>>> bSer = pd.Series(['apple','peach','lemon'], index = [1,2,3])>>> bSer1 apple2 peach3 lemondtype: object>>> bSer.indexInt64Index([1, 2, 3], dtype='int64')>>> bSer.valuesarray(['apple', 'peach', 'lemon'], dtype=object)因为series类似字典,它可以和字典一样通过index来访问数据得到相应的值,也可以通过基本运算符和一些内置函数来进行数据操作。
>>> aSer = pd.Series([3,5,7],index = ['a','b','c'])>>> aSer['b'] 5>>> aSer * 2a 6b 10c 14dtype: int64>>> import numpy as np>>> np.exp(aSer)a 20.085537b 148.413159c 1096.633158dtype: float64数据对齐是series的一个非常重要的功能。在运算中自动对齐不同索引的数据。
>>> data = {'AXP':'86.40','CSCO':'122.64','BA':'99.44'}>>> sindex = ['AXP','CSCO','BA','AAPL']>>> aSer = pd.Series(data, index = sindex)>>> aSerAXP 86.40CSCO 122.64BA 99.44AAPL NaNdtype: object>>> pd.isnull(aSer)AXP FalseCSCO FalseBA FalseAAPL Truedtype: bool>>> aSer = pd.Series(data, index = sindex)>>> aSerAXP 86.40CSCO 122.64BA 99.44AAPL NaNdtype: object>>> bSer = {'AXP':'86.40','CSCO':'122.64','CVX':'23.78'}>>> cSer = pd.Series(bSer)>>> aSer + cSerAAPL NaNAXP 86.4086.40BA NaNCSCO 122.64122.64CVX NaNdtype: object7. DataFrame
series对应的是一维序列,而DataFrame对应的是二维表结构。它是一种表格形的数据结构。它包含一组类似index的有序列,每列可以是不同类型的值,因此可以把DataFrame看作是共享同一个index的Series的集合。
创建DataFrame
>>> data = {'name': ['Wangdachui', 'Linling', 'Niuyun'], 'pay': [4000, 5000, 6000]}>>> frame = pd.DataFrame(data)>>> frame name pay0 Wangdachui 40001 Linling 50002 Niuyun 6000######################>>> data = np.array([('Wangdachui', 4000), ('Linling', 5000), ('Niuyun', 6000)])>>> frame =pd.DataFrame(data, index = range(1, 4), columns = ['name', 'pay'])>>> frame name pay1 Wangdachui 40002 Linling 50003 Niuyun 6000>>> frame.indexRangeIndex(start=1, stop=4, step=1)>>> frame.columnsIndex(['name', 'pay'], dtype='object')>>> frame.valuesarray([['Wangdachui', '4000'], ['Linling', '5000'], ['Niuyun', '6000']], dtype=object)基本操作:取DataFrame对象的列和行可获得Series>>> frame['name']0 Wangdachui1 Linling2 NiuyunName: name, dtype: object>>> frame.pay0 40001 50002 6000Name: pay, dtype: int64>>> frame.iloc[ : 2, 1]0 40001 5000Name: pay, dtype: objectDataFrame对象的修改和删除>>> frame['name'] = 'admin'>>> frame name pay0 admin 40001 admin 50002 admin 6000>>> del frame['pay']>>> frame name0 admin1 admin2 admin[3 rows x 1 columns]统计功能>>> frame.pay.min()'4000'#方法得到的返回值是字符串>>> frame[frame.pay >= '5000'] name pay1 Linling 50002 Niuyun 6000DataFrame 修改操作综合实例
DataFrame 对象(或 Series 对象)创建好以后常常需要修改包括添加、删除和直接修
改行和列数据等,假设数据框 aDF 的值如下所示:
>>> aDF name pay0 Mayue 30001 Lilin 45002 Wuyun 8000(1)添加列
添加列可直接赋值,例如给 aDF 中添加 tax 列的方法如下:
>>> aDF['tax'] = [0.05, 0.05, 0.1]>>> aDF name pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.1(2)添加行
添加行可用对象的标签(loc)和位置(iloc)索引,也可通过 append()方法或 concat()
函数等进行处理,以 loc 为例,例如要给 aDF 添加一个新行,可用如下方法:
>>> aDF.loc[5] = {'name': 'Liuxi', 'pay': 5000, 'tax': 0.05}>>> aDF name pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.15 Liuxi 5000 0.05其中 5 为行标签。(3)删除对象元素
删除数据可直接用“del 数据”的方式进行,但这种方式是直接对原始数据操作,不是很安全,pandas 中可利用 drop()方法删除指定轴上的数据,drop()方法返回一个新的对
象,不会直接修改原始数据。例如:
删除行标签为 5 的行(aDF 没有变):
>>> aDF.drop(5) name pay tax0 Mayue 3000 0.051 Lilin 4500 0.05 2 Wuyun 8000 0.1删除 tax 列:
>>> aDF.drop('tax', axis = 1) name pay0 Mayue 30001 Lilin 45002 Wuyun 80005 Liuxi 5000可通过循环或类似“aDF.drop(['pay', 'tax'], axis = 1)”这样的方式删除多行或多列数据。此时 aDF 的值没有受影响:
>>> aDF name pay tax0 Mayue 3000 0.051 Lilin 4500 0.052 Wuyun 8000 0.15 Liuxi 5000 0.05可以通过设置 aDF.drop(..., inplace=True)属性直接修改 aDF。(4)修改
除了添加和删除 DataFrame(或 Series)中的元素外,还可以直接对原始数据进行修
改,例如要将 tax 列统一修改成 0.03,方法很简单:
>>> aDF['tax'] = 0.03>>> aDF name pay tax0 Mayue 3000 0.031 Lilin 4500 0.032 Wuyun 8000 0.035 Liuxi 5000 0.03如果要修改某一行的数据也可用如下方法实现:
>>> aDF.loc[5] = ['Liuxi', 9800, 0.05] name pay tax0 Mayue 3000 0.031 Lilin 4500 0.032 Wuyun 8000 0.035 Liuxi 9800 0.05另外,还可以通过例如"aDF.loc[:, ['name', 'tax', 'pay']" 或"aDF.iloc[:, [0,2,1]",或reindex()方法交换一个 DataFrame 对象的列或行。
7.字典和集合编程实例
字典1-统计英文单词词频
词频统计是经典文本处理的基础问题,中文和英文的词频统计有所不同,中文需要先分词然后再统计,而英文单词中间有空格分隔,可以快速分隔,但是英文后面会有标段符号。分词做适当处理后中英文统计词频的方法是一样的。最简单做法是利用collections模块中的counter()函数来统计词频。自定义统计使用字典方法更适用自己的使用。
poem_EN = 'Early in the day it was whispered that we should sail in a boat, only thou and I, and never a soul in the world would know of this our pilgrimage to no country and to no end.'poem_list = poem_EN.split()p_dict = {}for item in poem_list: if item[-1] in ',.\'"': item = item[:-1] ''' if item[-1] not in p_dict: p_dict[item] = 1 else: p_dict[item] += 1 ''' p_dict[item] = p_dict.get(item,0) + 1p_dict字典2- 运动会班级人数统计排序
文件file,txt中保存了若干条参加运动会学生的报名记录,每条记录的形式为“班级号_学号”例如“A1_12”,将每个班级报名情况按参加运动会人数从多到少排列(假设不存在人数相同的情况)并输出,输出结果如下:
A1 -> ['12','05','07','04']
A4 -> ['23'.'03','11']
A3 -> ['12','01']
A2 -> ['07']
def func(stu_list): d = {} for item in stu_list: r = item.split('_') a, b = r[0], r[1].strip() if a not in d: d[a] = [b] else: d[a] += [b] sorted(d.items(), key = lamnda d: len(d[1]), reverse = True) return lstif __name__ == "__main__": try: with open('file.txt') as f stu_list = f.readlines() except FileNotFoundError: print('the file does not exist') else: result = func(stu_list) for item in reslut: print(item[0], '->',item[1])集合--生成符合要求的学号
具体要求:
1:函数func()的功能是利用班级信息的字典数据随机选择班级并生成一个随机的学号。注意:学号共有6为,前4位为班级编号,后2位为某同学在班级中的序号,如A00101,序号从01开始顺序编号,并且不能超过该班级学生的总数;
2:__main__模块中包含班级信息字典,调用func()生成10个不重复的学生学号并且输出。其中,班级信息字典的键为班级编号,值为对应班级的学生总数。例如,当给定的班级信息为data={'A001":32,"A002":47, "B001":39,"B002":42}时,表示A001班共有32位同学,依次类推。
import randomdef func(data): cls_no = random.choice(list(data.key)) stu_no = random.randint(1,data[cls_no]) return "{}{:02}".format(cls_no,stu_no)if __name__ = "__main__": data = {'A001":32,"A002":47, "B001":39,"B002":42} result = set() while len(result) < 10: result.add(func(data)) print(result)8.Numpy的常用应用
1:创建一个边界值为1,内部为0的二维数组。
常规解决方案:先生成一个全1的数组,然后通过切片选择出内部区域将值设置为0。
In [1]:import numpy as np In [2]:x = np.ones((10,10))In [3]:xOut[3]:array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])In [4]:x[1:-1,1:-1] = 0In [5]:xOut[5]:array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])np.full()函数可以实现创建内部数字的数组,比np.ones()和np.zeros()的扩展性更好。
In [6]:x = np.full((10,10),np.pi)In [7]:xOut[7]:array([[3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265], [3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265]])与之相关的特殊功能的函数np.ones_like()、np.zeros_like()、np.full_like()。
In [9]:x = np.array([[1,2,3],[4,5,6]],dtype = np.float64)In [10]:xOut[10]:array([[1., 2., 3.], [4., 5., 6.]])In [11]:np.full_like(x, 4)Out[11]:array([[4., 4., 4.], [4., 4., 4.]])2.创建一个单位数组,用np.identity()或者np.eye(),eye()函数的扩展性更加好
In [12]:np.identity(10)Out[12]:array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])In [13]:np.eye(8)Out[13]:array([[1., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 1.]])In [14]:np.eye(8,k=1)Out[14]:array([[0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 1.], [0., 0., 0., 0., 0., 0., 0., 0.]])In [15]:np.eye(8,k=-2)Out[15]:array([[0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0.]])利用random模块从正态分布和均匀分布中各采样若干个元素
正态分布:np.random.normal(0,5,100)
均匀分布:np.random.uniform(-5,5,100)
采样方式:有放回采样,replace =Ture。无放回采样,replace = False
4.NumPy中数组的布尔索引
在一个数组当中如何获得满足条件的元素
In [20]:X = np.arange(1,51)In [21]:XOut[21]:array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50])In [22]:X < 25Out[22]:array([ True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False])In [23]:X[X < 25]Out[23]:array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24])In [28]:X[(X < 25) & (X % 2 == 0)]Out[28]: array([ 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24]) In [29]:X[X % 2 == 0] = -1In [30]:XOut[30]:array([ 1, -1, 3, -1, 5, -1, 7, -1, 9, -1, 11, -1, 13, -1, 15, -1, 17, -1, 19, -1, 21, -1, 23, -1, 25, -1, 27, -1, 29, -1, 31, -1, 33, -1, 35, -1, 37, -1, 39, -1, 41, -1, 43, -1, 45, -1, 47, -1, 49, -1])以上修改会直接改变数组中的原始数据,不修改原始数据使用numpy模块中的where()函数。where()函数是三元表达式,是“x if condition else y”的矢量化版本。
In [31]:np.where(X % 2 == 0, -1, X)Out[31]:array([ 1, -1, 3, -1, 5, -1, 7, -1, 9, -1, 11, -1, 13, -1, 15, -1, 17, -1, 19, -1, 21, -1, 23, -1, 25, -1, 27, -1, 29, -1, 31, -1, 33, -1, 35, -1, 37, -1, 39, -1, 41, -1, 43, -1, 45, -1, 47, -1, 49, -1])需要数据广播时候常常使用keepdims参数,默认Flase,改变计算均值后的维度,改为Ture,可以保持计算后维度不变,可以进行数学计算。
In [32]:scores = np.array([[98,76,87],[76,88,91]])In [33]:scores_mean = scores.mean(axis = 1)In [34]:scores_meanOut[34]: array([87., 85.])In [35]:scores_mean1 = scores.mean(axis = 1, keepdims = True)In [36]:scores_mean1Out[36]:array([[87.], [85.]])In 37]:scores - scores_mean1Out[37]:array([[ 11., -11., 0.], [ -9., 3., 6.]])














 1493
1493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









