






1 为什么要优化显存
本文讨论的是使用tensorflow在GPU上的训练。
训练过程中大部分中间结果所占显存与batch_size成正比,除了参数的梯度是与参数一样大小,而前向计算中的卷积、矩阵乘法等操作的结果,以及反向计算时求Loss对各个操作结果的偏导,都是与batch_size成正比。在其它条件不变的情况下,当batch_size增大到一定程度就会导致OOM。如果减少了显存占用,就可能支持更大的batch_size。
增大batch_size有什么好处?一是某些强化学习的场景,样本空间非常大,增大batch_size可以使单次迭代处理的样本具有更大的多样性,提升训练效果。二是某些情况下可以增加样本吞吐量。
样本吞吐量也就是训练过程中单位时间内处理的样本数。训练加速的目标是为了让模型在更短的时间内收敛到指定的水平,而增加样本吞吐量是其中关键的一步。
为什么batch_size变大能增加样本吞吐量?一是某些计算op在batch_size变大时更高效,比如矩阵乘法,从而平均每个样本的计算时间变小。二是当额外通信占比较大时,随着batch_size变大,额外通信时间不变或者反而变小,从而平均每个样本的额外通信时间变小。
我们通常把训练的时间分为IO时间、计算时间和额外通信时间。IO时间一般可以通过样本预读优化到很小。额外通信时间指的是为了在GPU之间传输数据而增加的时间。为了减少额外通信时间以及增加多机扩展性,我们并不是把参数保存到固定一台机器的内存或者是一个GPU的显存,而是每个GPU的显存保存相同的参数,然后通过环形通信算法来保证参数的一致性。训练流程大概如下图所示,其中环形梯度规约就是通过环形通信算法求各GPU算出来的梯度的平均值。前向计算依赖于样本输入以及参数,反向计算依赖前向计算的结果以及参数,梯度规约依赖于反向计算的结果,但因为参数不止一个,所以可以用流水线的方式并行执行。反向计算的时间越长,梯度规约的时候越短,就越可能掩盖梯度规约的时间。
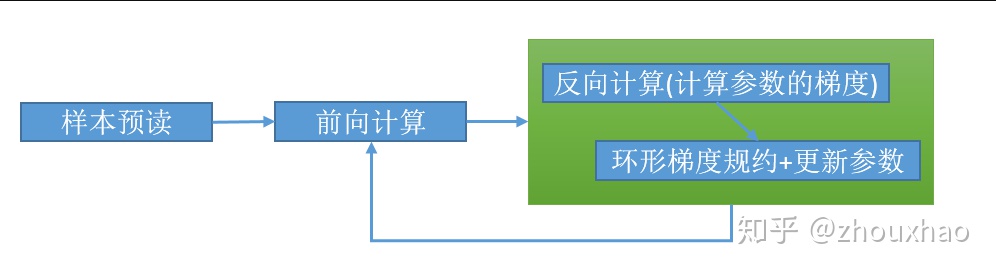
所以,优化显存的最终目的是提升训练效果和训练速度。
2 优化显存占用的原理
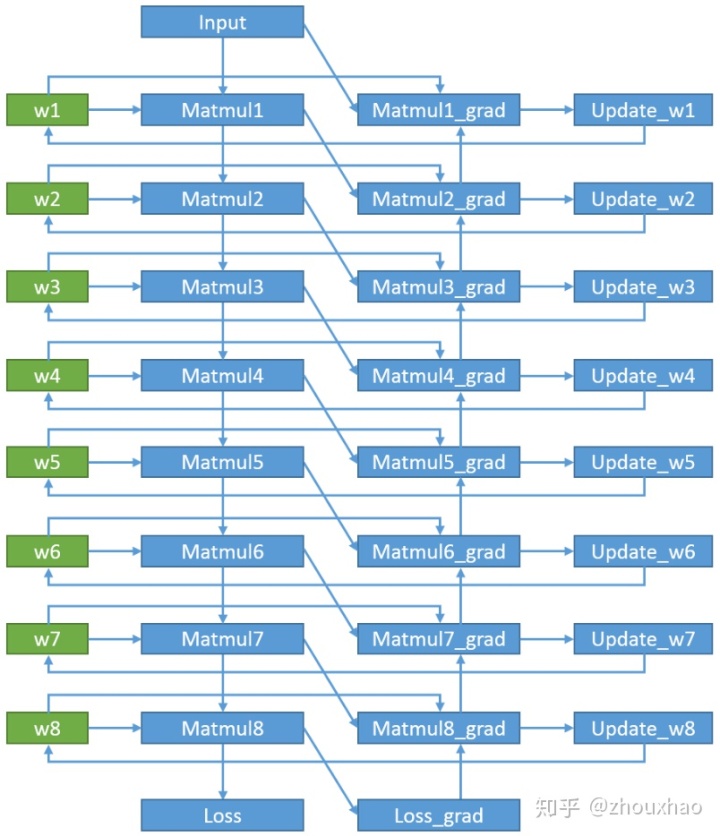
以一个简单的8层矩阵乘法的网络为例,正向计算和反向计算的依赖关系如下图所示。用户写好Matmul1, …, Matmul8, Loss的代码之后,就会生成前向计算那条路径,其中w1, ..., w8分别是Matmul1, ..., Matmul8的参数。调用tf.gradients(Loss, [w1, …, w8])之后,就会生成Matmul8_grad, …, Matmul1_grad那条路径。再调用opt.apply_gradients(list(zip(grads, params))),就会生成Update_w8, …, Update_w1那条路径。到此一个训练的图生成完毕。在单次迭代中,Matmul1, …, Matmul8的计算结果都被反向计算的OP所依赖,所以前向计算过程中不释放显存,要等到反向计算时相应的op计算完后再释放。
Tianqi Chen等人提出了 Saving memory using gradient-checkpointing 的方法,主要是以时间换空间,前向计算只保存部分计算结果,如下图中Matmul2和Matmul5的计算结果,其它的计算结果等到反向计算需要用到时再重新计算一次,从而使训练过程中显存得到重复利用,减少显存占用的峰值。
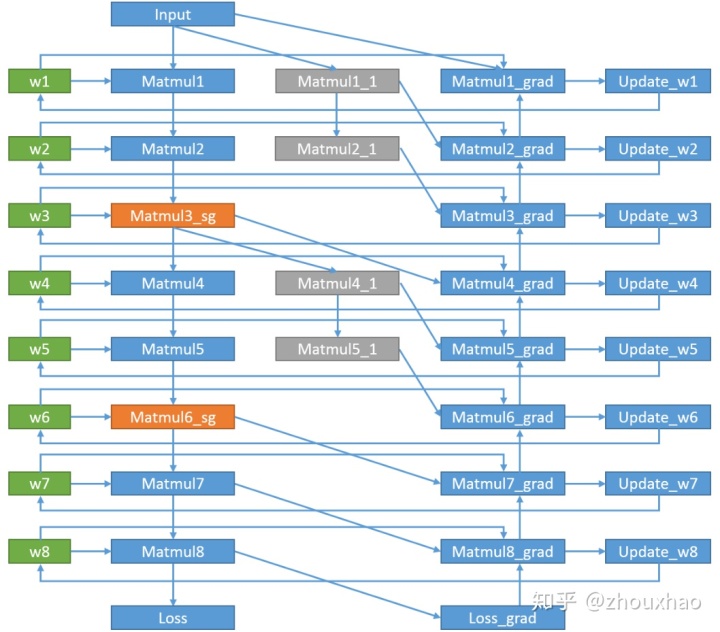
此方法是通过把反向计算分割成几个子图,每个子图里重新进行前向计算,显存占用的峰值就是各个子图的显存占用再加上未释放的checkpoint的大小的最大值。
3 实现方式
我们来看看如何用代码改变原有的网络。
3.1 选择保留的checkpoint
- 选择原来的Matmul3和Matmul6作为checkpoint,调用tf.stop_gradient,返回Matmul3_sg和Matmul6_sg
- 调用tf.contrib.graph_editor. reroute_ts替换成原来的Matmul3和Matmul6。
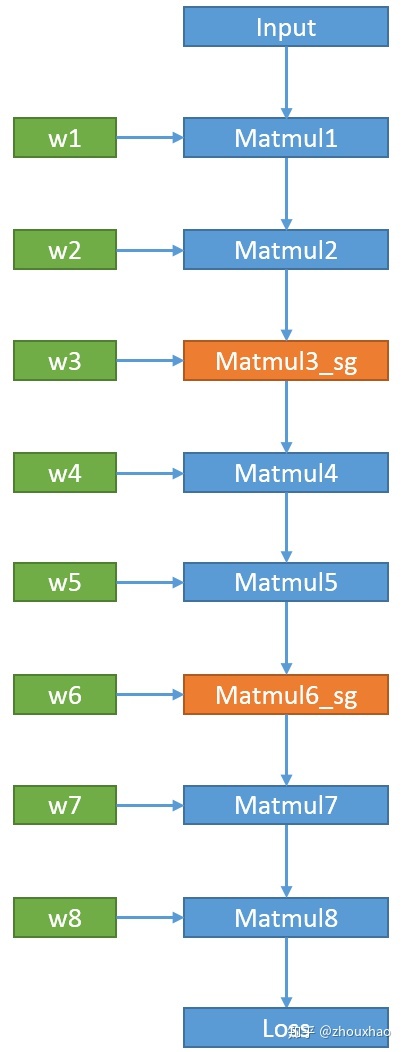
3.2 从Loss开始生成反向子图
- 调用tf.gradients(Loss, [w1, …, w8, Matmul6_sg])生成反向计算的路径,但遇到Matmul6_sg之后中止(这一步与gradient-checkpointing的实现有点不同,本人觉得没有必要复制一次前向计算的子图)。
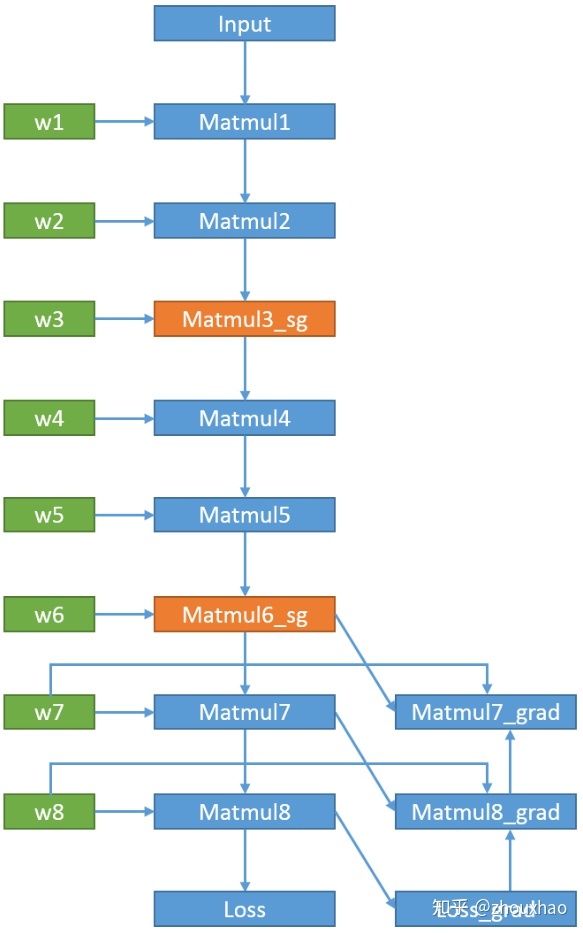
因为Matmul7是Matmul6_sg和w7两个矩阵相乘,所以Matmul7_grad里面其实包含两个op,Matmul7_grad/Matmul是求Loss对Matmul6_sg的偏导,而Matmul7_grad/Matmul_1是求Loss对w7的偏导,也就是w7的梯度。同理,Matmul8_grad/Matmul是求Loss对Matmul7的偏导。由链式求导法则得到
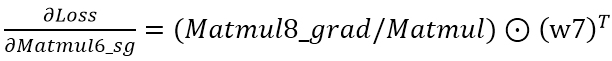
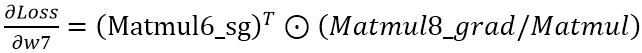
证明:
假设矩阵C等于A乘B,A是m行p列,B是p行n列,则C是m行n列。因为
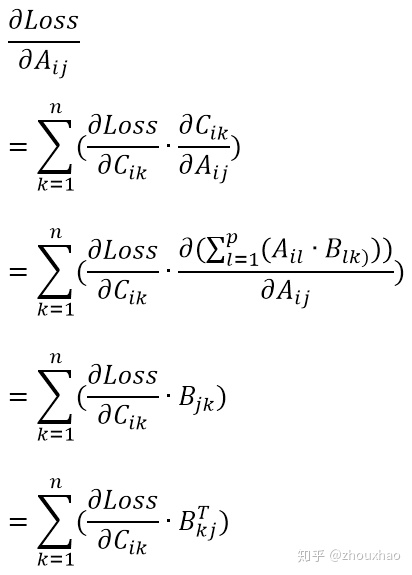
写成矩阵形式,就是
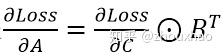
另外,因为
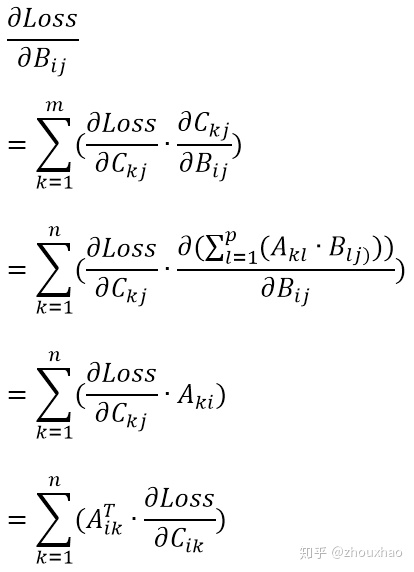
写成矩阵形式,就是
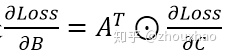
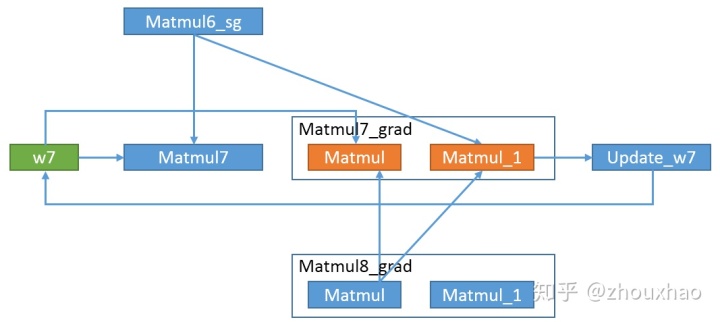
3.3 从Matmul7_grad/Matmul开始生成反向子图
- 调用tf.contrib.graph_editor. copy_with_input_replacements复制一个包含Matmul4_1、Matmul5_1和Matmul6_1的子图。
- 调用tf.contrib.graph_editor. add_control_inputs让Matmul4_1依赖于Matmul7_grad/Matmul,也就是Matmul4_1要等Matmul7_grad/Matmul计算完之后才可以开始计算,否则Matmul4_1和Matmul5_1就会提前开始计算,占用显存。
- 调用tf.gradients(Matmul6_1, [w1, …, w8, Matmul3_sg], grad_ys=Matmul7_grad/Matmul) 生成后续的反向计算路径。Matmul6_1因为不会计算,所以没画出来。

3.4 从Matmul4_grad/Matmul开始生成反向子图
- 调用tf.contrib.graph_editor. copy_with_input_replacements复制一个包含Matmul1_1、Matmul2_1和Matmul3_1的子图。
- 调用tf.contrib.graph_editor. add_control_inputs让Matmul1_1依赖于Matmul4_grad/Matmul。
- 调用tf.gradients(Matmul3_1, [w1, …, w8], grad_ys=Matmul4_grad/Matmul) 生成后续的反向计算路径。Matmul3_1因为不会计算,所以没画出来。

4 什么情况可以用此方法加速
- 网络层数够多,才能够节省更多显存。
- 前向计算的中间结果比参数大,因为参数是常驻显存不释放的,同时参数的梯度与参数同样大小,而可节省的显存只是前向计算中那些提前释放的中间结果。另外如果采用环形梯度规约时,参数的梯度会被延后释放,从而占用更多显存。
- 参数足够大,额外通信占比才足够大,增大batch_size才能够增加足够的样本吞吐量,抵消多出来的前向计算花费的时间。
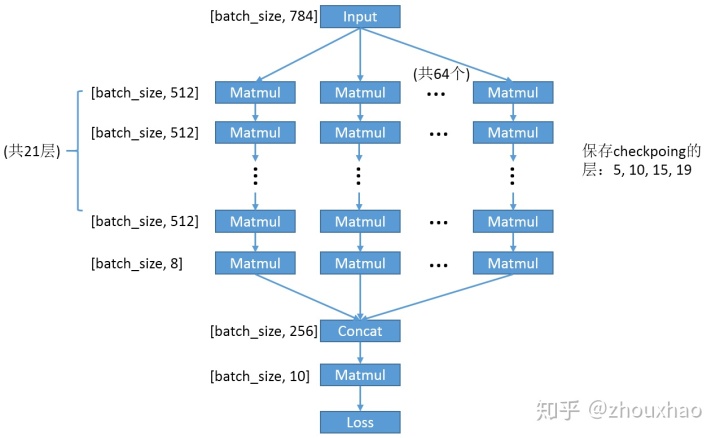
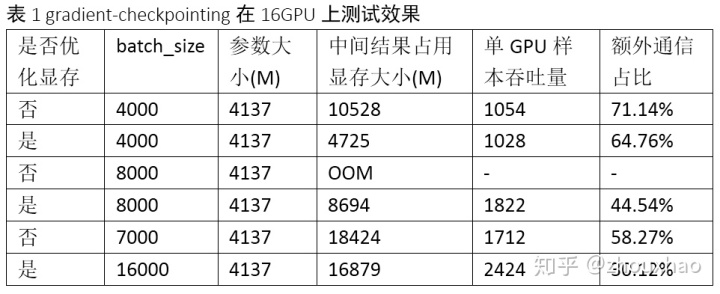
以mnist为例,因为正常单GPU跑几个epoch的训练样本就可以把准确率训练到99%,这里只是用mnist的数据来进行测试,设计的网络也只是为了验证节省显存能否带来训练速度的提升。训练的网络如下图所示,输入为大小为[batch_size, 784]的训练样本。接着分成64路并行计算,每一路是22个 Matmul计算,其中前21个的输出为[batch_size, 512],最后一个为[batch_size, 8]。然后64路用Concat合成一路,再经过一个Matmul,最后算出Loss。训练时占用显存最大的就是那21层Matmul,采用gradient-checkpointing方法,保存checkpoint的层是第5、10、15、19层,在两台G9机器(P40*16,24G显存)上的测试结果表1所示。在显存限制下,经过显存优化后比原来快41.6%。其中优化器采用Adam,所以参数大小有三分之一是Matmul所用(可训练),另外三分之二是Adam所用(不可训练)。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









