





本文未经允许禁止转载,谢谢合作。
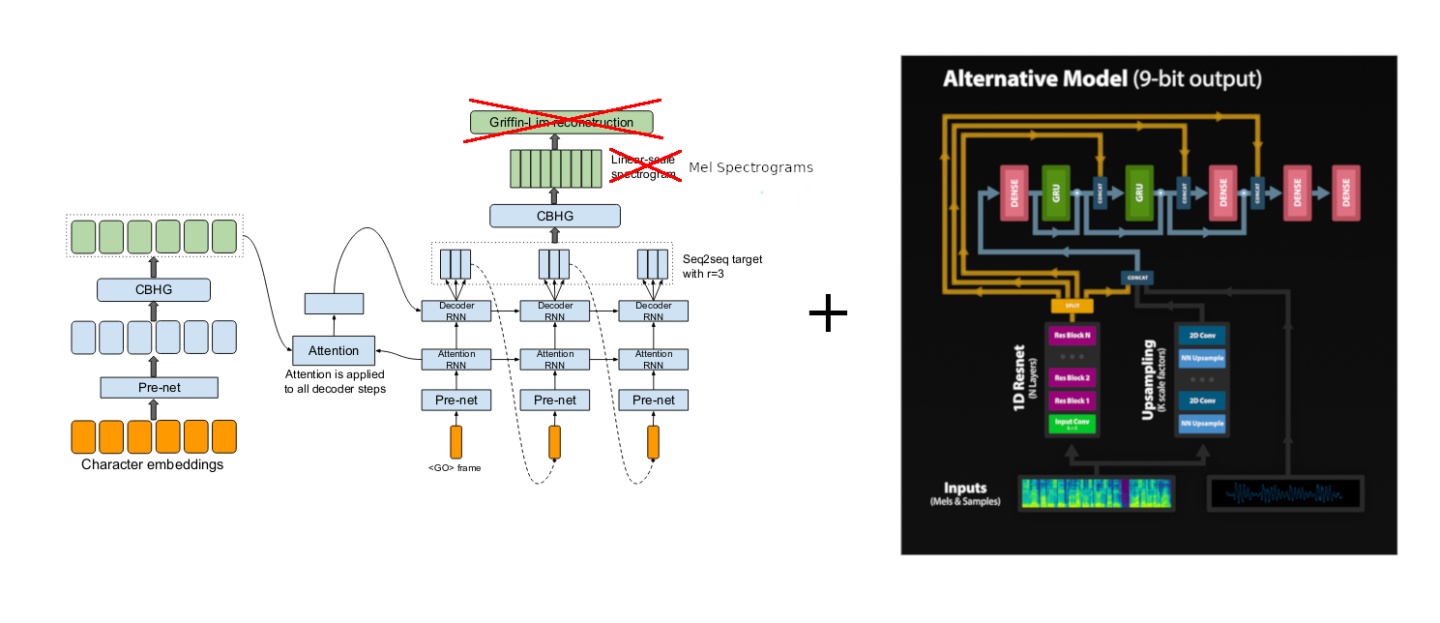
今天我将介绍目前最流行的Neural Vocoder模型WaveRNN。我们之前介绍过WaveNet,它现在一般作为Tacotron的Vocoder来合成音频,且可以生成非常高质量的音频,然而WaveNet是一个十分复杂且深度的模型,这个性质让WaveNet几乎不可能应用在实际应用场景中,而WaveRNN最初的设计目标就是在保持WaveNet高速序列生成,作者使用简化模型、稀疏化、并行序列生成等技术显著提升了序列生成速度,其良好的表现甚至可以在CPU上实现实时语音合成。
1. Introduction
序列模型在文字和语音领域的任务中都有较好的结果,但是如何更快速地进行采样仍然是一个比较困难的问题。
序列模型的生成时间是序列长度和生成每个token的时间的乘积,生成每个token的时间可以被进一步分解为所有计算操作所需要的时间的和,每个计算操作的时间可以被分解为computation time 和 overhead(可以理解为初始化开销),用数学公式表达就是:
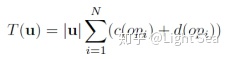
比如对于TTS来说,序列长度|u|就非常大,复杂的模型比如WaveNet,它的计算操作数量N也非常大。
上面的式子为我们提升效率提供了线索,我们可以通过:(1)降低模型的计算数量(减少N),(2)选择更适合GPU计算的operation(减少d),(3)减少权重数量(减少c),(4)同时生成多个token(减少序列长度)等方法来减少计算时间。
作者将焦点放在TTS上,从上述四个方面着手,提出了一系列通用的减少采样时间并维持高质量的方法。作者命名模型为WaveRNN,其质量和WaveNet几乎相同,且速度可以比WaveNet快4倍。
另外,作者也使用weight pruning technique来减少WaveRNN中的weight数量。作者发现在参数数量固定的情况下,大的稀疏网络表现地比小的紧密网络要好。稀疏的WaveRNN甚至可以在CPU上生成高质量实时音频。
最后,作者还提出了一个新的基于subscaling的生成方案,这个方案把长序列折叠成多个短序列,从而可以一次生成多个sample,这个subscale WaveRNN可以通过和一个orthogonal方法结合来增加采样效率。
结合上述所有改进得到的模型甚至可以在保持同等音频质量的情况下比WaveNet快10多倍。
2. WaveRNN
作者使用RNN来生成序列,计算公式为:
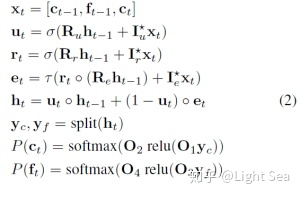
由于我们要生成16bit sequence,因此每个token都要生成16个bit,但是如果直接使用softmax则会有2^16个标签,因此作者把16bit分成两个部分,coarse和fine,即公式中的c和f,coarse是high 8-bit,fine是low 8-bit,这样就把输出空间缩小到2^8=256个值上。
由于f(t)的值依赖于c(t),所以必须先计算c(t),这里你可能会看不懂公式,为什么c(t)要作为生成c(t)的输入呢?其实作者把公式写成这样只是为了简便,矩阵I其实就是一个mask matrix,用来切断输入中c(t)和输出c(t)的一切连接。因此上述公式除了最后两个之外,其实都是要计算两遍的。
下图是它的图示:
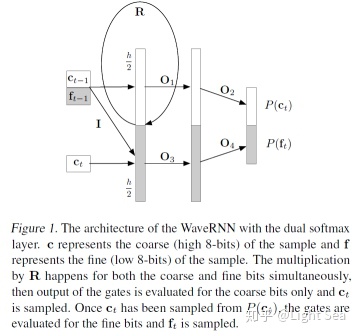
上述模型把N在WaveNet中的30减少到5。
另一个需要考虑的问题是,如何减少参数的装载时间?
作者针对它所进行实验的GPU型号(P100)设计了hidden units的个数896,使得所有参数都可以load到GPU的寄存器中,从而大幅度减少了overhead 时间(d),模型的速度达到了96000 samples/second。
3. Sparse WaveRNN
3.1 Weight Sparsification Method
我们可以进一步减少computation time c。最直接的方法就是减少隐藏层的大小,不过作者发现这样做会大幅度降低生成质量,因此作者选择减少模型中的non-zero weight,从而减少计算时间,同时也维持了模型的表达能力。这就是weight sparsification。
怎么做呢?作者使用了一种随着训练进行逐渐增加稀疏程度的方法。对每个参数矩阵维护一个binary mask,开始的时候binary mask为全1,训练每进行一段时间,就对参数矩阵的元素进行排序,然后把值最小的k个元素的mask设置为0。
k的计算需要考虑我们想要的稀疏度Z和矩阵中元素的总量,我们计算一个比例z,这个z乘上参数总量就是k的值,z的计算公式如下:
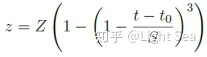
3.2 Structured Sparsity
我们还可以通过编码稀疏矩阵的方法来减少参数的存储消耗。
作者使用4x4 block作为单位来压缩矩阵,也就是说,原有的参数矩阵被压缩为多个4x4矩阵,这样binary mask的大小就可以缩小为原来的十六分之一,且不会损失表现。作者尝试的另一个结构是16x1 block,这种压缩方法只需要一个dot product就可以得到activation value,因此在效率上表现更好。
4. Subscale WaveRNN
如第1节所述,如果一次生成多个token,就可以减少序列长度,这里作者一次生成B个token,因此序列长度就缩小了B倍:

当然,这并不代表时间就缩短了B倍,因为该生成的还是要生成,但是同时生成多个token可以重复利用参数,因此还是加快了速度。
这种parallel generation面临的问题就是如何切断token之间的依赖。
我们首先列出同时生成B个token时的序列的概率依赖公式:
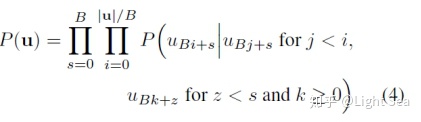
我们看到这个生成不是按照先后顺序生成的,前面的token也会依赖后面的token,但是作者认为,前面的token不会依赖太后面的token,即如果k > i + F,则这个依赖就没什么作用了,因此作者消除了这些依赖。
下图给出了作者算法的示意图:
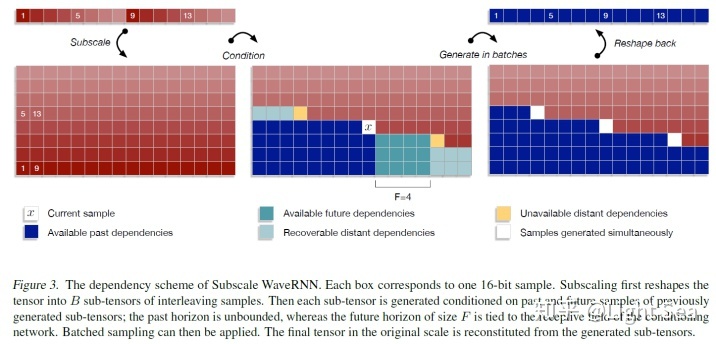
5. Experiment
首先是WaveRNN-896和其他模型的A/B test:
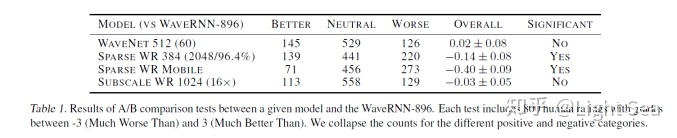
可以看到其表现几乎和WaveNet相当。这里模型后面的数字表示隐藏层大小,如果有SPARSE标注则数字表示隐藏层非零权重个数,括号中数字表示实际隐藏层大小,百分比表示sparse ratio。
然后是structure sparsity的影响:
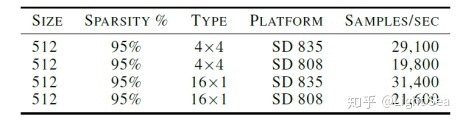
上表证实了我们之前提到的结论,即16x1的压缩方式要高效很多
接下来是sparsity ratio对NLL的影响:
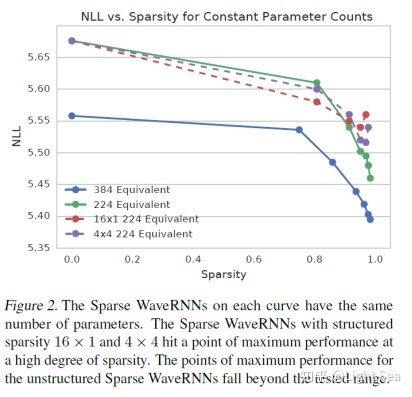
比较反直觉的一点是,模型越稀疏其表现却越好。
然后是不同模型和WaveNet的对比:
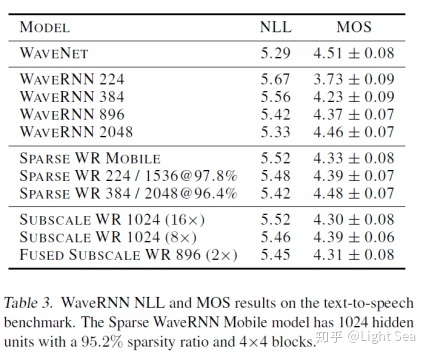
除了隐藏层比较小的dense模型,几乎都和WaveNet没有区别。
最后是模型的速度:

可以看到sparsity对模型的提速是很明显的。
6. Conclusion
本文我们介绍了WaveRNN模型和以及作者采用的各种加速技巧,其在序列生成加速上效果显著。实际上虽然WaveRNN在文章中被用来做TTS,但是我们不要忘记这是一个通用的序列生成模型,这就意味着它可以应用在各种序列生成任务中。另外虽然WaveRNN的作者没有开源其代码,但是已经有人给出了不错的实现,具体见fatchord/WaveRNN,有兴趣的同学可以看一看。
创作不易,如果大家觉得有收获的话烦请点赞收藏支持一下,你的支持就是我创作的最大动力。















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









