







Python网络爬虫
二、Xpath语法详解
lxml是一个网页解析库。Xpath是一门在XML文档中查找信息的语言。Xpath课 用来在XML文档中对元素和属性进行遍历。
安装
pip install lxml
导入
import requests
from lxml import etree
创建一个简单的html样本,注意其特点,层层嵌套。
htm = '''
<html>
<div>
<ul>
<li class = "item-0"><a href="link1.html">first item</a></li>
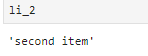
<li class = "item-1"><a href="link2.html">second item</a></li>
<li class = "item-inactive"><a href="link3.html">thrid item</a></li>
<li class = "item-1"><a href="link4.html">fourth item</a></li>
<li class = "item-0"><a href="link5.html">fifth item</a></li>
<li class = "else_1">something_else</li>
this is ui item
</ul>
</div>
</html>
'''
selector = etree.HTML(htm)#初始化etree
在这里补充下Xpath的常用规则

#查找所有的li
all_li = selector.xpath('//div/ul/li')
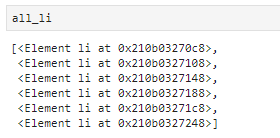
#查找第一个li
li_1 = selector.xpath('//div/ul/li[1]')
注意这里的索引是从1开始,而非从零开始。
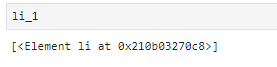
与上图比较,可以发现即为第一个li。
#提取第一个li下的a这个标签下的文本(first item)
li_text = selector.xpath('//div/ul/li[1]/a/text()')
注意这里只有一个a,因此不需要设置序号。
使用text()提取文本,另外,注意这里提取之后是一个列表,因此,可以通过索引取出该文本。
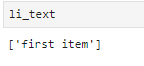
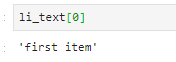
除此之外,还可以通过特定的属性进行查找。
#通过属性查找第三列的文本
li_3 = selector.xpath('//div/ul/li[@class = "item-inactive"]/a/text()')
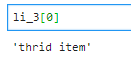
除此之外,如果该属性是独一无二的,则可以直接查找。
li_3 = selector.xpath('//li[@class = "item-inactive"]/a/text()')
#i_3 = selector.xpath('//*[@class = "item-inactive"]/a/text()'),*代表查找所有。
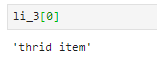
#通过href查找Li2的文本
li_2 = selector.xpath('//a[@href = "link2.html"]/text()')[0]
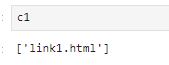
#提取href属性
c1 = selector.xpath('//li[1]/a/@href')
#获取所有的class
all_c = selector.xpath('//li/@class')

Xpath的一些高级用法
start_with(谁,干什么)
#提出属性为‘item-’开头的li
all_c = selector.xpath("//li[starts-with(@class,'item-')]")
#提取出all_c中的文本,注意此时all_c为list
all_a = []
for c in all_c:
all_a.append(c.xpath('a/text()')[0])

#也可以直接提取
all_a = selector.xpath("//li[starts-with(@class,'item-')]/a/text()")
string:提取出所有的文本
#提取所有文本
all_text = selector.xpath('string(//ul)')

一个小实例
爬取百度首页
bd = requests.get("https://www.baidu.com/")#获取网页
bd.encoding = 'utf-8'#选择解码方式
html = etree.HTML(bd.text)#进行初始化,将bd变成文本的形式
num = html.xpath('//*[@id="u1"]/a[1]/text()')[0]
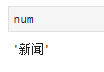
h1 = html.xpath('//*[@id="u1"]/a[1]/@herf')[0]
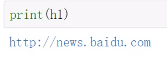
#获取百度首页的图片
h2 = html.xpath('//*[@id="lg"]/img/@src')[0]
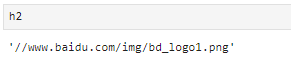
h3 = 'http:'+h2#补充完整
t = requests.get(h3)#图片的网址
with open('baidu.jpg','wb') as f:
f.write(t.content)#保以二进制写的形式打开二进制文件,保存图片

获取xpath的方法
进入网站,按下F12,按下Ctrl+Shif+C,将鼠标指向想要的数据位置,如图

在蓝色处,单击右键,选择copy,选择copy xpath。使用的浏览器为chrome,同时推荐下载xpath helper 插件。安装时会遇见一些问题,将下载好的.crx文件改成.rar文件,之后进行解压,再在chrome的扩展程序中进行打开。
Xpath helper 使用效果

使用方法:按下Ctr + Shift + X打开控制台,按下Ctr + Shift进行选取。
















 9312
9312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











