





首先给大家推荐一本书:机器学习算法原理与编程实践

本文内容全部转载于书中,相当于一个读书笔记了吧
绪论
1992年麻省理工学院通过实验对比了基于结构特征的方法与基于模版匹配的方法,发现模版匹配的方法要优于基于特征的方法。
以支持向量机为代表的统计学习理论在随后被应用到了人脸识别与确认中去。但是由于算法运行效率问题,很快被一种新的算法替代了。这就是2001年康柏研究院提出的基于简单矩形特征和AdaBoost的实时人脸检测系统。该方法的主要贡献包括:
1.可以快速计算简单矩形特征作为人脸图像特征
2.基于AdaBoost将大量弱分类器进行组合形成强分类器的学习方法。
3.采用了级联(Cascade)技术提高检测速度。目前,基于这种人脸/非人脸学习的策略已经能够实现准实时的多姿态人脸检测与跟踪,这为后端的人脸识别提供了良好的基础。
人脸检测
人脸检测主要用于人脸识别的预处理,即在图像中标注出人脸所处的位置和大小。为了能够确定图片中包含一张或几张人脸,首先要确定人脸的通用结构。我们都有:眼镜、鼻子,前额,颧骨和嘴,所有这些构成了一张通用的人脸结构。下图的特征组件分别标识了上述结构。
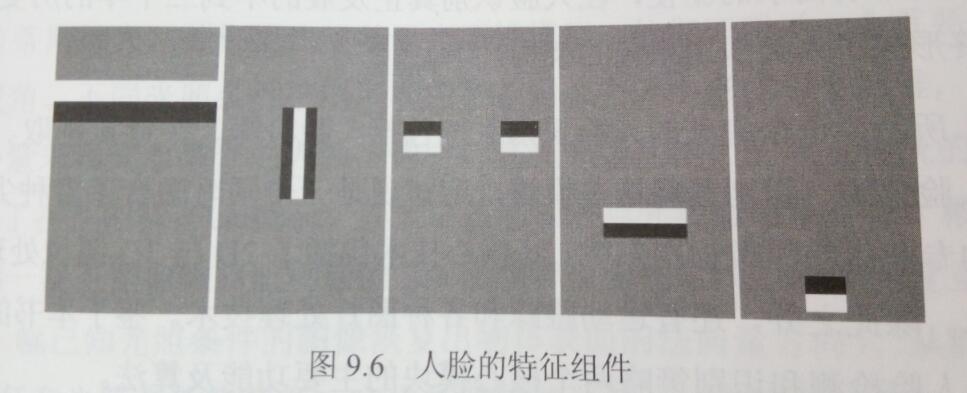
组合这些特征就可以得到一张近似的人脸:
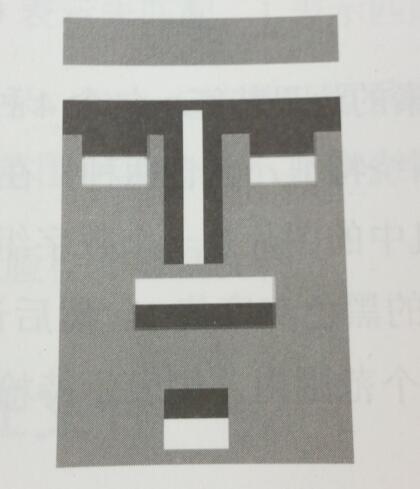
人脸检测的主流方法是AdaBoost,它是一种用来分类的方法,通过把一些比较弱的分类方法合在一起,可以组合出新的更强的分类器。AdaBoost有一个迭代的过程,为了快速处理,在每次迭代中,我们仅仅快速地排除图片中不属于人脸的区域,保留那些我们还不确定的区域。在每次迭代中,我们都提高了对图片中人脸定位的概率,直到做出最终的决定。换句话说,不同于确定图片中人脸的位置,我们选择的排除图片中不包含人脸位置,因为排除算法的运算速度更快。我们称这个过程为级联过程。
OpenCV中常用的特征分类器有两类:Haar特征和LBP特征
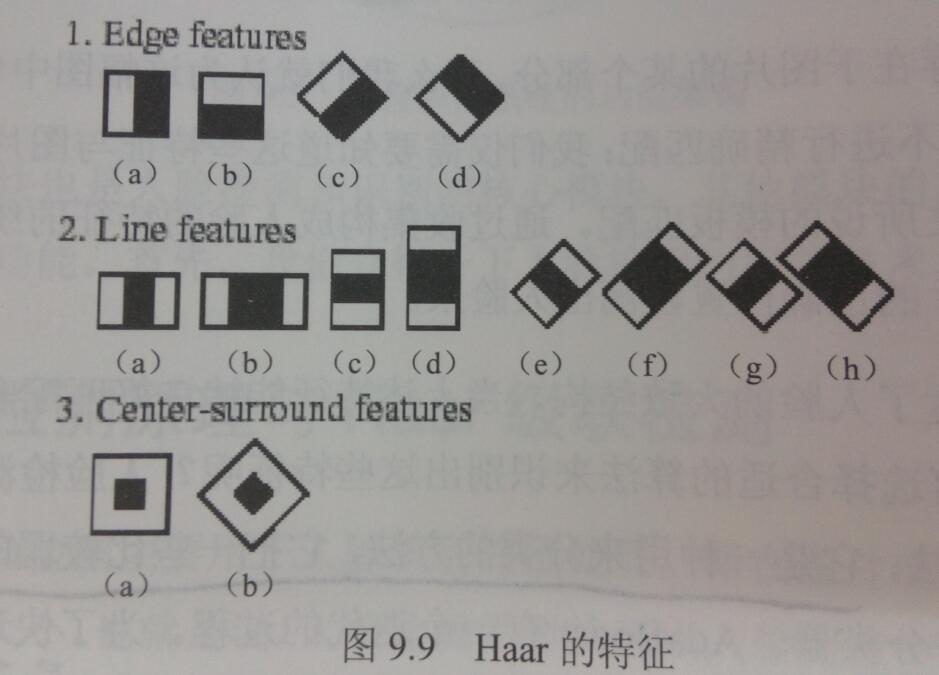
在OpenCV中使用Haar特征检测人脸,那么需要使用OpenCV提供的xml文件(级联表)在sources\data目录下。这张级联表有一个训练好的AdaBoost训练集。首先要采用样本的Haar特征训练分类器,从而得到一个级联的AdaBoost分类器。训练的方式包含两个方面:
1.正例样本,即待检测的目标样本
2.反例样本,即其他任意的图片
然后将这些图片统一缩放为相同的尺寸,这个过程就是归一化。最后统计出分类结果。
实现效果:

代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Jun 22 20:59:21 2016
@author: Administrator
"""
# -*- coding: utf-8 -*
import numpy as np
import cv2
#要使用Haar cascade实现,仅需要把库修改为lbpcascade_frontalface.xml
face_cascade = cv2.CascadeClassifier('lbpcascade_frontalface.xml')
img = cv2.imread('woman.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 识别输入图片中的人脸对象.返回对象的矩形尺寸
# 函数原型detectMultiScale(gray, 1.2,3,CV_HAAR_SCALE_IMAGE,Size(30, 30))
# gray需要识别的图片
# 1.03:表示每次图像尺寸减小的比例
# 5:表示每一个目标至少要被检测到4次才算是真的目标(因为周围的像素和不同的窗口大小都可以检测到人脸)
# CV_HAAR_SCALE_IMAGE表示不是缩放分类器来检测,而是缩放图像,Size(30, 30)为目标的最小最大尺寸
# faces:表示检测到的人脸目标序列
faces = face_cascade.detectMultiScale(gray, 1.03, 5)
for (x,y,w,h) in faces:
if w+h>200:#//针对这个图片画出最大的外框
img2 = cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,255),4)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite("head.jpg", img) # 保存图片
AdaBoost算法概述
Haar级联检测和LBP检测都是使用AdaBoost算法实现的。AdaBoost算法是Adaptive Boosting算法的缩写,是Boosting算法的改进版本。AdaBoost与其前身Boost算法都是从决策树发展出来的一种算法,其算法思想是针对同一个训练集样本的不同特征,分别训练出不同的弱分类器,然后把这些弱分类器级联起来,构成一个最终分类器,即强分类器。
从结构上讲,AdaBoost与其他的机器学习算法不同,该算法可以分为两层,第一层是AdaBoost主算法,第二层是其他的二分类算法,所以该算法是一种复合型算法。第二层最常用的是单层决策树。当然也可以是其他任何二分类算法。例如梯度下降算法、SVM等。
人脸识别
目前最常用的自动人脸识别技术仍旧是特征脸提取方法。特征脸方法是从整体上对人脸识别的方法:一种面部图像可以表示为从高维图像空间映射到地位空间的一个点。这样可以使得分类边的更加容易。
降维
一幅图像只能表示为一个对象,对于w x h的灰度图像,只能表示为w*h维的向量,那么100*100像素大小的图像就需要10000维的向量空间。对于一副人脸图像,显然在维数空间中只有少量像素对我们有用。所以可以降维,矩阵可以近似的表示为一个特征值和特征向量的乘积,如果我们能够提取出高维向量中某些特有的特征或者相关变量,就能用一个低维空间的向量近似地表示这个高维向量。对于这个高维向量,只有高喊最多信息的那些维上的数据才有意义,不重要的维可以在计算中忽略,并且降维之后的低维向量不会损失掉特征间的差异性。这就是主成份分析的思想(PCA),1901年就由皮尔逊发布了基本原理:

PCA人脸识别算法
PCA人脸识别算法的实现步骤如下:
1.首先把所有的训练图片集的每张图片都转换为行向量的形式
2.计算向量集的PCA子空间,并得到特征值和特征向量及均值
3.将训练集的图片与对应的标签都投影到这个PCA子空间,行程一个投影矩阵
4.导入待识别的图像,并进行向量化,也投影到这个PCA子空间
5.计算PCA投影后的训练集向量与待识别图片投影后向量的距离,并找出最接近的那个
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
import sys,os
import copy
import cv2
import PIL.Image as Image
import matplotlib.pyplot as plt
class Eigenfaces(object):
def __init__(self):
self.eps = 1.0e-16
self.X = []
self.y = []
self.Mat=[]
self.eig_v = 0
self.eig_vect = 0
self.mu = 0
self.projections = []
self.dist_metric=0
def loadimgs(self,path): # 加载图片数据集
classlabel = 0
for dirname, dirnames, filenames in os.walk(path):
for subdirname in dirnames:
sub_path = os.path.join(dirname, subdirname)
for filename in os.listdir(sub_path):
im = Image.open(os.path.join(sub_path, filename))
im = im.convert("L") #数据转换为long类型
self.X.append(np.asarray(im, dtype=np.uint8))
self.y.append(classlabel)
classlabel += 1
# 将图片变为行向量 # 生成图片矩阵
def genRowMatrix(self):
self.Mat = np.empty((0, self.X[0].size), dtype=self.X[0].dtype)
for row in self.X:
self.Mat = np.vstack((self.Mat, np.asarray(row).reshape(1,-1)))
# 计算特征脸
def PCA(self, pc_num =0):
self.genRowMatrix()
[n,d] = shape(self.Mat)
if ( pc_num <= 0) or ( pc_num>n): pc_num = n
self.mu = self.Mat.mean(axis =0)
self.Mat -= self.mu
if n>d:
XTX = np.dot (self.Mat.T,self.Mat)
[ self.eig_v , self.eig_vect ] = linalg.eigh (XTX)
else :
XTX = np.dot(self.Mat,self.Mat.T)
[ self.eig_v , self.eig_vect ] = linalg.eigh (XTX)
self.eig_vect = np.dot(self.Mat.T, self.eig_vect)
for i in xrange(n):
self.eig_vect[:,i] = self.eig_vect[:,i]/linalg.norm(self.eig_vect[:,i])
idx = np.argsort(-self.eig_v)
self.eig_v = self.eig_v[idx]
self.eig_vect = self.eig_vect[:,idx ]
self.eig_v = self.eig_v[0:pc_num ].copy () # select only pc_num
self.eig_vect = self.eig_vect[:,0:pc_num].copy ()
def compute(self):
self.PCA()
for xi in self.X:
self.projections.append(self.project(xi.reshape(1,-1)))
def distEclud(self, vecA, vecB): # 欧氏距离
return linalg.norm(vecA-vecB)+self.eps
def cosSim(self, vecA, vecB): # 夹角余弦
return (dot(vecA,vecB.T)/((linalg.norm(vecA)*linalg.norm(vecB))+self.eps))[0,0]
# 映射
def project(self,XI):
if self.mu is None: return np.dot(XI,self.eig_vect)
return np.dot(XI-self.mu, self.eig_vect)
#预测最接近的特征脸
def predict(self,XI):
minDist = np.finfo('float').max
minClass = -1
Q = self.project(XI.reshape(1,-1))
for i in xrange(len(self.projections)):
dist = self.dist_metric(self.projections[i], Q)
if dist < minDist:
minDist = dist
minClass = self.y[i]
return minClass
# 生成特征脸
def subplot(self,title, images):
fig = plt.figure()
fig.text(.5, .95, title, horizontalalignment='center')
for i in xrange(len(images)):
ax0 = fig.add_subplot(4,4,(i+1))
plt.imshow(asarray(images[i]), cmap="gray")
plt.xticks([]), plt. yticks([]) # 隐藏 X Y 坐标
plt.show()
# 归一化
def normalize(self, X, low, high, dtype=None):
X = np.asarray(X)
minX, maxX = np.min(X), np.max(X)
X = X - float(minX)
X = X / float((maxX - minX))
X = X * (high-low)
X = X + low
if dtype is None:
return np.asarray(X)
return np.asarray(X, dtype=dtype)
'''
# 重构
def reconstruct(self,W, Y, mu=None):
if mu is None: return np.dot(Y,W.T)
return np.dot(Y, W.T) + mu
# 从外部数据计算投影
def out_project(self,W,XI,mu):
if mu is None: return np.dot(XI,W)
return np.dot(XI-mu, W)
'''
生成特征脸:
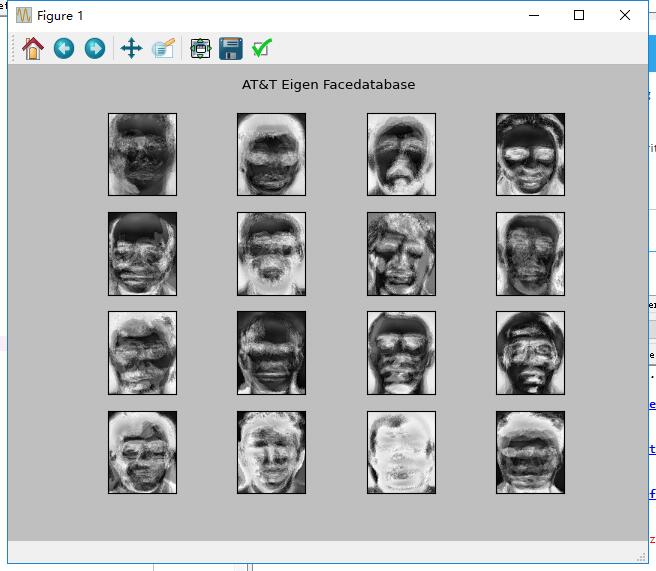
代码:
# -*- coding: utf-8 -*-
from numpy import *
import sys,os
from pca import *
reload(sys)
sys.setdefaultencoding('utf-8')
ef = Eigenfaces()
ef.dist_metric=ef.distEclud
ef.loadimgs("orl_faces/")
ef.compute()
E = []
X = mat(zeros((10,10304)))
for i in xrange(16):
X = ef.Mat[i*10:(i+1)*10,:].copy()
# X = ef.normalize(X.mean(axis =0),0,255)
X = X.mean(axis =0)
imgs = X.reshape(112,92)
E.append(imgs)
ef.subplot(title="AT&T Eigen Facedatabase", images=E)
执行人脸识别:
from numpy import *
import sys,os
from pca import *
reload(sys)
sys.setdefaultencoding('utf-8')
ef = Eigenfaces()
ef.dist_metric=ef.distEclud
ef.loadimgs("orl_faces/")
ef.compute()
# 创建测试集
testImg = ef.X[30]
print "实际值 =", ef.y[30], "->", "预测值 =",ef.predict(testImg)
待续。。。
代码下载:
参考文献
机器学习算法原理与编程实践















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









