





XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。xpath中节点之间的关系有父(parent)、子(children)、同胞(sibling)、先辈(ancestor)、后代(descendent)。xpath的具体教程可以在wc3school中学习。
在Python中xpath属于lxml库,因此需先安装lxml库。
实例:
from lxml import etreetxt =''' 我的公众号2019年 python 欢迎关注每日一Python
共同进步
谢谢
'''html = etree.HTML(txt)r = html.xpath("//h1/a/@href") #获取属性用@xxprint(r)

r2 = html.xpath("//title/@lang")print(r2)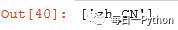
r3 = html.xpath("//comment()") #获取注释用comment()print(r3)
r4 = html.xpath("//gzh/year/text()") #获取文本内容用text()print(r4)
r5=html.xpath("//p")print(r5)#可以看到HTML中有两个P,若是想获取第一个和最后一个p呢#获取第一个pprint(r5[0].text)或者r6 = html.xpath("//p[1]/text()")
#获取最后一个p,利用last()r7 = html.xpath("//p[last()]/text()")print(r7)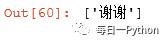















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









